Python数据分析----scipy稀疏矩阵
一、sparse模块:
python中scipy模块中,有一个模块叫sparse模块,就是专门为了解决稀疏矩阵而生。本文的大部分内容,其实就是基于sparse模块而来的
导入模块:from scipy import sparse
二、七种矩阵类型
- coo_matrix
- dok_matrix
- lil_matrix
- dia_matrix
- csr_matrix
- csc_matrix
- bsr_matrix
三、coo_matrix
coo_matrix是最简单的存储方式。采用三个数组row、col和data保存非零元素的信息。这三个数组的长度相同,row保存元素的行,col保存元素的列,data保存元素的值。一般来说,coo_matrix主要用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改等操作,一旦矩阵创建成功以后,会转化为其他形式的矩阵。data = [5,2,3,0]
>>> row = [2,2,3,2]
>>> col = [3,4,2,3]
>>> c = sparse.coo_matrix((data,(row,col)),shape=(5,6))
>>> print c.toarray()
[[0 0 0 0 0 0]
[0 0 0 0 0 0]
[0 0 0 5 2 0]
[0 0 3 0 0 0]
[0 0 0 0 0 0]]
稍微需要注意的一点是,用coo_matrix创建矩阵的时候,相同的行列坐标可以出现多次。矩阵被真正创建完成以后,相应的坐标值会加起来得到最终的结果。
四、dok_matrix与lil_matrix
dok_matrix和lil_matrix适用的场景是逐渐添加矩阵的元素。
doc_matrix的策略是采用字典来记录矩阵中不为0的元素。自然,字典的key存的是记录元素的位置信息的元祖,value是记录元素的具体值。
>>> import numpy as np
>>> from scipy.sparse import dok_matrix
>>> S = dok_matrix((5, 5), dtype=np.float32)
>>> for i in range(5):
... for j in range(5):
... S[i, j] = i + j
...
>>> print S.toarray()
[[ 0. 1. 2. 3. 4.]
[ 1. 2. 3. 4. 5.]
[ 2. 3. 4. 5. 6.]
[ 3. 4. 5. 6. 7.]
[ 4. 5. 6. 7. 8.]]
lil_matrix则是使用两个列表存储非0元素。data保存每行中的非零元素,rows保存非零元素所在的列。这种格式也很适合逐个添加元素,并且能快速获取行相关的数据。
>>> from scipy.sparse import lil_matrix
>>> l = lil_matrix((6,5))
>>> l[2,3] = 1
>>> l[3,4] = 2
>>> l[3,2] = 3
>>> print l.toarray()
[[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 1. 0.]
[ 0. 0. 3. 0. 2.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]
>>> print l.data
[[] [] [1.0] [3.0, 2.0] [] []]
>>> print l.rows
[[] [] [3] [2, 4] [] []]
五、dia_matrix
这是一种对角线的存储方式。其中,列代表对角线,行代表行。如果对角线上的元素全为0,则省略。
如果原始矩阵是个对角性很好的矩阵那压缩率会非常高。
找了网络上的一张图,大家就很容易能看明白其中的原理。

六、csr_matrix与csc_matrix
csr_matrix,全名为Compressed Sparse Row,是按行对矩阵进行压缩的。CSR需要三类数据:数值,列号,以及行偏移量。CSR是一种编码的方式,其中,数值与列号的含义,与coo里是一致的。行偏移表示某一行的第一个元素在values里面的起始偏移位置。
同样在网络上找了一张图,能比较好反映其中的原理。
以官方文档为例,此时data代表的是存储的值的数组,indices代表的是每一行中第几列有对应data中的元素,即从indices中可以推断出列的信息,
indptr则用来推断出行的信息,默认元素开始为0,第一个元素为2,则证明第一行中有2-0=2个元素,所以将data数组中前另个元素写入第一行中,而indices前两个元素为0,2,则代表第0列和第2列。前两第二个元素为3,证明第二行中有3-2=1个元素,该元素为data[2]=3,且存储在indices[2] = 2列中。依次类推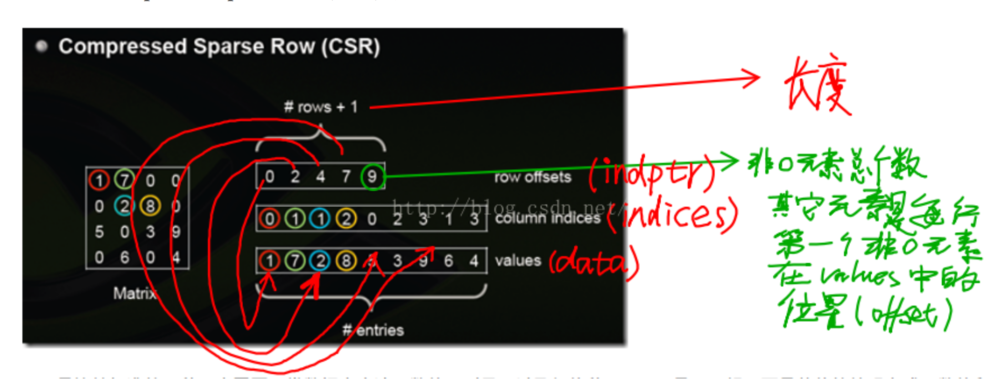
>>> from scipy.sparse import csr_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
不难看出,csr_matrix比较适合用来做真正的矩阵运算。
至于csc_matrix,跟csr_matrix类似,只不过是基于列的方式压缩的,不再单独介绍。
七、bsr_matrix
按分块的思想对矩阵进行压缩。

摘自:https://blog.csdn.net/bitcarmanlee/article/details/52668477
Python数据分析----scipy稀疏矩阵的更多相关文章
- python数据分析scipy和matplotlib(三)
Scipy 在numpy基础上增加了众多的数学.科学及工程常用的库函数: 线性代数.常微分方程求解.信号处理.图像处理.稀疏矩阵等: Matplotlib 用于创建出版质量图表的绘图工具库: 目的是为 ...
- python数据分析01准备工作
第1章 准备工作 1.1 本书的内容 本书讲的是利用Python进行数据控制.处理.整理.分析等方面的具体细节和基本要点.我的目标是介绍Python编程和用于数据处理的库和工具环境,掌握这些,可以让你 ...
- Python数据分析基础教程
Python数据分析基础教程(第2版)(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1_FsReTBCaL_PzKhM0o6l0g 提取码:nkhw 复制这段内容后 ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- python数据分析实用小抄
1. python数据分析基础 2. numpy 3. Scikit-Learn 4. Bokeh 5. Scipy 6. Pandas 转载于:http://www.jianshu.com/p/ ...
- Python数据分析入门
Python数据分析入门 最近,Analysis with Programming加入了Planet Python.作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析.具体内 ...
- KNIME + Python = 数据分析+报表全流程
Python 数据分析环境 数据分析领域有很多可选方案,例如SPSS傻瓜式分析工具,SAS专业性商业分析工具,R和python这类需要代码编程类的工具.个人选择是python这类,包括pandas,n ...
- python数据分析Numpy(二)
Numpy (Numerical Python) 高性能科学计算和数据分析的基础包: ndarray,多维数组(矩阵),具有矢量运算能力,快速.节省空间: 矩阵运算,无需循环,可以完成类似Matlab ...
随机推荐
- Android:创建无标题栏的Activity
上图是一个带标题栏的Activity.有些时候我们希望能去除这个标题栏,做法如下: 1. 在res/values目录下面创建styles.xml.如果你已经有这个文件了,那么直接打开这个文件,添加如下 ...
- 任务调度分配题两道 POJ 1973 POJ 1180(斜率优化复习)
POJ 1973 这道题以前做过的.今儿重做一次.由于每个程序员要么做A,要么做B,可以联想到0/1背包(谢谢N巨).这样,可以设状态 dp[i][j]为i个程序员做j个A项目同时,最多可做多少个B项 ...
- 在centos7上安装DSPC
感谢朋友支持本博客.欢迎共同探讨交流,因为能力和时间有限.错误之处在所难免,欢迎指正! 假设转载,请保留作者信息. 博客地址:http://blog.csdn.net/qq_21398167 原博文地 ...
- ORACLE11G设置IP訪问限制
出于数据安全考虑,对oracle数据库的IP做一些限制,仅仅有固定的IP才干訪问. 改动$JAVA_HOME/NETWORK/ADMIN/sqlnet.ora文件 添加下面内容(红色表示凝视): #开 ...
- [Fri 26 Jun 2015 ~ Thu 2 Jul 2015] Deep Learning in arxiv
Natural Neural Networks Google DeepMind又一神作 Projected Natural Gradient Descent algorithm (PRONG) bet ...
- 重学C++ (十一) OOP面向对象编程(2)
转换与继承 本节主要须要区分的是: 基类和派生类的转换: 引用(指针)的转换和对象的转换. 1.每一个派生类对象包括一个基类部分.因此.能够像使用基类对象一样在派生类对象上执行操作. 基于这一点,能够 ...
- json、js数组真心不是想得那么简单
之前因为做前台的东西比較少,对于json和js数组的认识仅局限于一种固定格式.这样的固定的思维在开发前台时,特别是近期使用highcharts插件时.让我感到特别不明确.通过查询最终心头的疙瘩解开了. ...
- 2014年辛星解读css第二节
第一节我们简单介绍了一下CSS的工作流程,我相信读者会有一个大体的认识,那么接下来我们将会深入的研究一下CSS的细节问题,这些问题的涉及将会使我们的工作更加完好. *************凝视*** ...
- HTML网页之计算器代码
计算器网页效果显示:点击这里! <script> function show(){ var date = new Date(); //日期对象 var now = "&qu ...
- SQL 优化记录
1. 对Where 语句的法则 1.1 避免在WHERE子句中使用in,not in,or 或者having. 可以使用 exist 和not exist代替 in和not in. 可以使用表链接代 ...