python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库
get()是获取网页最常用的方式,其基本使用方式如下
使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML
下面这段代码便是爬取百度的信息并简单输出百度的界面信息
import requests
from bs4 import BeautifulSoup r=requests.get('http://www.baidu.com')
r.encoding=None
result=r.text
bs=BeautifulSoup(result,'html.parser')
print(bs.title)
print(bs.title.text)
import requests
from bs4 import BeautifulSoup #用来解决乱码现象,所以编写爬取信息的代码最好带上(输出出现乱码或者UnicodeEncodeError:'gbk'codec can't encode character)
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
#用来防止反爬取,可以了解一下
headers={"User-Agent" : "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.6)",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "en-us",
"Connection" : "keep-alive",
"Accept-Charset" : "GB2312,utf-8;q=0.7,*;q=0.7"
}
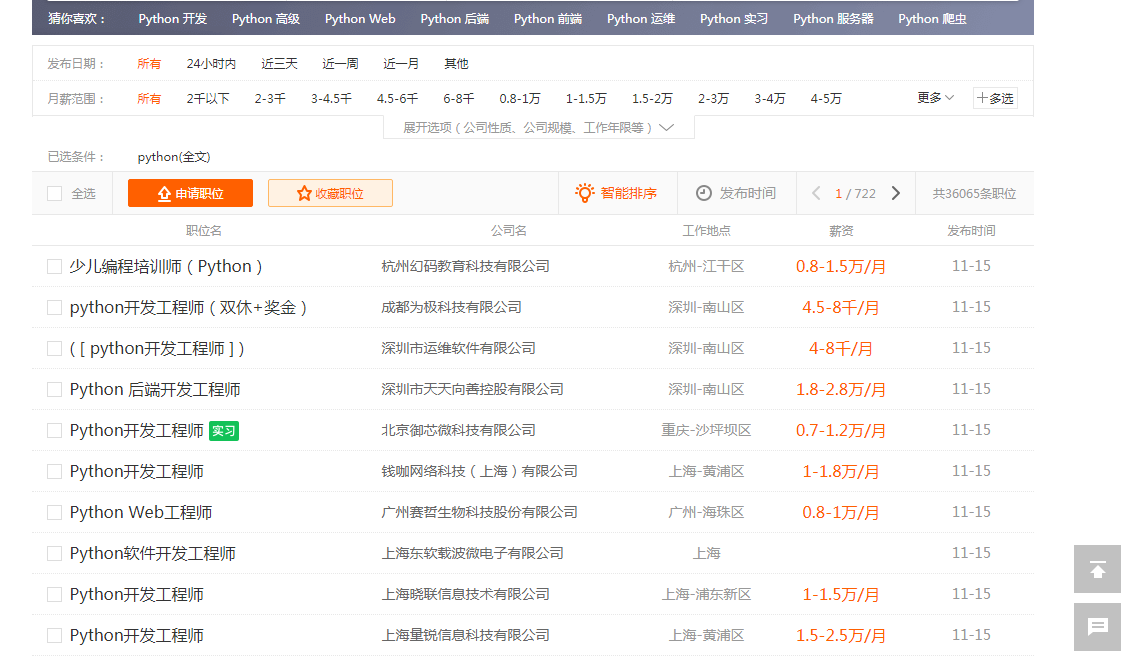
#获取51job网站的基本信息
r=requests.get('https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=')
r.encoding=r.apparent_encoding
result=r.text
bs=BeautifulSoup(result,'html.parser')
print(bs.prettify()) u1=bs.find_all('u1',attrs={'class':'item_con_list'}) #这部分代码便是我们爬取的目标,51job网站上关于python职业的薪资
print(len(u1))
li=bs.find_all('span',attrs={'class':'t4'})
for l in li:
print(l.text)
上面这段代码便是爬取51job网站上的与python相关职业的薪资

python之简单爬取一个网站信息的更多相关文章
- [Python学习] 简单爬取CSDN下载资源信息
这是一篇Python爬取CSDN下载资源信息的样例,主要是通过urllib2获取CSDN某个人全部资源的资源URL.资源名称.下载次数.分数等信息.写这篇文章的原因是我想获取自己的资源全部的评论信息. ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- python爬取电影网站信息
一.爬取前提1)本地安装了mysql数据库 5.6版本2)安装了Python 2.7 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的html内 ...
- 用python爬虫简单爬取 笔趣网:类“起点网”的小说
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- python爬虫学习-爬取某个网站上的所有图片
最近简单地看了下python爬虫的视频.便自己尝试写了下爬虫操作,计划的是把某一个网站上的美女图全给爬下来,不过经过计算,查不多有好几百G的样子,还是算了.就首先下载一点点先看看. 本次爬虫使用的是p ...
随机推荐
- 绕过WAF、安全狗知识整理
0x01 前言 目前市场上的WAF主要有以下几类 1. 以安全狗为代表的基于软件WAF 2. 百度加速乐.安全宝等部署在云端的WAF 3. 硬件WAF WAF的检测主要有三个阶段,我画了一张图进行说明 ...
- Flutter BottomNavigationBar 组件
BottomNavigationBar 是底部导航条,可以让我们定义底部 Tab 切换,bottomNavigationBar是 Scaffold 组件的参数. BottomNavigationBar ...
- mybatis 级联
级联是一个数据库实体的概念.一对多的级联,一对多的级联,在MyBatis中还有一种被称为鉴别器的级联,它是一种可以选择具体实现类的级联. 级联不是必须的,级联的好处是获取关联数据十分便捷,但是级联过多 ...
- 改进初学者的PID-修改整定参数
最近看到了Brett Beauregard发表的有关PID的系列文章,感觉对于理解PID算法很有帮助,于是将系列文章翻译过来!在自我提高的过程中,也希望对同道中人有所帮助.作者Brett Beaure ...
- JAVA视频压缩
https://www.cnblogs.com/chuanyueinlife/p/9014627.html
- [转]Office 安装卸载太麻烦?用这个工具帮你解决:Office Tool Plus
原文链接:https://sspai.com/post/43839 Office Tool官方网站:https://otp.landian.vip/zh-cn/ 真的很好用,发一个安装的截图:
- Underscore.js 的模板功能
Underscore是一个非常实用的JavaScript库,提供许多编程时需要的功能的支持,他在不扩展任何JavaScript的原生对象的情况下提供很多实用的功能. 无论你写一段小的js代码,还是写一 ...
- .net core 使用SignalR实现实时通信
这几天在研究SignalR,网上大部分的例子都是聊天室,我的需求是把服务端的信息发送给前端展示.并且需要实现单个用户推送. 用户登录我用的是ClaimsIdentity,这里就不多解释,如果不是很了解 ...
- HTML:给body增加全屏的背景图
只需要在head中增加如下代码即可 <head> {#设置背景#} <style> body { height: 100%;width: 100%; background: u ...
- Java网络编程探究|乐字节
大家好,我是乐字节小乐,上次给大家讲述了Java中的IO流之输出流|乐字节,本文将会给大家讲述网络编程. 主要内容如下: 网络 网络分层 IP位置 端口port 网络编程 一. 网络 1.概念 网络即 ...