MapReduce 1工作原理图文详解
MapReduce工作原理图文详解
一 MapReduce程序执行流程
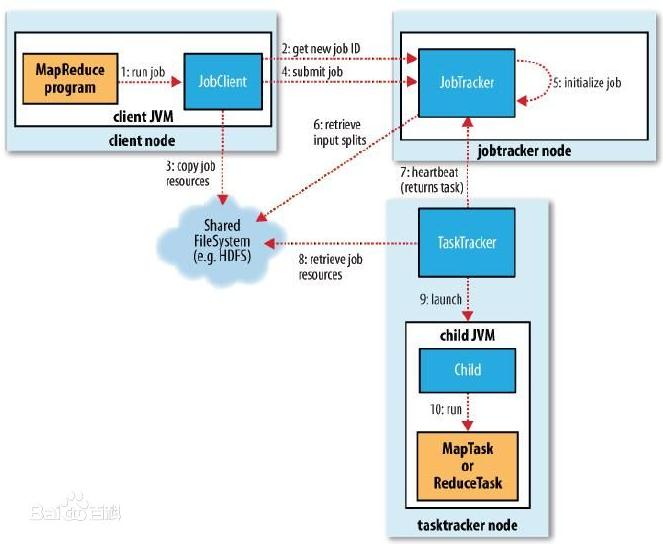

流程分析:
1.在客户端启动一个作业。
2.向JobTracker请求一个Job ID。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job
ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
二 MapReduce工作原理
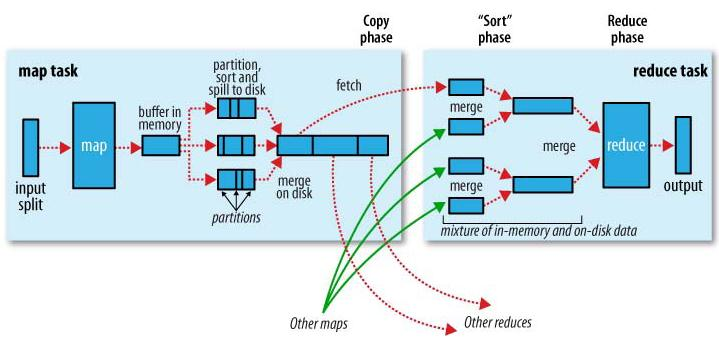

作业运行顺序:输入分片(input split)、map阶段、combiner阶段、shuffle阶段、reduce阶段。
1)input split
把输入文件按照一定的标准分片 (InputSplit),每个输入片的大小是固定的。
默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片,一共产生三个输入片。每一个输入片由一个Mapper进程处理,这里的三个输入片,会有三个Mapper进程处理。
2)map阶段
对输入片中的记录按照一定的规则解析成键值对,有个默认规则是把每一行文本内容解析成键值对,这里的“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
调用Mapper类中的map方法,解析出来的每一个键值对,调用一次map方法,如果有1000个键值对,就会调用1000次map方法,每一次调用map方法会输出零个或者多个键值对。
3)combiner阶段
按照一定的规则对输出的键值对进行分区,分区是基于键进行的,比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认情况下只有一个区,分区的数量就是Reducer任务运行的数量,因此默认只有一个Reducer任务。
4)shuffle阶段
对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值 对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果 是<1,3>、<2,1>、<2,2>。
5)reduce阶段
对数据进行归约处理,也就是reduce处理,通常情况下的Comber过程,键相等的键值对会调用一次reduce方法,经过这一阶段,数据量会减少,归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
MapReduce 1工作原理图文详解的更多相关文章
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- LVS-DR工作原理图文详解
为了阐述方便,我根据官方原理图另外制作了一幅图,如下图所示:VS/DR的体系结构: 我将结合这幅原理图及具体的实例来讲解一下LVS-DR的原理,包括数据包.数据帧的走向和转换过程. 官方的原理说明:D ...
- vue内置组件——transition简单原理图文详解
基本概念 Vue 在插入.更新或者移除 DOM 时,提供多种不同方式的应用过渡效果 在 CSS 过渡和动画中自动应用 class 可以配合使用第三方 CSS 动画库,如 Animate.css 在过渡 ...
- 微服务 Zipkin 链路追踪原理(图文详解)
一个看起来很简单的应用,可能需要数十或数百个服务来支撑,一个请求就要多次服务调用. 当请求变慢.或者不能使用时,我们是不知道是哪个后台服务引起的. 这时,我们使用 Zipkin 就能解决这个问题. 由 ...
- Iptables工作原理使用详解
Iptables防火墙简介 Iptables名词和术语 Iptables工作流程 基本语法 Filter 参数说明 NAT表: Icmp协议 TCP FLAG 标记 什么是状态检测 iptables的 ...
- EEPROM工作原理透彻详解
原文链接点击这里 EEPROM(Electrically Erasable Programmable read only memory)即电可擦可编程只读存储器,是一种掉电后数据不丢失(不挥发)存储芯 ...
- Android 异步通信:图文详解Handler机制工作原理
前言 在Android开发的多线程应用场景中,Handler机制十分常用 今天,我将图文详解 Handler机制 的工作原理,希望你们会喜欢 目录 1. 定义 一套 Android 消息传递机制 2. ...
随机推荐
- Linux 系统自动备份数据库及定时任务的设置
首先想到数据库的自动备份,由于涉及业务原因需要在每天固定的时间去调用方法执行备份.如果不考虑业务要求,只考虑实现的话可以通过Linux系统提供的定时任务去完成备份操作. 本文讲的就是利用Linux系统 ...
- hdu 2999 sg函数(简单博弈)
Stone Game, Why are you always there? Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/ ...
- poj 3246 Game
Game Time Limit: 4000MS Memory Limit: 65536K Total Submissions: 2707 Accepted: 488 Description W ...
- udp 多播2
11.3 多播 单播用于两个主机之间的端对端通信,广播用于一个主机对整个局域网上所有主机上的数据通信.单播和广播是两个极端,要么对一个主机进行通信,要么对整个局域网上的主机进行通信.实际情况下,经常 ...
- c#FileStream文件读写
//C#文件流写文件,默认追加FileMode.Append string msg = "okffffffffffffffff"; b ...
- SqlHelper类-全面
// ===============================================================================// Microsoft Data ...
- 使用一个数组存储一个英文句子"java is an object oriented programing language"
class fun { public static void main(String[] args) { String str="java is an object oriented pro ...
- TSimpleMsgPack的样例代码
TSimpleMsgPack的样例代码 unit uMain; interface uses SimpleMsgPack, Windows, Messages, SysUtils, Variants, ...
- MY JAVA-NOTE FIRST DAY
今天是第一天开通博客,我很开心,总算拥有了自己的博客了,以后我会经常在博客里分享一些JAVA的心得.
- Direct2D教程(十二)图层
什么是Layers? Layer,中文译成图层,在Direct2D中可以用来完成一些特殊效果,使用Layer的时候,先将Layer Push到render target,然后进行绘制,此时是直接绘制在 ...