探索C#之微型MapReduce
MapReduce近几年比较热的分布式计算编程模型,以C#为例简单介绍下MapReduce分布式计算。
阅读目录
背景
某平行世界程序猿小张接到Boss一项任务,统计用户反馈内容中的单词出现次数,以便分析用户主要习惯。文本如下:
const string hamlet = @"Though yet of Hamlet our dear brother's death
The memory be green, and that it us befitted
To bear our hearts in grief and our whole kingdom
To be contracted in one brow of woe,
Yet so far hath discretion fought with nature
That we with wisest sorrow think on him,
Together with remembrance of ourselves.
Therefore our sometime sister, now our queen,
The imperial jointress to this warlike state,
Have we, as 'twere with a defeated joy,--
With an auspicious and a dropping eye,
With mirth in funeral and with dirge in marriage,
In equal scale weighing delight and dole,--
Taken to wife: nor have we herein barr'd
Your better wisdoms, which have freely gone
With this affair along. For all, our thanks.
Now follows, that you know, young Fortinbras,
Holding a weak supposal of our worth,
Or thinking by our late dear brother's death
Our state to be disjoint and out of frame,
Colleagued with the dream of his advantage,
He hath not fail'd to pester us with message,
Importing the surrender of those lands
Lost by his father, with all bonds of law,
To our most valiant brother. So much for him.
Now for ourself and for this time of meeting:
Thus much the business is: we have here writ
To Norway, uncle of young Fortinbras,--
Who, impotent and bed-rid, scarcely hears
Of this his nephew's purpose,--to suppress
His further gait herein; in that the levies,
The lists and full proportions, are all made
Out of his subject: and we here dispatch
You, good Cornelius, and you, Voltimand,
For bearers of this greeting to old Norway;
Giving to you no further personal power
To business with the king, more than the scope
Of these delated articles allow.
Farewell, and let your haste commend your duty.";
小张作为蓝翔高材生,很快就实现了:
var content = hamlet.Split(new[] { " ", Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries);
var wordcount=new Dictionary<string,int>();
foreach (var item in content)
{
if (wordcount.ContainsKey(item))
wordcount[item] += ;
else
wordcount.Add(item, );
}
作为有上进心的青年,小张决心对算法进行抽象封装,并支持多节点计算。小张把这个统计次数程序分成两个大步骤:分解和计算。
第一步:先把文本以某维度分解映射成最小独立单元。 (段落、单词、字母维度)。
第二部:把最小单元重复的做合并计算。
小张参考MapReduce论文设计Map、Reduce如下:
Map实现
Mapping
Mapping函数把文本分解映射key,value形式的最小单元,即<单词,出现次数(1)>、<word,1>。
public IEnumerable<Tuple<T, int>> Mapping(IEnumerable<T> list)
{
foreach (T sourceVal in list)
yield return Tuple.Create(sourceVal, );
}
使用,输出为(brow, 1), (brow, 1), (sorrow, 1), (sorrow, 1):
var spit = hamlet.Split(new[] { " ", Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries);
var mp = new MicroMapReduce<string>(new Master<string>());
var result= mp.Mapping(spit);
Combine
为了减少数据通信开销,mapping出的键值对数据在进入真正的reduce前,进行重复键合并。也相对于提前进行预计算一部分,加快总体计算速度。 输出格式为(brow, 2), (sorrow, 2):
public Dictionary<T, int> Combine(IEnumerable<Tuple<T, int>> list)
{
Dictionary<T, int> dt = new Dictionary<T, int>();
foreach (var val in list)
{
if (dt.ContainsKey(val.Item1))
dt[val.Item1] += val.Item2;
else
dt.Add(val.Item1, val.Item2);
}
return dt;
}
Partitioner
Partitioner主要用来分组划分,把不同节点的统计数据按照key进行分组。
其输出格式为: (brow, {(brow,2)},(brow,3)), (sorrow, {(sorrow,10)},(brow,11)):
public IEnumerable<Group<T, int>> Partitioner(Dictionary<T, int> list)
{
var dict = new Dictionary<T, Group<T, int>>();
foreach (var val in list)
{
if (!dict.ContainsKey(val.Key))
dict[val.Key] = new Group<T, int>(val.Key);
dict[val.Key].Values.Add(val.Value);
}
return dict.Values;
}
Group定义:
public class Group<TKey, TValue> : Tuple<TKey, List<TValue>>
{
public Group(TKey key)
: base(key, new List<TValue>())
{
} public TKey Key
{
get
{
return base.Item1;
}
} public List<TValue> Values
{
get
{
return base.Item2;
}
}
}
Reduce实现
Reducing函数接收,分组后的数据进行最后的统计计算。
public Dictionary<T, int> Reducing(IEnumerable<Group<T, int>> groups)
{
Dictionary<T, int> result=new Dictionary<T, int>();
foreach (var sourceVal in groups)
{
result.Add(sourceVal.Key, sourceVal.Values.Sum());
}
return result;
}
封装调用如下:
public IEnumerable<Group<T, int>> Map(IEnumerable<T> list)
{
var step1 = Mapping(list);
var step2 = Combine(step1);
var step3 = Partitioner(step2);
return step3;
} public Dictionary<T, int> Reduce(IEnumerable<Group<T, int>> groups)
{
var step1 = Reducing(groups);
return step1;
}
public Dictionary<T, int> MapReduce(IEnumerable<T> list)
{
var map = Map(list);
var reduce = Reduce(map);
return reduce;
}
整体计算步骤图如下:
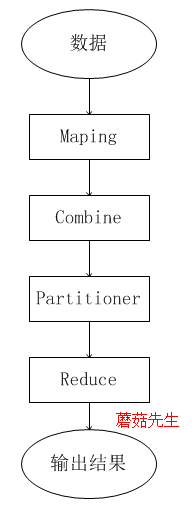
支持分布式
小张抽象封装后,虽然复杂度上去了。但暴露给使用者是非常清晰的接口,满足MapReduce的数据格式要求,即可使用。
var spit = hamlet.Split(new[] { " ", Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries);
var mp = new MicroMapReduce<string>(new Master<string>());
var result1= mp.MapReduce(spit);
小张完成后脑洞大开,考虑到以后文本数据量超大。 所以fork了个分支,准备支持分布式计算,以后可以在多个服务器节点跑。
数据分片
数据分片就是把大量数据拆成一块一块的,分散到各个节点上,方便我们的mapReduce程序去计算。 分片主流的有mod、consistent hashing、vitual Buckets、Range Partition等方式。 关于consistent hashing上篇有介绍(探索c#之一致性Hash详解)。在Hadoop中Hdfs和mapreduce是相互关联配合的,一个存储和一个计算。如果自行实现的话还需要个统一的存储。所以这里的数据源可以是数据库也可以是文件。小张只是满足boss需求,通用计算框架的话可以直接用现成的。
模拟分片
public List<IEnumerable<T>> Partition(IEnumerable<T> list)
{
var temp =new List<IEnumerable<T>>();
temp.Add(list);
temp.Add(list);
return temp;
}
Worker节点
小张定义了Master,worker角色。 master负责汇集输出,即我们的主程序。 每一个worker我们用一个线程来模拟,最后输出到master汇总,master最后可以写到数据库或其他。
public void WorkerNode(IEnumerable<T> list)
{
new Thread(() =>
{
var map = Map(list);
var reduce = Reduce(map);
master.Merge(reduce);
}).Start();
}
public class Master<T>
{
public Dictionary<T, int> Result = new Dictionary<T, int>();
public void Merge(Dictionary<T, int> list)
{
foreach (var item in list)
{
lock (this)
{
if (Result.ContainsKey(item.Key))
Result[item.Key] += item.Value;
else
Result.Add(item.Key, item.Value);
}
}
}
}
分布式计算步骤图:

总结
MapReduce模型从性能速度来说并不是非常好的,它优势在于隐藏了分布式计算的细节、容灾错误、负载均衡及良好的编程API,包含HDFS、Hive等在内一整套大数据处理的生态框架体系。在数据量级不是很大的话,企业自行实现一套轻量级分布式计算会有很多优点,比如性能更好、可定制化、数据库也不需要导入导出。从成本上也节省不少,因为hadoop开发、运维、服务器都需要不少人力物力。
探索C#之微型MapReduce的更多相关文章
- 探索C#之系列目录导航
1. 探索c#之函数创建和闭包 2. 探索c#之尾递归编译器优化 3. 探索c#之不可变数据类型 4. 探索c#之递归APS和CPS 5. 探索c#之一致性Hash详解 6. 探索c#之微型MapRe ...
- hadoop面试100道收集(带答案)
1.列出安装Hadoop流程步骤 a) 创建hadoop账号 b) 更改ip c) 安装Java 更改/etc/profile 配置环境变量 d) 修改host文件域名 e) 安装ssh 配置无密码登 ...
- 化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- Hadoop 之 深入探索MapReduce
1.MapReduce基础概念 答:MapReduce作业时一种大规模数据的并行计算的便程模型.我们可以将HDFS中存储的海量数据,通过MapReduce作业进行计算,得到目标数据. 2.MapRed ...
- 关于MapReduce中自定义分区类(四)
MapTask类 在MapTask类中找到run函数 if(useNewApi){ runNewMapper(job, splitMetaInfo, umbilical, reporter ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- 在eclipse中用gradle搭建MapReduce项目
我用的系统是ubuntu14.04新建一个Java Project. 这里用的是gradle打包,gradle默认找src/main/java下的类编译.src目录已经有了,手动在src下创建main ...
- [翻译]MapReduce: Simplified Data Processing on Large Clusters
MapReduce: Simplified Data Processing on Large Clusters MapReduce:面向大型集群的简化数据处理 摘要 MapReduce既是一种编程模型 ...
随机推荐
- Etw EventSourceProvider_EventsProducer.cs OopConsoleTraceEventListenerMonitor_TraceControllerEventsConsumer.cs
// EventSourceProvider_EventsProducer.cs /* /r:"D:\Microshaoft.Nuget.Packages\Microsoft.Diagnos ...
- 统计java中字符串,数组,集合大小(长度)
字符串长度用String.length(); 数组用String[].length; 集合用collection.size();
- 学习微信小程序之css6
- 在CHROME里安装 VIMIUM 插件, 方便操作
VIMIUM 插件使用方法 VIMIUM 命令列表 网页导航 j, :向下滚动网页 k, :向上滚动网页 h : 向左滚动 l : 向右滚动 gg : 滚动到网页头部 G : 滚动到网页底部 :向上翻 ...
- 活动助手Beta用户试用报告
用户试用报告 1.面向参与者用户 1.1 日常参加各类学习(水综测)活动中,有没有遇到以下问题: (1) 信息来源混乱,不知道靠不靠谱 (2) 每次报名都要重新填写自己的学号手机号,有时候填错了就没综 ...
- c#比较两个List相等
1.if(ListA.Count == ListB.Count && ListA.Count(t => !ListB.Contains(c)) == 0) 数量相等,元素值相等即 ...
- 0421 & SX2016
山西省选...这个省...不算强吧...然而就是这么腊鸡题目还是wa得一无是处...怎么办啊怎么办啊...无处拯救青春和未来啊... T1: POI2004原题 BZOJ1524 n<=16.这 ...
- Ajax跨域问题的两种解决方法
浏览器不允许Ajax跨站请求,所以存在Ajax跨域问题,目前主要有两种办法解决. 1.在请求页面上使用Access-Control-Allow-Origin标头. 使用如下标头可以接受全部网站请求: ...
- PHP多级联动的学习(二)
首先我发现实现点击下拉框中的选项跳转传递信息的功能是需要javascript实现的.于是我把相应代码拷过来,把跳转的地址改掉.接着我发现无法 把<option value=''>中valu ...
- SqlServer windowss身份登陆和sa身份登陆
今天重新装了系统,但是计算机名变了,于是修改了计算机名,然后装了SQLSEVER,安装完成后登录,发现无论用WINDOWS身份还是SQLSERVER身份都登录不了 1.先说说sqlserver身份登录 ...