Python分布式爬虫开发搜索引擎 Scrapy实战视频教程
点击了解更多Python课程>>>
Python分布式爬虫开发搜索引擎 Scrapy实战视频教程
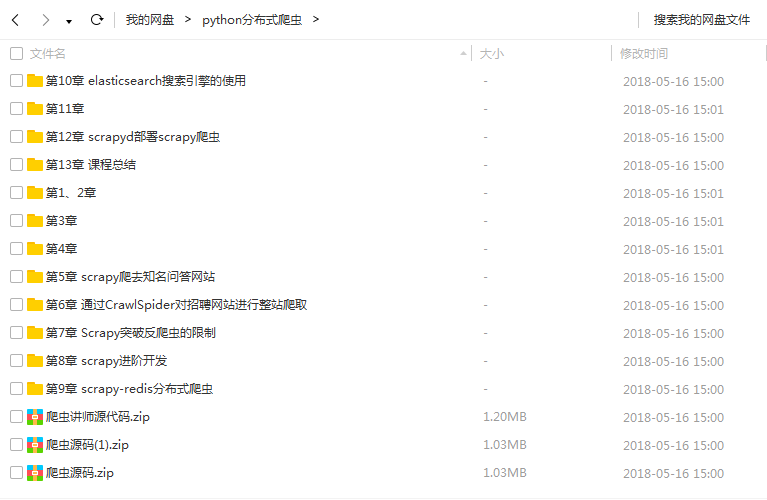
课程目录
|--第01集 教程推介 98.23MB
|--第02集 windows下搭建搭建环境 351.68MB
|--第03集 爬虫基础知识回顾 232.76MB|
|--第04集 scrapy爬取知名技术文章网站 276.26MB|
|--第05集 scrapy爬取知名问答网站 428.26MB
|--第06集 通过CrawlSpider对招聘网站进行整站爬取 332.8MB
|--第07集 Scrapy突破反爬虫的限制 84.67MB
|--第08集 scrapy进阶搭建 360.5MB
|--第09集 scrapy-redis分布式爬虫 144.1MB
|--第10集 elasticsearch搜索引擎的使用 225.76MB
|--第11集 django实现搜索网站 104.55MB
|--第12集 scrapyd布署scrapy爬虫 305.46MB
|--第13集 教程概括 376.65MB

支付后联系:QQ17028139 领取以上全部教程!
Python分布式爬虫开发搜索引擎 Scrapy实战视频教程的更多相关文章
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
随机推荐
- Sicily 1027. MJ, Nowhere to Hide
//就是一个简单的字符串配对~~用map来解决很easy #include <iostream> #include <map> #include <string> ...
- html select change事件触发
做小组内使用的一个简单工具,其中要实现的一个小功能是当某个下拉菜单的选择值改变时触发另一表单元素的属性变化.自然的想到使用select表单元素的onchange事件. 下拉菜单部分的代码如下: < ...
- jquery自定义组件开发
jquery的组件已经有很多,但是有可能找不到符合我们需求的组件,所以我们可以动手自己封装一个jquery组件. 第一步要知道封装jquery组件的基本语法 (function ($) { $.fn. ...
- babel7中 corejs 和 corejs2 的区别
babel7中 corejs 和 corejs2 的区别 最近在给项目升级 webpack4 和 babel7,有一些改变但是变化不大.具体过程可以参考这篇文章 webpack4:连奏中的进化.只是文 ...
- 关于下载文件封装的两个类(Mars)
首先是文件FileUtils.java package mars.utils; import java.io.File; import java.io.FileOutputStream; import ...
- 1979 第K个数
1979 第K个数 时间限制: 1 s 空间限制: 1000 KB 题目等级 : 黄金 Gold 题目描述 Description 给定一个长度为N(0<n<=10000) ...
- js中.toString()和String()的一丢丢区别
1..toString()可以将所有的的数据都转换为字符串,但是要排除null 和 undefined 例如将false转为字符串类型 <script> var str = false ...
- SQL查询-约束-多表
一.SQL语句查询 1.聚合函数 COUNT()函数,统计表中记录的总数量 注:COUNT()返回的值为Long类型;可通过Long类的intValue()方法 ...
- uvm_reg_file——寄存器模型(十四)
有了uvm_reg_field, uvm_reg, uvm_block, 也许我们需要跟大的uvm_file,这就是传说中的寄存器堆. // // CLASS: uvm_reg_file // Reg ...
- 干货|java缓存技术详解
一.缓存是什么? 请点击此处输入图片描述 Cache ①高速缓冲存储器,其中复制了频繁使用的数据以利于快速访问. ②位于速度相差较大的两种硬件/软件之间,用于协调两者数据传输速度差异的结构 二.缓存有 ...