Kafka Offset 1
Kafka Offset Storage
1.概述
目前,Kafka 官网最新版[0.10.1.1],已默认将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中。其实,早在 0.8.2.2 版本,已支持存入消费的 offset 到Topic中,只是那时候默认是将消费的 offset 存放在 Zookeeper 集群中。那现在,官方默认将消费的offset存储在 Kafka 的Topic中,同时,也保留了存储在 Zookeeper 的接口,通过 offsets.storage 属性来进行设置。
2.内容
其实,官方这样推荐,也是有其道理的。之前版本,Kafka其实存在一个比较大的隐患,就是利用 Zookeeper 来存储记录每个消费者/组的消费进度。虽然,在使用过程当中,JVM帮助我们完成了自一些优化,但是消费者需要频繁的去与 Zookeeper 进行交互,而利用ZKClient的API操作Zookeeper频繁的Write其本身就是一个比较低效的Action,对于后期水平扩展也是一个比较头疼的问题。如果期间 Zookeeper 集群发生变化,那 Kafka 集群的吞吐量也跟着受影响。
在此之后,官方其实很早就提出了迁移到 Kafka 的概念,只是,之前是一直默认存储在 Zookeeper集群中,需要手动的设置,如果,对 Kafka 的使用不是很熟悉的话,一般我们就接受了默认的存储(即:存在 ZK 中)。在新版 Kafka 以及之后的版本,Kafka 消费的offset都会默认存放在 Kafka 集群中的一个叫 __consumer_offsets 的topic中。
当然,其实她实现的原理也让我们很熟悉,利用 Kafka 自身的 Topic,以消费的Group,Topic,以及Partition做为组合 Key。所有的消费offset都提交写入到上述的Topic中。因为这部分消息是非常重要,以至于是不能容忍丢数据的,所以消息的 acking 级别设置为了 -1,生产者等到所有的 ISR 都收到消息后才会得到 ack(数据安全性极好,当然,其速度会有所影响)。所以 Kafka 又在内存中维护了一个关于 Group,Topic 和 Partition 的三元组来维护最新的 offset 信息,消费者获取最新的offset的时候会直接从内存中获取。
3.实现
那我们如何实现获取这部分消费的 offset,我们可以在内存中定义一个Map集合,来维护消费中所捕捉到 offset,如下所示:
protected static Map<GroupTopicPartition, OffsetAndMetadata> offsetMap = new ConcurrentHashMap<>();
然后,我们通过一个监听线程来更新内存中的Map,代码如下所示:

private static synchronized void startOffsetListener(ConsumerConnector consumerConnector) {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(consumerOffsetTopic, new Integer(1));
KafkaStream<byte[], byte[]> offsetMsgStream = consumerConnector.createMessageStreams(topicCountMap).get(consumerOffsetTopic).get(0);
ConsumerIterator<byte[], byte[]> it = offsetMsgStream.iterator();
while (true) {
MessageAndMetadata<byte[], byte[]> offsetMsg = it.next();
if (ByteBuffer.wrap(offsetMsg.key()).getShort() < 2) {
try {
GroupTopicPartition commitKey = readMessageKey(ByteBuffer.wrap(offsetMsg.key()));
if (offsetMsg.message() == null) {
continue;
}
OffsetAndMetadata commitValue = readMessageValue(ByteBuffer.wrap(offsetMsg.message()));
offsetMap.put(commitKey, commitValue);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
在拿到这部分更新后的offset数据,我们可以通过 RPC 将这部分数据共享出去,让客户端获取这部分数据并可视化。RPC 接口如下所示:
namespace java org.smartloli.kafka.eagle.ipc
service KafkaOffsetServer{
string query(1:string group,2:string topic,3:i32 partition),
string getOffset(),
string sql(1:string sql),
string getConsumer(),
string getActiverConsumer()
}
这里,如果我们不想写接口来操作 offset,可以通过 SQL 来操作消费的 offset 数组,使用方式如下所示:
- 引入依赖JAR
<dependency>
<groupId>org.smartloli</groupId>
<artifactId>jsql-client</artifactId>
<version>1.0.0</version>
</dependency>
- 使用接口
JSqlUtils.query(tabSchema, tableName, dataSets, sql);
tabSchema:表结构;tableName:表名;dataSets:数据集;sql:操作的SQL语句。
4.预览
消费者预览如下图所示:
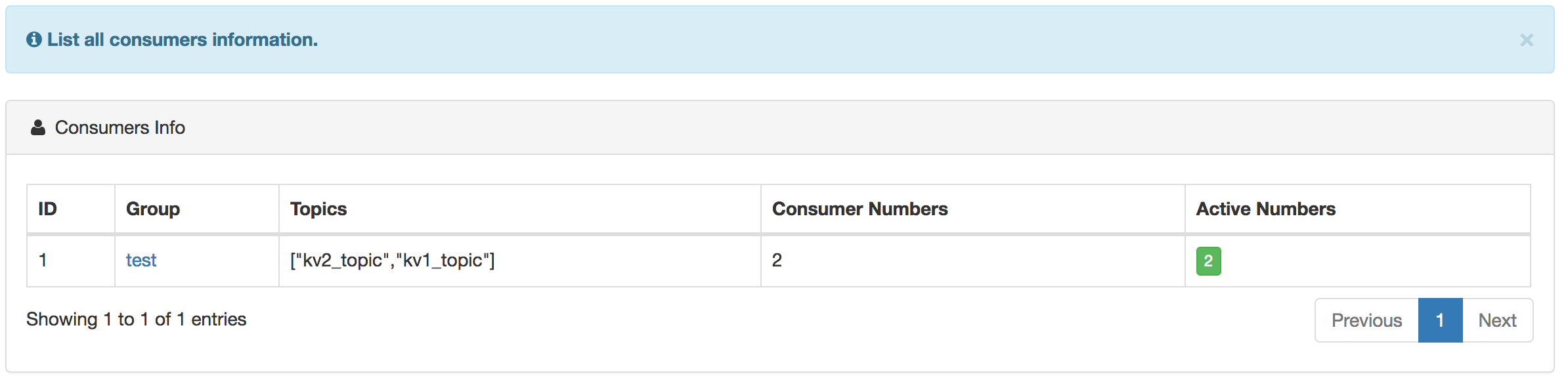
正在消费的关系图如下所示:

消费详细 offset 如下所示:

消费和生产的速率图,如下所示:

5.总结
这里,说明一下,当 offset 存入到 Kafka 的topic中后,消费线程ID信息并没有记录,不过,我们通过阅读Kafka消费线程ID的组成规则后,可以手动生成,其消费线程ID由:Group+ConsumerLocalAddress+Timespan+UUID(8bit)+PartitionId,由于消费者在其他节点,我们暂时无法确定ConsumerLocalAddress。最后,欢迎大家使用 Kafka 集群监控 ——[ Kafka Eagle ],[ 操作手册 ]。
Kafka Offset 1的更多相关文章
- Kafka Offset相关命令总结
Kafka Offset相关命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查询topic的offset的范围 1>.查询某个topic的offset的最小值 [ ...
- kafka集群监控工具之三--kafka Offset Monitor
1.介绍 一般情况下,功能简单的kafka项目 使用运维命令+kafka Offset Monitor 就足够用了. 2.使用2.1 部署 github下载jar包 KafkaOffsetMonit ...
- Kafka Offset Storage
1.概述 目前,Kafka 官网最新版[0.10.1.1],已默认将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中.其实,早在 0.8.2. ...
- kafka offset 设置
from kafka import KafkaConsumer from kafka import TopicPartition from kafka.structs import OffsetAnd ...
- 关于 Kafka offset
查询topic的offset的范围 用下面命令可以查询到topic:Mytopic broker:SparkMaster:9092的offset的最小值: bin/kafka-run-class.sh ...
- Spark createDirectStream 维护 Kafka offset(Scala)
createDirectStream方式需要自己维护offset,使程序可以实现中断后从中断处继续消费数据. KafkaManager.scala import kafka.common.TopicA ...
- kafka offset的存储问题
注意:从kafka-0.9版本及以后,kafka的消费者组和offset信息就不存zookeeper了,而是存到broker服务器上,所以,如果你为某个消费者指定了一个消费者组名称(group.id) ...
- using kafkacat reset kafka offset
1. install kafkacat Ubuntu apt-get install kafkacat CentOS install deepenency yum install librdkafka ...
- kafka offset存储
存储方式 方式 方式来源 存储位置 自动提交 kafka kafka 异步提交 kafka kafka checkpoint spark streaming hdfs hbase存储 程序开发 hba ...
随机推荐
- [Nuxt] Build a Navigation Component in Vue.js and Use in a Nuxt Layout
You can isolate parts of templates you want to re-use into components, but you can also reuse those ...
- TreeView控件的展开与折叠
在窗体中添加一个TreeView控件,设置CheckBox属性为True,绑定数据 Archive jkj = new Archive();//自定义类 public void Bind ...
- 一段代码的疑问(1)——unsigned与signed
现象: 先来看一段代码: 这段代码的输出结果是: -84 4294967264 分析: xiaoqiang@dev:~/cpp$ g++ -g c212.cc -o temp xiaoqiang@de ...
- hdu 2577 How to Type(DP)
How to Type Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Tota ...
- Android多线程研究(7)——Java5中的线程并发库
从这一篇开始我们将看看Java 5之后给我们添加的新的对线程操作的API,首先看看api文档: java.util.concurrent包含许多线程安全.测试良好.高性能的并发构建块,我们先看看ato ...
- ENVI显示GDAL创建GeoTiff文件的一个问题及其思考
作者:朱金灿 来源:http://blog.csdn.net/clever101 使用gdal创建一个100*100的红色的geotiff图像,代码如下: #include <assert.h& ...
- 手动打war包进行部署测试
有的时候项目跑不起来但是又不知道tomcat问题还是其他问题,往往新建个项目,打成war进行部署.今天找到个好方法,手动打成war,然后进行部署测试. image.png image.png 创建一个 ...
- Android 动态改变高度以及计算长度的EditText
前段时间项目需求,需要做一个有限制长度的输入框并动态显示剩余文字,同时也要动态改变EditText的高度来增加用户体验.现整理出来与大家分享. 先来看看效果图 看了效果就分享一下布局 <Rela ...
- Android EditText文本内容变化监听方法
package com.google; import android.app.Activity; import android.os.Bundle; import android.text.Edita ...
- [React] Use React.cloneElement to Extend Functionality of Children Components
We can utilize React.cloneElement in order to create new components with extended data or functional ...