Redis集群部署与维护
Redis集群部署与维护
目录:
一、 集群架构
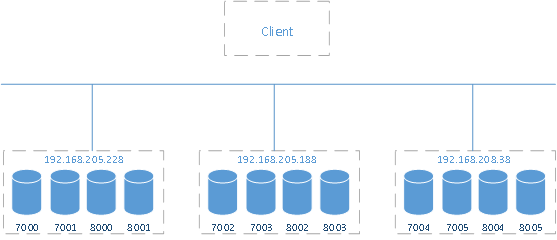
redis主从对应关系:
master:192.168.205.228:7000 slave:192.168.205.188:8003
master:192.168.205.228:7001 slave:192.168.208.38:8005
master:192.168.205.188:7002 slave:192.168.208.38:8004
master:192.168.205.188:7003 slave:192.168.205.228:8000
master:192.168.208.38:7004 slave:192.168.205.188:8002
master:192.168.208.38:7005 slave:192.168.205.228:8001
二、 集群部署
本次需要在三台服务器上搭建12台redis,每台服务器4台,两主两从,形成一套redis集群系统,分别如下
192.168.205.228 7000 7001 8000 8001
192.168.205.188 7002 7003 8002 8003
192.168.208.38 7004 7005 8004 8005
其中7000-7005做主redis,8000-8005做从redis,主从搭配根据redis-trib.rb执行的结果随机搭配。
1、 创建redis-cluster目录
cd /hxdata
mkdir redis-cluster
cd redis-cluster
mkdir 7000 7001 8000 8001
2、 编译redis
cd /usr/local/src/
wget http://download.redis.io/releases/redis-3.0.5.tar.gz
tar zxvf ./redis-3.0.3.tar.gz
cd redis-3.0.3
make
make install
3、 编辑redis配置文件
cp /usr/local/src/redis-3.0.3/src/redis-server /hxdata/redis-cluster/7000/
cp /usr/local/src/redis-3.0.3/src/redis-server /hxdata/redis-cluster/7001/
cp /usr/local/src/redis-3.0.3/src/redis-server /hxdata/redis-cluster/8000/
cp /usr/local/src/redis-3.0.3/src/redis-server /hxdata/redis-cluster/8001/
vim /usr/local/src/redis-3.0.3/redis.conf
daemonize yes
port 7000
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
PS:redis.conf配置文件根据实际情况修改参数,此处先修改两个参数,daemonize为yes表示后台运行,默认为no,port改成自定义的端口号,默认为6379,本地需要运行4个redis,端口号分别为7000(主)-8000(从),7001(主)-8001(从)。因此,port需要对应修改。开启集群cluster功能,设置cluster配置文件和超时时间。
cp /usr/local/src/redis-3.0.3/redis.conf /hxdata/redis-cluster/7000/
cp /usr/local/src/redis-3.0.3/redis.conf /hxdata/redis-cluster/7001/
cp /usr/local/src/redis-3.0.3/redis.conf /hxdata/redis-cluster/8000/
cp /usr/local/src/redis-3.0.3/redis.conf /hxdata/redis-cluster/8001/
/hxdata/redis-cluster/7000/redis-server /hxdata/redis-cluster/7000/redis.conf
/hxdata/redis-cluster/7001/redis-server /hxdata/redis-cluster/7001/redis.conf
/hxdata/redis-cluster/8000/redis-server /hxdata/redis-cluster/8000/redis.conf
/hxdata/redis-cluster/8001/redis-server /hxdata/redis-cluster/8001/redis.conf
4、 配置redis集群
通过集群命令行工具redis-trib.rb命令生存redis集群
./redis-trib.rb create --replicas 1 192.168.205.228:7000 192.168.205.228:7001 192.168.205.188:7002 192.168.205.188:7003 192.168.208.38:7004 192.168.208.38:7005 192.168.205.188:8002 192.168.205.188:8003 192.168.208.38:8004 192.168.208.38:8005 192.168.205.228:8000 192.168.205.228:8001
当看到一下信息表示集群配置成功
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
Ps:配置redis集群时可能出现以下错误:
- 错误内容:
/usr/bin/env: ruby: No such file or directory
|
yum install ruby |
- 错误内容:
./redis-trib.rb:24:in `require': no such file to load -- rubygems (LoadError)
from ./redis-trib.rb:24
|
yum install rubygems |
- 错误内容:
/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': no such file to load -- redis (LoadError)
from /usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `require'
from ./redis-trib.rb:25
|
gem install redis |
|
l 错误内容: ERROR: Could not find a valid gem 'redis' (>= 0), here is why:Unable to download data from https://rubygems.org/ - Errno::ECONNRESET: Connection reset by peer - SSL_connect (https://rubygems.org/latest_specs.4.8.gz) gem sources --remove https://rubygems.org/ gem sources -a https://ruby.taobao.org/ gem sources -l *** CURRENT SOURCES *** https://ruby.taobao.org # 请确保只有 ruby.taobao.org gem install redis |
5、 redis集群性能测试
可redis-benchmark命令行工具在不通的主机上分别对另外两天主机进行测试
192.168.205.228 redis-benchmark -h 192.168.205.188 -p 7002 -n 1000000 -c 10
192.168.205.188 redis-benchmark -h 192.168.205.38 -p 7004 -n 1000000 -c 10
192.168.208.38 redis-benchmark -h 192.168.208.228 -p 7000 -n 1000000 -c 10
6、 常用redis处理命令
redis-benchmark: redis基准信息,redis服务器性能检测
redis-cli:redis客户端
./redis-trib.rb check 127.0.0.1:7000:检查集群状态
./redis-trib.rb reshard:redis分片工具
./redis-trib.rb add-node:增加节点
./redis-trib.rb del-node:删除节点
redis-cli –p 7000 cluster nodes:查看集群信息
redis-cli -c -p 8000 cluster replicate fcd07fd4f84fc60bf4a2a54519523bb00f853db1:设置8000为7003的从节点
CLUSTER ADDSLOTS slot1 [slot2] ... [slotN]:将哈希槽指派给节点
CLUSTER DELSLOTS slot1 [slot2] ... [slotN]:移除某个节点的哈希槽
CLUSTER SETSLOT slot NODE node: 将指定的槽 slot 指派给节点 node
CLUSTER SETSLOT slot MIGRATING node: 将给定节点 node 中的槽 slot 迁移出节点,例:向节点 B 发送命令 CLUSTER SETSLOT 8 IMPORTING A
CLUSTER SETSLOT slot IMPORTING node: 将给定槽 slot 导入到节点 node,例:向节点 A 发送命令 CLUSTER SETSLOT 8 MIGRATING B
7、 对集群进行重新分片
./redis-trib.rb reshard 127.0.0.1:7000
8、 故障转移测试
redis-cli -p 7000 cluster nodes | grep master
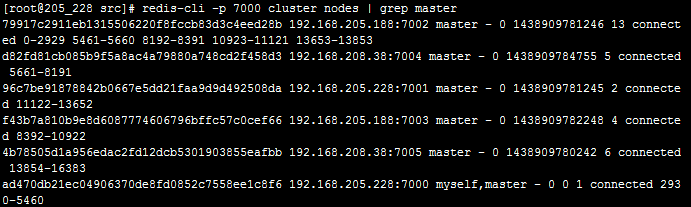
redis-cli -p 7001 debug segfault
设置192.168.205.228:7001 redis失效

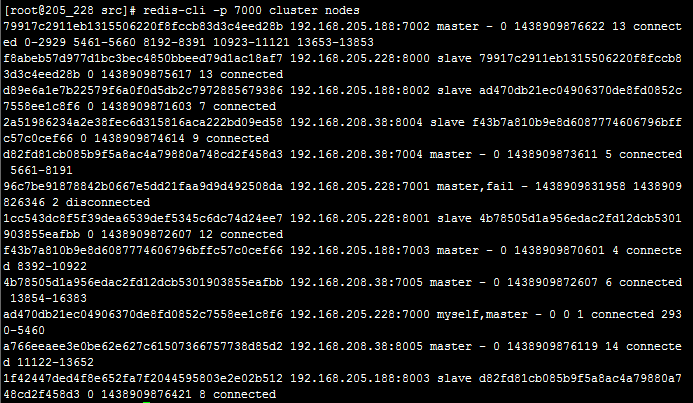
redis-cli -p 7000 cluster nodes
可以看到192.168.205.228:7001的状态为failed,并且它的从库192.168.208.38:8005从slave变更为master,说明主从配置正常
9、 添加新节点到集群
在192.168.208.38上创建一个新的redis节点7006
cd /data/redis-cluster/
mkdir 7006
cd ./7005
cp redis-server ../7006
cp redis.conf ../7006
cd ../7006
vim redis.conf
port 7006
./redis-server ./redis.conf
lsof –i:7006

在192.168.205.228主机上将新增节点加入集群中
./redis-trib.rb add-node 192.168.208.38:7006 192.168.205.228:7000
redis-cli -p 7000 cluster nodes
可以看到红线处,7006已经加入集群

但是它目前还没有哈希槽,所以还不能算是主节点

设置7006为主节点
./redis-trib.rb reshard 127.0.0.1:7000

移动1000个哈希槽到新节点

输入新节点的ID

原节点是所有其它的节点

redis-cli -p 7000 cluster nodes

将新节点设置成192.168.208.38:7005的slave
在192.168.208.38上
redis-cli –p 7006
127.0.0.1:7006> cluster replicate 4b78505d1a956edac2fd12dcb5301903855eafbb
10、 redis单实例业务存储分析
定期对redis集群中的某个实例(优先选择从库)进行业务存储分析,统计每个业务暂用内存的大小,合理规划内存的使用。当某个实例占用memory容量明显不同于其它实例时,可以通过此方法进行对比分析,查看是否有不合理的key占用大量的memory空间。
通过在一台从库上执行bgsave命令,将内存的数据通过rdb的方式持久化到硬盘上,由于bgsave命令会新开一个子进程,所以此命令并不影响主进程的使用,但是需要观察机器负载情况,如果因为其它原因(如硬盘读写问题)导致机器负载高,则会影响主进程的使用。
127.0.0.1:8000>bgsave
优化对rdb文件分析时间较长,出于安全考虑,最好将最新形成的rdb文件拷贝到非线上服务器上进行分析,如204.70/data1/下。
在204.70上执行rdb分析的命令
rdb -c memory /data1/8000.rdb > 8000_20160318.csv
通过如下命令对形成的csv文件进行数据统计
cat 8001_20160312.csv | awk -F'[,|"]' '{print $4" "$6}' | awk -F '[_| ]' '{sum[$1]+=$NF}END{for(type in sum)print type,sum[type]}' | sort -nr -k2
示例:

以上对redis集群单实例从库的数据分析,可以通过对单实例的数据来计算整个集群的业务数据分布和大小等情况。目前web的redis cluster是6主6从,所以如果计算整个集群mb的key容量,需要单实例的mb 的key大小乘以12,就可以得出mb业务的key在整个集群的占用内存的大小。
三、 Redis优化
1、 主从同步
1)全部同步
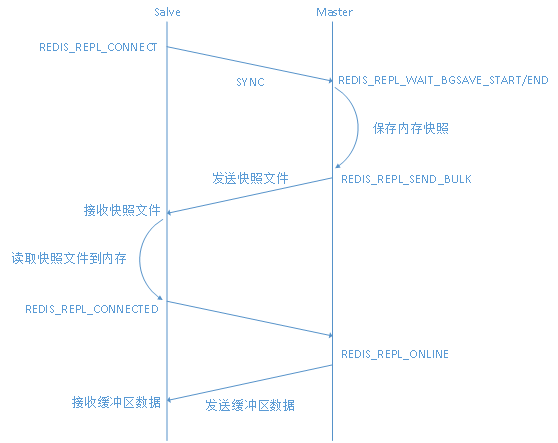
redis主从完全同步时,从服务器都将向主服务器发送一个 SYNC 命令。接到 SYNC 命令的主服务器将开始执行 BGSAVE ,并在保存操作执行期间,将所有新执行的写入命令都保存到buffer这个缓冲区里面。当 BGSAVE 执行完毕后, 主服务器将执行保存操作所得的 .rdb 文件发送给从服务器, 从服务器接收这个 .rdb 文件, 并将文件中的数据载入到内存中。之后主服务器会以 Redis 命令协议的格式, 将写命令缓冲区中积累的所有内容都发送给从服务器。
但是,当从服务器载入rdb文件完成之前,buffer这个缓冲区满了,导致buffer超限,就会被redis master断开,从而出现I/O error trying to sync with MASTER: connection lost这个错误,这时就需要调整client-output-buffer-limit slave 后面的参数值。
redis的slave buffer(replication buffer,master端上)存放的数据是下面三个时间内所有的master数据更新操作。
- master执行rdb bgsave产生snapshot的时间
- master发送rdb到slave网络传输时间
- slave load rdb文件把数据恢复到内存的时间
client-output-buffer-limit在配置文件中有三行配置,分别对一般client,slave和pubsub。
client-output-buffer-limit normal 0 0 0 #对一般的client
client-output-buffer-limit slave 256mb 64mb 60 #对redis的slave
client-output-buffer-limit pubsub 32mb 8mb 60 #对发布/订阅这种client
这里主要对slave做出调整
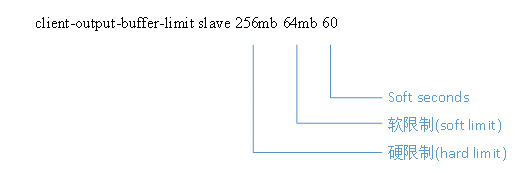
- hard limit:当buffer达到hard limit的限制后,master断开slave的连接
- soft limit:当在soft seconds时间内,buffer的量达到soft limit的限制,master不会断开slave的连接,当buffer的量在soft seconds时间后依然超出soft limit的限制,则断开slave的连接。
当redis处于运行状态并且不能重启的情况下,可以通过config set命令来调整client-output-buffer-limit参数,soft limit和hard limit需要换成字节。
config set client-output-buffer-limit "normal 0 0 0 slave 536870912 536870912 120 pubsub 33554432 8388608 60"
2)增量同步Replication Backlog
Redis 2.8 以后增加了部分同步功能, 这个功能主要用来抗网络闪断用的, 对于新加入的 Slave 是不适用,Redis 每次启动时都会随机生成一个 runid, 用来标识这个实例, 只有 runid 相同的才能使用增量同步, 所以 Slave 一旦重启只能全量同步。当 Slave 断开再重新连接 Master 时, 会带上上次同步的 offset 值, Master 根据这个值来决定发送那些数据给 Slave
当主服务器进行命令传播的时候,Maser不仅将所有的数据更新命令发送到所Slave的replication buffer,还会写入replication backlog,断开的Slave重新连接上Master的时候,Slave将会发送psync命令(包含复制的偏移量offset),请求partial resync。如果请求的 runid 不存在,那么执行全量的sync操作,相当于重新建立主从复制。
Replication Buffer 和 Replication Backlog 的区别
- Replication Buffer 对应于每个 Slave,通过 config set client-output-buffer-limit slave 设置, 每个Slave 一个单独的Buffer
- replication backlog 是一个环形缓冲区,整个 Master 进程中只会存在一个,所有的 Slave公用
- backlog 的大小通过repl-backlog-size参数设置, 默认值 1M
- repl_backlog 在redis 启动的时候初始化为NULL,当有Slave连接上来的时候,会被指向创建的buffer
- 在所有slave都断开的情况下,backlog在默认的3600秒后释放,可以通过repl-backlog-ttl来设置断开时间
3)同步超时repl-timeout
repl-timeout 60 replication连接的超时时间
三种情况认为复制超时:
- slave角度,如果在repl-timeout时间内没有收到master SYNC传输的rdb snapshot数据
- slave角度,在repl-timeout没有收到master发送的数据包或者ping
- master角度,在repl-timeout时间没有收到REPCONF ACK确认信息
当redis检测到repl-timeout超时(默认值60s),将会关闭主从之间的连接,redis slave发起重新建立主从连接的请求。对于内存数据集比较大的系统,可以增大repl-timeout参数。一般需要大于master生成rdb的时间+rdb传输时间+slave载入rdb到内存的时间。
2、 redis持久化之AOF机制
1)AOF机制
AOF 即Append Only File,实现机制:
如果数据很重要无法承受任何损失,可以考虑使用AOF方式进行持久化,默认Redis没有开启AOF(append onlyfile)方式的全持久化模式。
Redis将数据库做个快照,遍历所有数据库,将数据库中的数据还原为跟客户端发送来的指令的协议格式的字符串,然后Redis新建一个临时文件将这些快照数据保存,待快照程序结束后将临时文件名修改为正常的aof文件名,原有的文件则自动丢弃,由于在快照进行的过程中可能存在新增的命令修改了数据库中的数据,则在快照程序结束后需要将新修改的数据追加到aof文件中,后续每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。这样就支持了实时的持久化。
在启动时Redis会逐个执行AOF文件中的命令来将硬盘中的数据载入到内存中,载入的速度相较RDB会慢一些,AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof,可以通过appendfilename参数修改该名称。
Redis允许同时开启AOF和RDB,既保证了数据安全又使得进行备份等操作十分容易。此时重新启动Redis后Redis会使用AOF文件来恢复数据,因为AOF方式的持久化可能丢失的数据更少,可以在redis.conf中通过appendonly参数开启Redis AOF全持久化模式
在redis配置文件中有一下配置选项用来配置AOF
appendonly yes #开启AOF持久化
appendfilename "appendonly.aof" # 保存的文件名
# 将数据刷新到磁盘的策略
# appendfsync always # 只要有新数据就fsync
appendfsync everysec # 支持延迟fsync
# appendfsync no # 不需要fsync
no-appendfsync-on-rewrite no
# yes : 在日志重写时,不进行命令追加操作,而只是将其放在缓冲区里,避免与命令的追加造成DISK IO上的冲突。
# no : 在日志重写时,命令追加操作照常进行。
在默认情况下 当aof进行重写的时候,aof的同步信息不是关闭的。在这种情况下,子进程rewrite在写硬盘 主进程 aof也在写硬盘。在rewrite的过程中 子进程对主进程造成了磁盘阻塞(disk io冲突),导致了报警信息的产生。但是这个参数修改成 yes之后 ,又会有安全上的问题。当rewrite的过程中 要是redis down掉的话 丢失的数据 就不是之前appendfsync 定下的策略,而是整个 rewrite 过程中的所有数据。
auto-aof-rewrite-percentage 100 # 自动rewrite增量值
auto-aof-rewrite-min-size 64mb # 自动rewrite,AOF文件最小字节数
aof-rewrite-incremental-fsync yes
2)AOF rewrite AOF的重写机制
Redis触发AOF rewrite机制有三种:
- Redis Server接收到客户端发送的BGREWRITEAOF指令请求,如果当前AOF/RDB数据持久化没有在执行,那么执行,反之,等当前AOF/RDB数据持久化结束后执行AOF rewrite
- 在Redis配置文件redis.conf中,用户设置了auto-aof-rewrite-percentage和auto-aof-rewrite-min-size参数,并且当前AOF文件大小server.aof_current_size大于auto-aof-rewrite-min-size(server.aof_rewrite_min_size),同时AOF文件大小的增长率大于auto-aof-rewrite-percentage(server.aof_rewrite_perc)时,会自动触发AOF rewrite
- 用户设置“config set appendonly yes”开启AOF的时,调用startAppendOnly函数会触发rewrite
AOF文件刷新的方式,有三种,参考配置参数appendfsync:
- appendfsync always每提交一个修改命令都调用fsync刷新到AOF文件,非常非常慢,但也非常安全;
- appendfsync everysec每秒钟都调用fsync刷新到AOF文件,很快,但可能会丢失一秒以内的数据;
- appendfsync no依靠OS进行刷新,redis不主动刷新AOF,这样最快,但安全性就差。默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾。
3)AOF文件修复
可能由于系统原因导致了AOF损坏,redis无法再加载这个AOF,可以按照下面步骤来修复:
- 首先做一个AOF文件的备份,复制到其他地方;
- 修复原始AOF文件,执行:$ redis-check-aof –fix ;
- 可以通过diff –u命令来查看修复前后文件不一致的地方;
- 重启redis服务。
最后,为以防万一(机器坏掉或磁盘坏掉),记得定期把使用 filesnapshotting 或 Append-only 生成的*rdb *.aof文件备份到远程机器上。我是用crontab每半小时SCP一次。我没有使用redis的主从功能 ,因为半小时备份一次应该是可以了,而且我觉得有如果做主从有点浪费机器。这个最终还是看应用来定了。
3、redis半持久化RDB切换AOF
半持久化RDB模式也是Redis备份默认方式,是通过快照(snapshotting)完成的,当符合在Redis.conf配置文件中设置的条件时Redis会自动将内存中的所有数据进行快照并存储在硬盘上,完成数据备份。
Redis进行RDB快照的条件由用户在配置文件中自定义,由两个参数构成:时间和改动的键的个数。当在指定的时间内被更改的键的个数大于指定的数值时就会进行快照。
在配置文件中已经预置了3个条件:
- save 900 1 #900秒内有至少1个键被更改则进行快照;
- save 300 10 #300秒内有至少10个键被更改则进行快照;
- save 60 10000 #60秒内有至少10000个键被更改则进行快照。
保存的时间和次数进行调整时需要根据业务需求进行调整,保存的时间差越短,消耗的CPU越高,占用内存也会越高,redis 占用服务器端的内存最好不要超过%60-70%。
Redis默认会将快照文件存储在Redis数据目录,默认文件名为:dump.rdb文件,可以通过配置dir和dbfilename两个参数分别指定快照文件的存储路径和文件名。也可以在Redis命令行执行config get dir获取Redis数据保存路径
redis除了自动快照,还可以手动发送SAVE和BGSAVE命令让Redis执行快照,两个命令的区别在于save命令由主进程进行快照操作,保存过程Redis主进程会阻塞住其他请求,导致redis 不能接受新的客户端数据。
BGSAVE 命令会通过fork一个新的子进程进行快照操作,不会影响redis 主进程进行客户端数据的接受。
生产环境中都是使用bgsave 保存数据。
================================================================================================================================
rdb 文件想要保存持久数据,定时备份RDB文件来实现Redis数据库备份。
在 Redis 2.2 或以上版本,可以在不重启的情况下,从 RDB 切换到 AOF :
步骤 1:
为最新的 dump.rdb 文件创建一个备份,将备份放到一个安全的地方。
执行以下两条命令:
redis-cli> CONFIG SET appendonly yes
redis-cli> CONFIG SET save ""
确保命令执行之后,数据库的键的数量没有改变,确保写命令会被正确地追加到 AOF 文件的末尾。
注释:
执行的第一条命令开启了 AOF 功能: Redis 会阻塞直到初始 AOF 文件创建完成为止, 之后 Redis 会继续处理命令请求, 并开始将写入命令追加到 AOF 文件末尾。
执行的第二条命令用于关闭 RDB 功能。 这一步是可选的, 如果你愿意的话, 也可以同时使用 RDB 和 AOF 这两种持久化功能
Redis集群部署与维护的更多相关文章
- Redis集群部署及命令
一.简介 redis集群是一个无中心的分布式Redis存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用.可扩展等问题. redis集群提供了以下两个好处: 将数据自动切分(split) ...
- Redis集群部署-windows
Redis集群部署-windows 前言 为了能体验一下部署Redis集群是一种怎么样的体验,所一边做一边写了这篇记录. 1.准备 从这里下载windows服务端 https://github.com ...
- Redis集群部署文档(Ubuntu15.10系统)
Redis集群部署文档(Ubuntu15.10系统)(要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如 ...
- Redis集群部署3.0
我用的Mac的终端 ------------------------- 1.Redis简介 centos(5.4) Redis是一个key-value存储系统.和Memcached类似,但是解决了断 ...
- 二进制redis集群部署
二进制redis集群部署 〇.前言 无聊想学罢了 准备环境: 三台centos7 1C1GB即可 三个路相连的地址 主机 IP 节点-角色-实例(端口) redis1 172.16.106.128 M ...
- redis集群部署之codis 维护脚本
搞了几天redis cluster codis 的部署安装,测试,架构优化,配合研发应用整合,这里记一些心得! 背景需求: 之前多个业务都在应用到redis库,各业务独立占用主从两台服务器,硬件资源利 ...
- Docker网络讲解 及实验redis集群部署
理解docker0 准备工作:清空所有的容器,清空所有的镜像 docker rm -f $(docker ps -a -q) # 删除所有容器 docker rmi -f $(docker image ...
- Redis集群部署
1.1.1redis简介 Redis 是一个开源的使用 ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志 型. Key-Value数据库 1.1.2redis常见使用场景 1.会话缓存(S ...
- redis集群部署那点事
[CentOS]make cc Command not found,make: *** [adlist.o] Error 127” 参考:https://blog.csdn.net/wzygis/ar ...
随机推荐
- 学到了林海峰,武沛齐讲的Day17完-6 文件操作
参考 https://www.cnblogs.com/linhaifeng/articles/5984922.html f=open('陈粒1',encoding='utf-8') ope ...
- learning scala regular expression patterns
package com.aura.scala.day01 import scala.util.matching.Regex object regularExpressionPatterns { def ...
- QVariantMap 和 QVariant
typedef QVariantMap Synonym for(同义词) QMap<QString, QVariant>. QVariant类型的放入和取出必须是相对应的,你放入一个int ...
- [Luogu] 仓鼠找sugar
https://www.luogu.org/problemnew/show/3398 树剖练习题,两个懒标记,搜索时序为全局懒标记 #include <bits/stdc++.h> usi ...
- 【概率论】5-2:伯努利和二项分布(The Bernoulli and Binomial Distributions)
title: [概率论]5-2:伯努利和二项分布(The Bernoulli and Binomial Distributions) categories: - Mathematic - Probab ...
- avalon background-image写法
ms-css="{backgroundImage: 'url('+reportdata.avatar + ')'}"
- 正确处理listview的position
当ListView包含有HeaderView或FooterView时,传入getView或者onItemClick的position是怎样的,这是个值得探讨的问题 先列出错误的用法 定义: priva ...
- x2goserver 连接问题
The remote proxy closed the connection while negotiating the session. This may be due to the wrong a ...
- C语言--输入输出格式
一.PTA实验作业 题目1:7-3 温度转换 本题要求编写程序,计算华氏温度150°F对应的摄氏温度.计算公式:C=5×(F−32)/9,式中:C表示摄氏温度,F表示华氏温度,输出数据要求为整型. 1 ...
- php手记之04-tp5数据库操作
//--------查询// 原生sql语句查询 // $ret = Db::query("select * from tp5_user where id>10"); // ...