前世今生:Hive、Shark、spark SQL
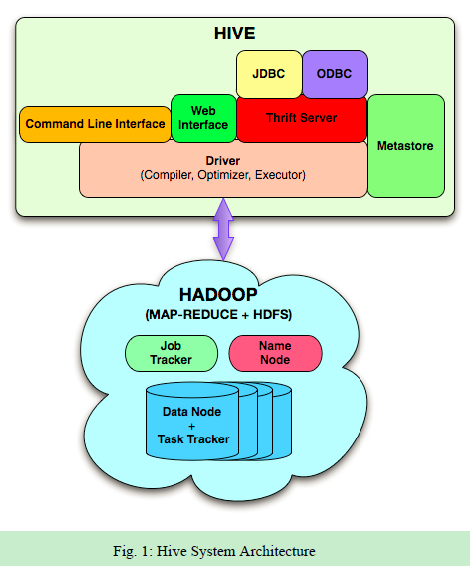
Apache Hive是一个构建在Hadoop上的数据仓库框架,它提供数据的概要信息、查询和分析功能。最早是Facebook开发的,现在也被像Netflix这样的公司使用。Amazon维护了一个为自己定制的分支。
- 加速用的索引功能(有什么特别的?)
- 不同的存储类型文件,例如plain text, RCFile, HBase, ORC, and others.
- 元数据保存在关系数据库中,默认是(Apache Derbydatabase),可替换为Mysql等;
- 可对hadoop生态系统的压缩数据操作,支持多种算法:gzip, bzip2, snappy, etc.
- 内置UDF(自定义函数)
- 类SQL查询,是转换为Mapreduce执行的。
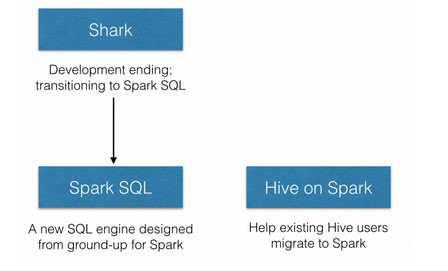
Shark将停止开发,而Spark SQL将取代并兼容Shark 0.9的所有功能,并提供额外的功能。
- 性能不佳;
- 为了执行交互查询,需要部署昂贵且私有的数据仓库,且这些数据仓库(EDWs )需要严格而冗长的ETL处理。
前世今生:Hive、Shark、spark SQL的更多相关文章
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
- Spark SQL读取hive数据时报找不到mysql驱动
Exception: Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BoneC ...
- spark SQL概述
Spark SQL是什么? 何为结构化数据 sparkSQL与spark Core的关系 Spark SQL的前世今生:由Shark发展而来 Spark SQL的前世今生:可以追溯到Hive Spar ...
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
- Spark SQL | 目前Spark社区最活跃的组件之一
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器.查询优化器等,制约了Spark各个组件之间的相互集成,因此S ...
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
随机推荐
- 使用docker搭建OpenResty开发环境
Dockerfile文件: FROM centos:latest RUN yum install -y pcre-devel openssl-devel gcc curl wget perl make ...
- A query was run and no Result Maps were found for...原来是mapper.xml文件出了问题,是使用MyBatis最常见的一种错误
今天遇到一个问题,原来是mapper.xml文件出了问题,是使用MyBatis最常见的一种错误 报错的结果是这样的: A query was run and no Result Maps were f ...
- 学习--Spring IOC源码精读
Spring核心IOC的源码分析(转载) 原文地址:https://javadoop.com/post/spring-ioc#toc11 转载地址:https://blog.csdn.net/nuom ...
- sql注入搞事情(连载一)
SQL注入搞事情(连载一) 概述 写在最前面 为了有个合理的训练计划,山人准备长期开放自己的训练计划以及内容以供大家参考.山人专业是信息对抗技术,不是web方向的博客保证句句手打,如有问题请及时小窗. ...
- Oracle子句【group by、having】
[分组查询]关键字:group by 分组字段名,分组字段名... --注意1:分组后,在select语句中只允许出现分组字段和多行函数 --注意2:如果是多字段分组,先按第一字段分组,然后每个小组继 ...
- bootstap 表格自动换行 截取超长数据
<table class="table" style="TABLE-LAYOUT:fixed;WORD-WRAP:break_word">
- 简单粗暴 每个servlet之前都插入一段代码解决 乱码问题
response.setHeader("content-type", "text/html;charset=UTF-8"); response.setChara ...
- Linux根文件系统和目录结构及bash特性3
bash的基础特性: 命令补全: shell程序在接收到用户执行命令的请求,分析完成之后,最左侧的字符串会被当作命令 命令查找机制: 查找内部命令 ...
- Ubuntu 18.04 启动太慢不能忍
检查谁在搞鬼 $ systemd-analyze blame 结果 39.828s plymouth-quit-wait.service 39.311s apt-daily.service 30.93 ...
- laravel中遇到的坑
已经遇到的坑和未来可能遇到的坑都将在这里写出来: 在资源控制器中创建新的方法后(如果资源控制器中的7个方法无法满足你的需求时,你就会创建新的方法),接下来就是创建路由,这个时候注意了,你必须要把路由放 ...