CS231n 2016 通关 第五章 Training NN Part1
在上一次总结中,总结了NN的基本结构。
接下来的几次课,对一些具体细节进行讲解。
比如激活函数、参数初始化、参数更新等等。
=========================================================================================
首先,课程做 一个小插曲:

经常使用已经训练好的模型》》Finetune network
具体例子:
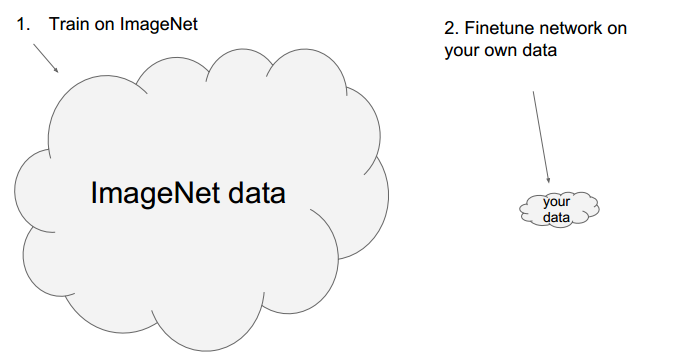

使用现成模型,修改部分层,使用现成的参数做初始参数。
以caffe为例,其提供了很多现成的模型:
https://github.com/BVLC/caffe/wiki/Model-Zoo
使用Finetune 主要是计算资源有限。

其次是上节课主要内容的简单回顾:

概括了NN的主要流程: 得到数据 ---》前向传播 ---》反向传播 ---》更新参数
另外便是链式法则:


实例:


NN的结构特点:
加入非线性:

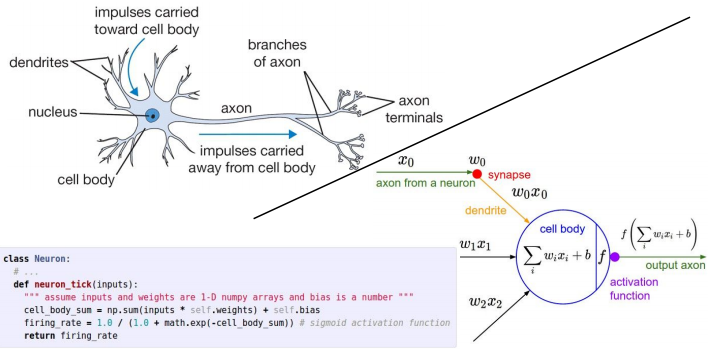
与神经系统比较:
多层NN结构:
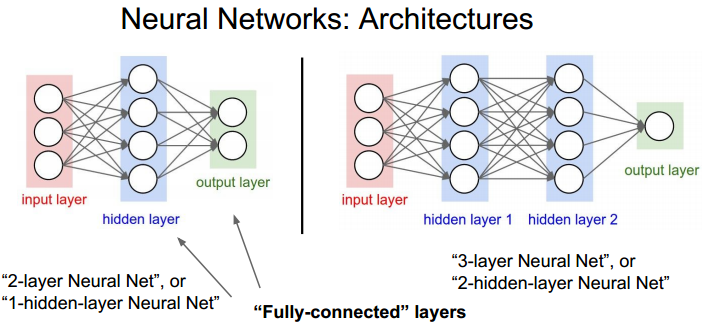
注意: 有些资料把输入层也算在NN的层数里。
=========================================================================================
本章的内容如下:
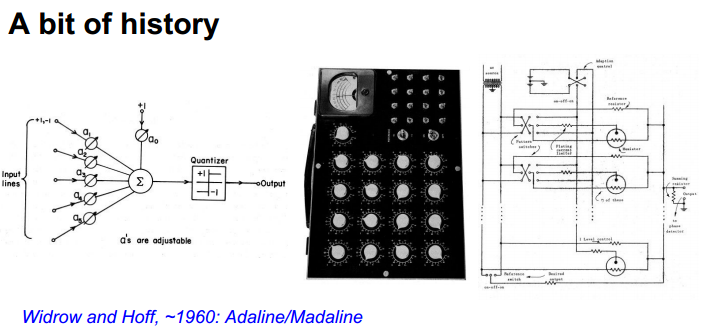
一些历史回顾
简单的字母识别系统:

当时就使用了伪梯度下降。其实不是严格可导。
之后形成了网络结构,并使用电路实现:
进一步形成了多层网络:

反向传播算法开始流行起来。
Deep Learning :
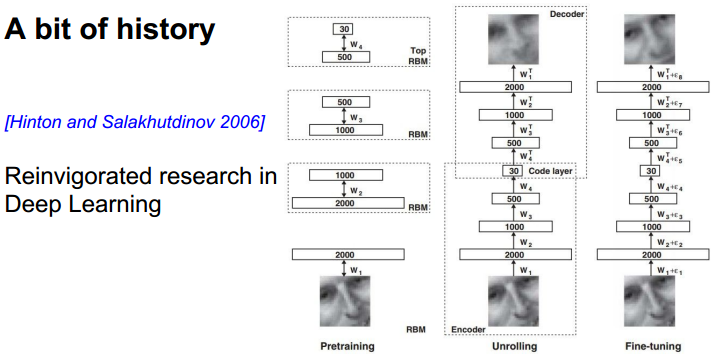
使用了非监督学习进行预处理,然后将得到的结果放到back propagation中。如今不需要这样做了。
技术革新:

2012年的图像分类结果最优。从此DL火起来了。
技术内容总览:

=========================================================================================
1、激活函数
激活函数的作用:

常用激活函数:

Sigmoid:特点以及缺陷
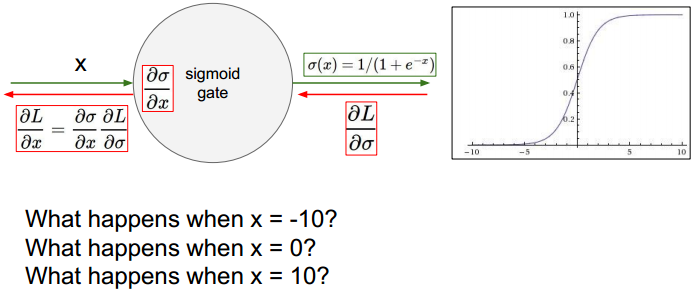

比较左侧s输入值与经过f后的输出值,会导致梯度消失、数值溢出。


当输入为正时,偏导均为正或均为负。

tanh:

仍然会有梯度消失的后果。
ReLU (Rectified Linear Unit):

其不会有溢出,计算更快。当x<0时,梯度为0.
缺点:出现死亡状态。
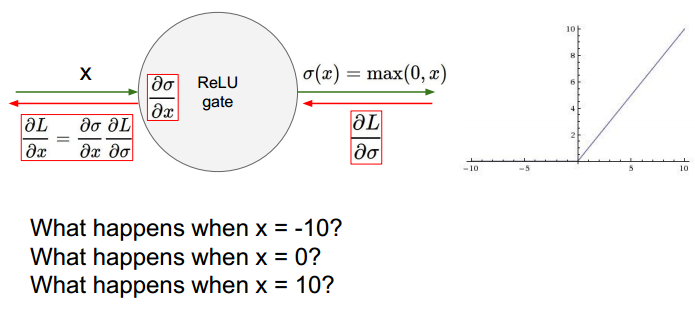

为负值输入时,不能更新参数。一般是学习率过高导致。另外使用合适的初始化,比如加入小的bias。
Leaky ReLU :解决负值不能更新参数。

ELU:

Maxout:

总结:

=========================================================================================
2、数据预处理
减均值与规则化:

减去均值,使得数据以0点为中心。规则化使得数据范围变成-1到1之间。
PCA 与 Whitening

PCA能将数据降为表示。白化降低数据的相关性。
具体的细节可以参考课程配套笔记。
效果比较:

实践经验:在图像处理中减均值用的较多,归一化也比会使用。

=========================================================================================
3、权重参数初始化
问题:

方案一:

可能导致的结果:
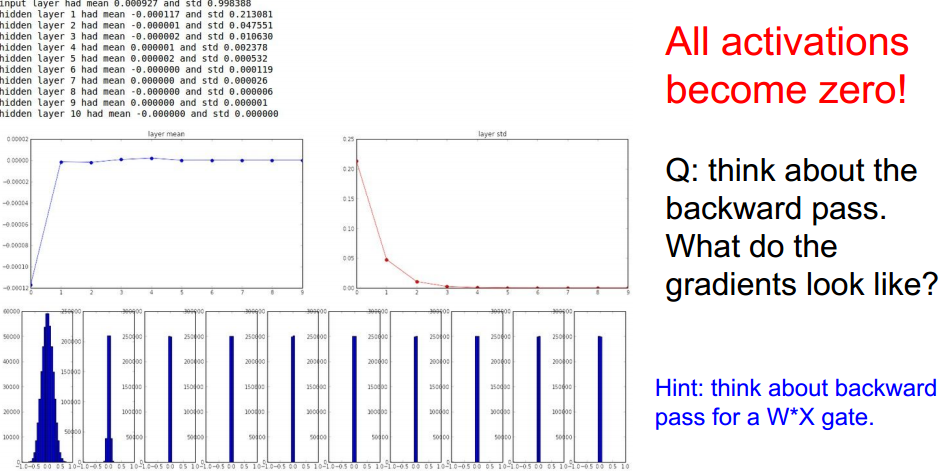
可能由于scale太小造成,使得后面隐藏层的输入变为了0。改进:

方案二:

方案三:

一些参考:具体的细节需要分析论文。

=========================================================================================
4、Batch Normalization
结构:


在全连接或者卷积层后、在非线性激活函数之前使用。
可以参考此博文进行了解。
计算细节:
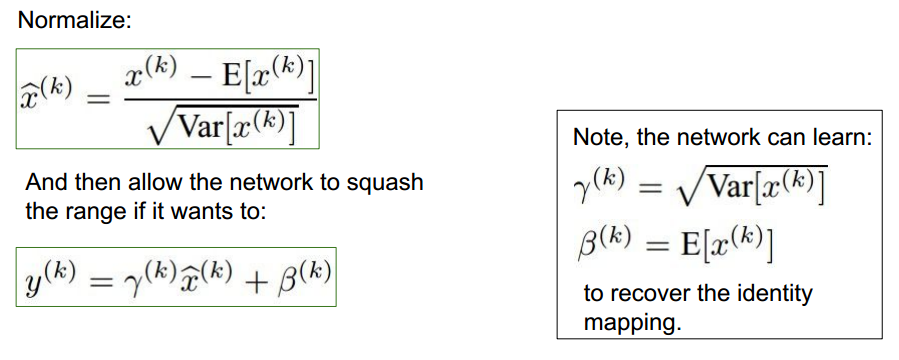

BN的优点: 可使用高的学习率更快收敛。dropout与正则化需求降低。
训练阶段与测试阶段不同的处理:

主要均值与方差的计算。测试阶段不再对数据计算均值与方差,而是使用train阶段得到的值。
=========================================================================================
5、实现流程
(1) 对数据预处理

(2) 选择合适的网络结构。

(3) 验证loss 是否合理。

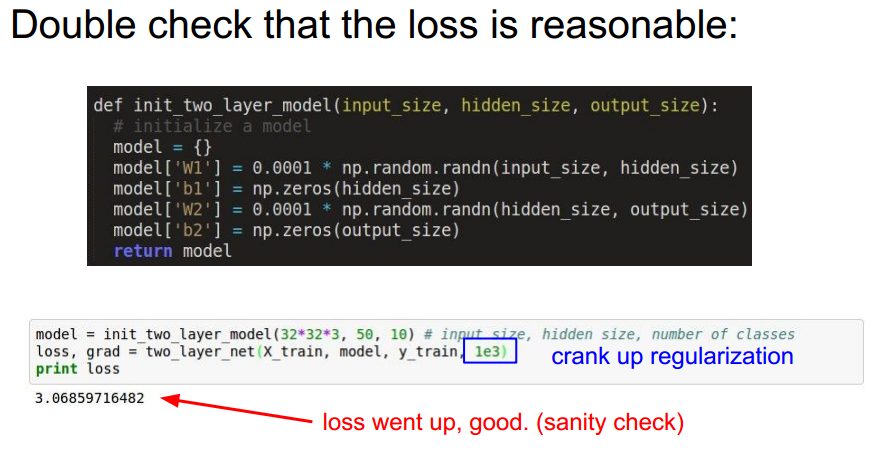
(4) 开始训练
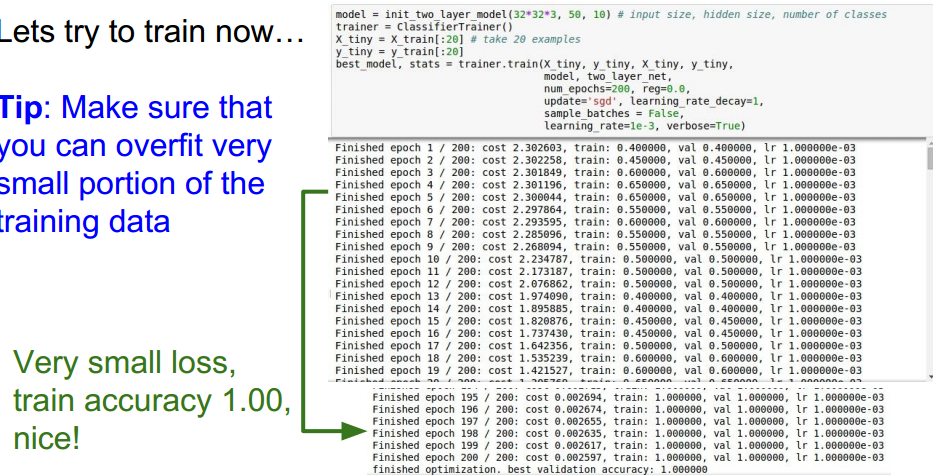
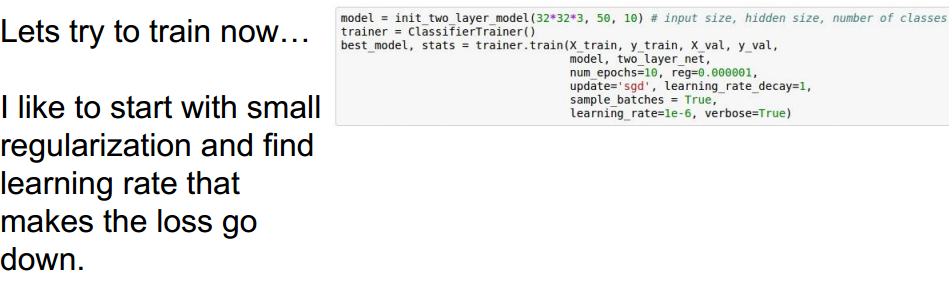
选择不同的正则强度系数和学习率,观察loss是否在下降:


不同的选择:

=========================================================================================
6、超参数选取
选择策略:

实例:正则化强度系数与学习率选取
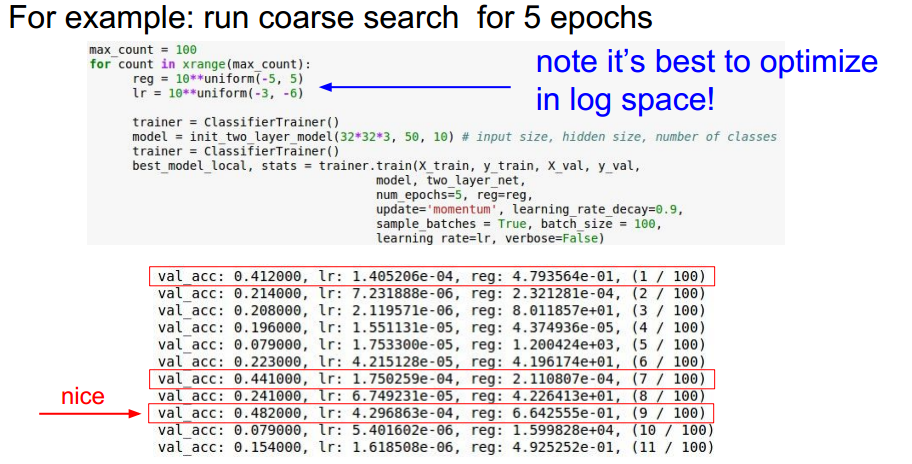
调整:

原因是学习率太高了。
选取参数的策略:


大神的经验:将不同的选取方式做总结并代码实现,方便调试不同的模型。快速有效:

一些例子:
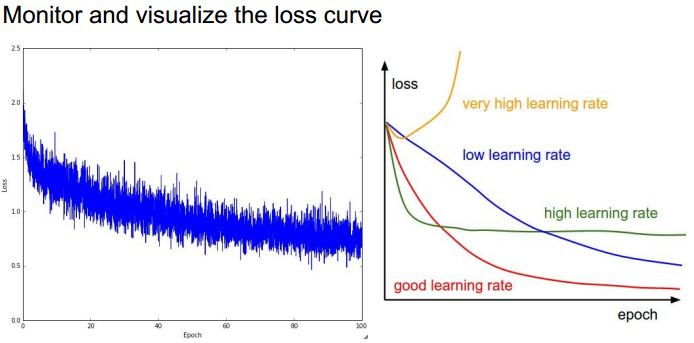
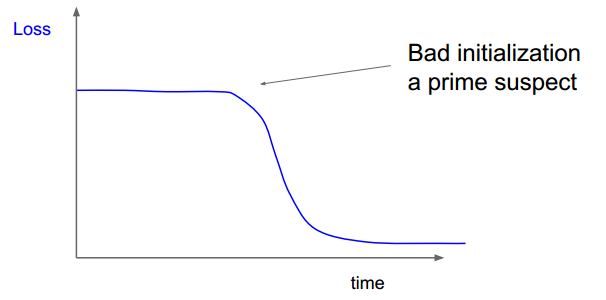
右图的初始化存在问题,在很长时间里,loss并没有下降。
一些loss 图:
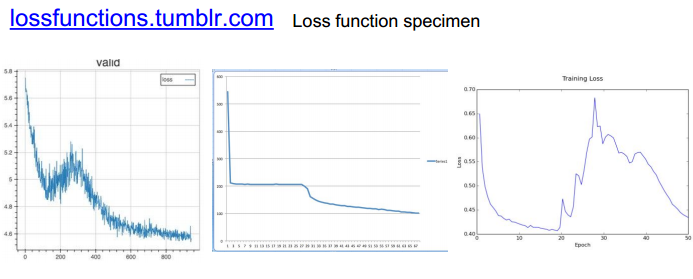
关于accuracy以及参数更新:


对更新参数进行评估。
=========================================================================================
总结:

本章是相对而言比较难,并且及其重要的一章。需要多参考对应的note对细节进行学习。
附:通关CS231n企鹅群:578975100 validation:DL-CS231n
CS231n 2016 通关 第五章 Training NN Part1的更多相关文章
- CS231n 2016 通关 第六章 Training NN Part2
本章节讲解 参数更新 dropout ================================================================================= ...
- CS231n 2016 通关 第五、六章 Fully-Connected Neural Nets 作业
要求:实现任意层数的NN. 每一层结构包含: 1.前向传播和反向传播函数:2.每一层计算的相关数值 cell 1 依旧是显示的初始设置 # As usual, a bit of setup impor ...
- CS231n 2016 通关 第四章-NN 作业
cell 1 显示设置初始化 # A bit of setup import numpy as np import matplotlib.pyplot as plt from cs231n.class ...
- CS231n 2016 通关 第五、六章 Dropout 作业
Dropout的作用: cell 1 - cell 2 依旧 cell 3 Dropout层的前向传播 核心代码: train 时: if mode == 'train': ############ ...
- CS231n 2016 通关 第五、六章 Batch Normalization 作业
BN层在实际中应用广泛. 上一次总结了使得训练变得简单的方法,比如SGD+momentum RMSProp Adam,BN是另外的方法. cell 1 依旧是初始化设置 cell 2 读取cifar- ...
- CS231n 2016 通关 第四章-反向传播与神经网络(第一部分)
在上次的分享中,介绍了模型建立与使用梯度下降法优化参数.梯度校验,以及一些超参数的经验. 本节课的主要内容: 1==链式法则 2==深度学习框架中链式法则 3==全连接神经网络 =========== ...
- CS231n 2016 通关 第三章-Softmax 作业
在完成SVM作业的基础上,Softmax的作业相对比较轻松. 完成本作业需要熟悉与掌握的知识: cell 1 设置绘图默认参数 mport random import numpy as np from ...
- CS231n 2016 通关 第三章-SVM 作业分析
作业内容,完成作业便可熟悉如下内容: cell 1 设置绘图默认参数 # Run some setup code for this notebook. import random import nu ...
- CS231n 2016 通关 第三章-SVM与Softmax
1===本节课对应视频内容的第三讲,对应PPT是Lecture3 2===本节课的收获 ===熟悉SVM及其多分类问题 ===熟悉softmax分类问题 ===了解优化思想 由上节课即KNN的分析步骤 ...
随机推荐
- HDU1532_Drainage Ditches(网络流/EK模板/Dinic模板(邻接矩阵/前向星))
Drainage Ditches Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- 验证loadrunner对Ajax内容的校验
前一阵和开发的同事一起測试某个系统的性能.此系统是发送Ajax请求到后台,再调用第三方的某项服务. 第三方服务的性能由不得我们控制.因此开发者做了一下改进.超时则直接返回. 于是在loadrunner ...
- HDU 5667 :Sequence
Sequence Accepts: 59 Submissions: 650 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536 ...
- Linux(centos 6.5) 调用java脚本以及定时运行的脚本实例及配置文件具体解释
Linux(centos 6.5) 调用java脚本以及定时运行的脚本实例 一.调用java程序脚本(默认已经搭建好了Java环境) 1.jdk 安装路径 /usr/jdk/jdk1.7/-- 2.j ...
- 1.新手上路:Windows下,配置Qt环境
个人体会: 我最初只是想看看C++除了"黑窗口"之外,怎么才能做一些"更好看的东西".之后在网上看到有人推荐Qt,就看了一下官网(https://www.qt. ...
- ecshop 国付宝支付接口
function get_code($order, $payment){ $version = '2.2'; $charset = '1'; $language = '1'; $signType = ...
- 不为客户连接创建子进程的并发回射服务器( select实现 )
前言 在此前,我已经介绍了一种并发回射服务器实现( 点此进入 ).它通过调用fork函数为每个客户请求创建一个子进程.同时,我还为此服务器添加了自动消除僵尸子进程的机制.现在请想想,在客户量非常大的情 ...
- Android-通过SlidingMenu高仿微信6.2最新版手势滑动返回(二)
转载请标明出处: http://blog.csdn.net/hanhailong726188/article/details/46453627 本文出自:[海龙的博客] 一.概述 在上一篇博文中,博文 ...
- VLC RTP Over TCP
在RTSP协议请求数据时,让VLC以TCP的方式获取服务器发来的RTP数据 不为别的,下次回复直接用博客链接就能回复大家了! 操作:工具 -> 首选项 然后: 搞定! ------------- ...
- [通信]Linux User层和Kernel层常用的通信方式
转自:https://bbs.csdn.net/topics/390991551?page=1 netlink:https://blog.csdn.net/stone8761/article/deta ...