丑陋的 shell 来一遍
学习使人进步,好记性不如烂笔头
^(.)(.).*?\2\1$
正式开始总结
cat 反过来读取文件 tac file.txt
nl --> number line 如 cat file.txt|nl 行号提前
获得完整的文件路径
readlink -f file.txt
使用正则表达式重命名所选文件
rename 's/.bak$/.txt/' *.bak
每一秒监控
watch -n 1 "ls -alh"
free -s 1 -h
使用一个端口杀死程序
sudo fuser -k 8000/tcp
# 打印无限循环的文本 don't do it !!!
yes yes hello
检测权限错误是很有用的,例如在配置web服务器时。
namei -l /path/to/file.txt
# 不是很懂。。。每次修改文件时都会执行命令
while inotifywait -e close_write document.texdo makedone
复制到剪贴板
cat file.txt | xclip -selection clipboard
统计 ls 命令 资源使用情况
/usr/bin/time -v ls
shuffle file
cat file.txt | sort -R | head
# 超时 命令
timeout 2s find . iname "test*.sh"
从两个排序文件中合并行
comm file1 file2
在文件中分割长文件,使用相同数量的行
split -l LINES -d file.txt output_prefix
如果一个程序消耗了太多的内存,交换分区就会被剩余的内存填满,当你回到正常的时候,一切都是缓慢的。只需重新启动交换分区来修复它:
sudo swapoff -asudo swapon -a
# 创建一个 指定大小文件 跟 dd 区别是啥?
fallocate -l 1k test.ttt
cat >>a.txt << "EOF"
技巧三、用命令行递归方式全局搜索目录文件和替换
如果你使用Eclipse,ItelliJ或其它IDE,这些工具的强大重构能力也许会让你轻松实现很多事情。但我估计很多时候你的开发环境中没有这样的集成工具。
如何使用命令行对一个目录进行递归搜索和替换?别想Perl语言,你可以使用find and sed。感谢Stack Overflow提供的指导:
# OSX version
find . -type f -name '*.txt' -exec sed -i '' s/this/that/g {} +
使用了一段时间后,我总结写出了一个函数,添加入了 .bashrc ,就像下面这样:
function sr {
find . -type f -exec sed -i '' s/$1/$2/g {} +
}
你可以像这样使用它:
sr wrong_word correct_word
/pattern 向后搜索字符串pattern
?pattern 向前搜索字符串pattern
"\c" 忽略大小写
"\C" 大小写敏感
/SUM\c # 忽略大小写 查找 SUM sum
# 然后 可以 N,n 上下查找
n 下一个匹配(如果是/搜索,则是向下的下一个,?搜索则是向上的下一个)
N 上一个匹配(同上)
:%s/old/new/g 搜索整个文件,将所有的old替换为new
:%s/old/new/gc 搜索整个文件,将所有的old替换为new,每次都要你确认是否替换
:3,10s/fi/end/gc
:%s/fi/end/gc
sed '1,10s/sum/new_sum/g' test1.sh
sed -E 's/<\/?([a-z]*)>/\1/g' test.html
sed -E 's/[<>\/]//g' test.html
1、在命令模式下输入":sh",可以运行相当于在字符模式下,到输入结束想回到VIM编辑器中用exit,ctrl+D返回VIM编辑器
文件内容:
987-123-4567
123 456 7890
(123) 456-7890
(001) 345-0000
(001) 345-00001
egrep '^(\([0-9]{3}\)\s|[0-9]{3}-)[0-9]{3}-[0-9]{4}$' file.txt
360 shell 进阶
# 变量 删除 (头部尾部开始) 替换 (类似于 sed )
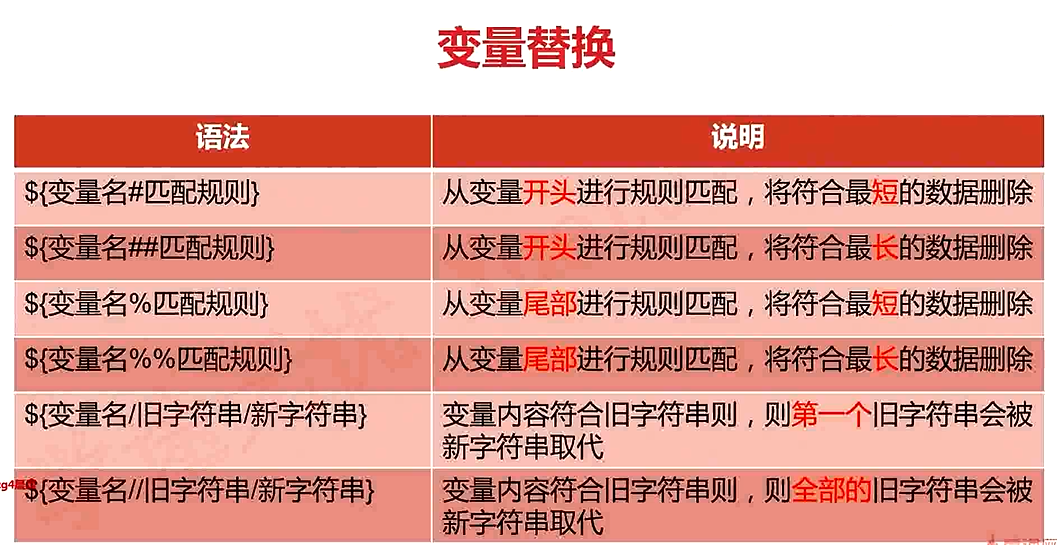
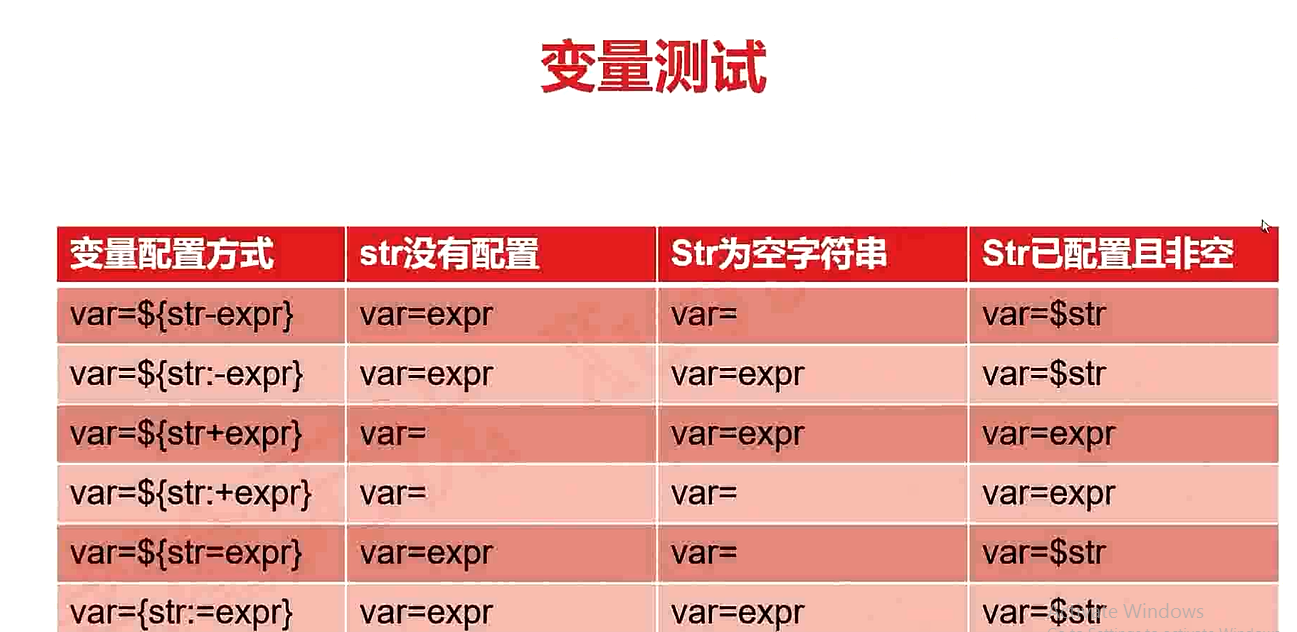
# 变量测试
“E576: viminfo: 缺少 '>' 位于行: ” 或者是“ E576: viminfo: Missing '>' in line: ”
rm ~/.viminfo # 干掉这个文件 就好
env | grep $PATH
rwx --> 111 111 111 == 777
110 110 100 = 664 自己与同组可以读写,其他只可以读
WildCard 通配符
export
unset
$(变量名) --》 取命令执行结果 echo $(`expr date`)
$((变量名)) --》 对变量执行算术运算
$[变量名] --》 对变量执行算术运算
$[2#10+3] --> 2 进制 10 + 3 = 2+3 = 5
cmd < file1 > file2
cmd < &fd 把文件描述符 fd 作为 标准输入
cmd > &fd 把文件描述符 fd 作为标准输出
cmd < &- 关闭
# basic 正则 简直是卧槽 , fuck!!!
grep '^\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}$' ip.txt
grep -E '^([0-9]{1,3}\.){3}[0-9]{1,3}$' ip.txt # 这玩意儿 就相当于 egrep 了
# extend 扩展正则
egrep '^([0-9]{1,3}\.){3}[0-9]{1,3}$' ip.txt
find . -maxdepth 1 -type f -size +2k -size -5k -print0|xargs -0 ls -alh # 从当前目录 递归深度1 查找 2-5k 区间内的 文件 并且以 \0做分割 然后 列表输出
dd if=/dev/zero of=test bs=1k count=3
在某种场景下,我们只想让文件系统认为存在一个超大文件在此,但是并不实际写入硬盘。
则可以
dd if=/dev/zero of=test bs=1M count=0 seek=100000
find . -maxdepth 1 -type f -size +2k -size -5k -exec rm {} \; # 不询问直接执行
find . -maxdepth 1 -type f -size +2k -size -5k -amin +2 -mtime +1 -ok rm {} \; # 对于每一个查找出来的进行询问
-atime 访问时间
-ctime 内容被修改时间
-mtime 文件属性被修改时间 以 天计算
-amin
-cmin
-mmin 以分钟计算
find . -maxdepth 1 -type f -iname "*test*" -mmin -$((24*60)) -print0|xargs -0 -i mv {} -t test/
awk 学习
product.txt
ProductA 30
ProductB 76
ProductC 55
awk -F " " '{if($2>50) print $0}' product.txt
awk -F " " '$2>75 {printf "%s %s\n", $0,"reorder"} $2<=75 {printf "%s \n", $0}' product.txt
awk '/^ *$/{cnt=cnt+1} END {printf("cnt is %d\n",cnt)}' test1.sh
awk '/^ *$/{cnt=cnt+1} END {printf("in file: %s cnt is %d\n",FILENAME,cnt)}' test1.sh
# linux 七种文件类型
占用存储空间的类型:文件、目录、符号链接。符号链接记录的是路径,路径不长时存在innode里面。
其他四种:套接字、块设备、字符设备、管道是伪文件,不占用磁盘空间。
-f file
-d directory
-p pipe
-s socket
-c character
-b block
-l link
# 小模板
#!/bin/sh
test_func(){
echo "test func"
}
main_func(){
echo "main func"
}
#echo $#
#echo $1
if [ $# -ge 1 ]; then
if [ $1 = "test" -o $1 = "Test" ]; then
test_func
else
main_func
fi
else
main_func
fi
#!/bin/sh
sum(){
sum=0
for i in `seq 1 "$1"`; do
if [ $[i%2] -eq 0 ]; then
continue
fi
sum=$[sum+i]
done
echo "sum is $sum"
return
}
sum $1
man 2 syscalls # 2 --》 系统调用 3 --》 公共库函数
查看当前 shell --> echo $SHELL
查看系统支持的 shell --》 cat /etc/shells
切换shell chsh -s /bin/bash
find ~ -iname "test*" # 忽略大小写 模糊匹配查找文件
grep 'genename_' genename_combination.csv |grep -o 'genename_exon_HIGH_[A-Z]*' # -o 表示 only match
awk -F"," 'NR==1 {print NF}' genename_combination.csv # 查看第一行有多少列
grep -o "genename_exon_HIGH_[A-Z0-9]*" genename_combination.csv |awk '{genenamearr[$1]++} END {for (i in genenamearr) print i, genenamearr[i]}'
grep -o "genename_exon_HIGH_[A-Z0-9]*" genename_combination.csv |awk '{genenamearr[$1]++} END {for (i in genenamearr) print i, genenamearr[i]}'|sort -rnk 2
grep -o "genename_exon_HIGH_[A-Z0-9]*" genename_combination.csv |awk '{genenamearr[$1]++} END {for (i in genenamearr) print i, genenamearr[i]}'|sort -rnk 2 -t : -o gene_statistics.txt
sed -i 's/^str/String/' ttt.txt
# 替换 删除 正则复杂用 sed , 表格文件用 awk , 简单文本处理用 grep




# -*- coding: utf-8 -*-
#!/bin/sh
通过 set 命令来查看 环境变量
name='frank'
echo ${name}
使用unset命令可以删除变量,变量被删除后不能再次使用,同时unset命令不能删除只读变量。
d=`date`
echo ${d:1:5}
demo.sh
#!/bin/bash
echo $0 # 文件名
echo $1 # 第一个参数
echo $2 # 第二个参数
echo $3 # 第三个参数
echo 'hello world!'
bash ./demo.sh aaa bbb ccc
demo.sh
aaa
bbb
ccc
hello world!
### YES_OR_NO 模板
! /bin/sh
read -p "请输入 Yes 或 No: " YES_OR_NO
case "${YES_OR_NO}" in
Y|y|YES|yes|Yes)
echo "your input value is: ${YES_OR_NO}" ;;
[Nn][Oo]|N|n)
echo "your input value is: ${YES_OR_NO}" ;;
*)
echo "others ..."
esac
# 基础综合
#!/bin/bash
a=10
readonly a
b=20
if [ $a -le $b ]
then
echo 'less than'
else
echo 'not less than'
fi
echo "a is ${a} , b is ${b}"
a=99
d=`date`
echo "$d 的长度是:${#d} 那我们来取出它的前三位${d:0:3}"
echo `expr index "${d}" Ju`
arr1=(1 2 3 4 'hello' 'world')
echo "${arr1[*]} 的长度为 ${#arr1[*]}"
for((i=0; i<=${#arr1[*]};i++))
do
(echo ${arr1[i]})
done
遍历数组
for((i=0;i<=${#arr[*]};i++)); do echo ${arr[i]}; done
读取输入参数
#!/bin/bash
#author Frank
#date 2019/06/09
#functionality: 用于熟悉 read 指令
#小结: -p 输入提示文字 -n 输入字符长度限制(达到3 位自动结束)
# -t 输入限时 5 秒 -s 隐藏输入内容
read -p "请输入两个参与运算的参数" -n 3 -t 5 -s param1 param2
sum=`expr ${param1} + ${param2}`
echo "您输入的两数之和为 ${sum}"
$ 的 作用即 取值
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi
printf 代替 echo ,记住格式化参数
test 和 中括号 [[]]
if test $[num1] -eq $[num2]
if [ $a == $b ]
i=`expr $i + 1`
let "i++"
for(( i=0;i<=5;i++))
do
echo $i
done
i=0;
while(( $i<5 ));
do echo $i;
i=`expr $i + 1`;
done
until (( $i>=5 ))
> do
> echo $i
> let "i++"
> done
#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字:"
read aNum
case $aNum in
1|2|3|4|5) echo "你输入的数字为 $aNum!"
;;
*) echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
break
;;
esac
done
case的语法和C family语言差别很大,它需要一个esac(就是case反过来)作为结束标记,每个case分支用右圆括号,用两个分号表示break。
标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
cat < aaa.sh >bbb.sh
cat << EOF
欢迎来到
菜鸟教程
www.runoob.com
EOF
nohup是永久执行
&是指在后台运行
运行 nohup --help
Run COMMAND, ignoring hangup signals. 可以看到是“运行命令,忽略挂起信号”
就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,例如我们断开SSH连接都不会影响他的运行,注意了nohup没有后台运行的意思;&才是后台运行
&是指在后台运行,但当用户推出(挂起)的时候,命令自动也跟着退出
那么,我们可以巧妙的吧他们结合起来用就是
nohup COMMAND &
这样就能使命令永久的在后台执行
. ./test.sh
source ./test.sh
被包含的文件 test1.sh 不需要可执行权限。
想想两者的区别
sum=`expr ${sum} + $i`
sum=$[$i+$sum]
#!/bin/bash
<<EOF
编写shell脚本,输入一个数字n并计算1~n的和。
要求:如果输入的数字小于1,则重新输入,直到输入正确的数字为止。
EOF
num=0
sum=0
while [[ $num<1 ]]
do
read -p "请输入一个不小于 1 的数字" num
for ((i=1;i<=$num;i++)){
sum=$[$i+$sum]
}
done
echo $sum
#!/bin/bash
read -p "input number:" a
read -p "input number:" b
read -p "input fuhao:" c
case $c in
+)let "sum=$a+$b"
echo $sum;;
-)let "sum=$a-$b"
echo $sum;;
*)let "sum=$a*$b"
echo $sum;;
/)let "sum=$a/$b"
echo $sum;;
esac
如何 debug shell
bashdb
sleep
sh -n ./test.sh
sh -x /.test.sh
作业一 修改扩展名
#!/bin/bash
path=$1
for i in `ls "$1"*.txt`
do
mv $i ${i%.txt}.text
done
作业二 定时删除或者归档日志文件
小结
- Shell 很实用
- Shell 的语法也很丑陋, 没有之一,如果有那就是 cmd or bat
cd – 回到上一次的目录
# 统计使用频率最高的 十条命令
history | awk '{CMD[$2]++;count++;} END { for (a in CMD )print CMD[a] " " CMD[a]/count*100 "% " a }' | grep -v "./" | column -c3 -s " " -t | sort -nr | nl | head -n10
vim scp://username@host//path/to/somefile
ps aux | sort -nk +4 | tail
du -s * | sort -n | tail
sudo kill -9 `ps -ef|grep ml-plugin-0.0.1-SNAPSHOT.jar|grep -v "grep"|awk '{print $2}'`
sudo ps -ef|grep ml-plugin-0.0.1-SNAPSHOT.jar|grep -v "grep"|awk '{print $2}'|xargs sudo kill -9
sudo kill $(ps -ef |grep jar|grep -v grep|awk '{print $2}')
find . -name '2019*.log' -type f -print|xargs sudo tar -cvzf test_log.tar.gz
yes|sudo rm test_log.tar.gz
cat urls.txt | xargs wget
请你要记得,第一个命令的输出会在 xargs 命令结尾处传递。
那如果命令需要中间过程的输出,该怎么办呢?这个简单!
只需要使用 {} 并结合 -i 参数就行了。如下所示,替换在第一个命令的输出应该去的地方的参数:
ls /etc/*.conf | xargs -i cp {} /home/likegeeks/Desktop/out
tail -fn0 logfile | \
while read line ; do
echo "$line" | grep "pattern"
if [ $? = 0 ]
then
... do something ...
fi
done
watch -n 1 -t "ps -ef|grep jar"
watch -n 1 -d "date"
netstat -tunlp|grep 8999
一个目录下文件及文件夹的个数:
ls | wc -w
一个目录下文件文件的个数:
ls -l | grep “^-” |wc -l
一个目录下文件文件夹的个数:
ls -l | grep “^d” |wc -l
统计当前文件夹下文件的个数,包括子文件夹里的:
ls -lR | grep “^-” |wc -l
ifconfig | grep eth | awk '{print $5}' #获取mac地址
find . -name '*.py' -print0 | xargs -0 ls -lt | head -20 # 最近修改的前二十个文件
实用主义
1) lsof -i -n | grep ESTABLISHED #查看连接状态的TCP链接2) ifconfig | grep eth | awk '{print $5}' #获取mac地址
3) find . -name '*pdf*' -print0 | xargs -0 ls -lt | head -20 #寻找最新修改的文件
4) rename "s/ *//g" *.jpg
#清除文件名中的空白5) grep -v "^\W$"
#匹配非空行6) ifdata -pN eth0
#获取ip地址7) pwgen -Bnyc
#生成安全的随机密码8) cat /proc/version
#显示发行版9) ls -ldct /lost+found |awk '{print $6, $7}'
#查看系统安装时间10) :> ui filename
#删除文件内容,但保留文件11) mtr google.com
#混合ping和traceroute的工具12) watch -n1 'ifconfig eth0|grep bytes'
#查看网络流量13) netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n
#显示连接到本机上的IP列表14)
echo SSBMb3ZlIFlvdQo= | base64 -d
#尝试一下,你就知道15) timeout 30s ping t.tt
#限时执行某项命令,d(天)/h(小时)/m(分钟)/s(秒)
16) dd if=/dev/urandom | tr -d -c [:print:] | tr -d " " | dd count=1 bs=8 2> /dev/null; echo
#随机创建一个八位的复杂密码17) alias mm='sh /root/job/passwd.sh'
#给执行命令语句或命令起个小名18) ls -R | grep -v keepfilename | xargs rm -Rf
#排除关键字后rm,切记grep后面加参数v,否则删除关键字文件19) dirname `pwd`
#获取当目录的父目录20) cal | egrep -e '^ [0-9]|^[0-9]' | tr '\n' ' ' | awk '{print $NF}' #显示当月最后一天是几号
序号 任务 命令组合
1 删除0字节文件 find . -type f -size 0 -exec rm -rf {} \; find . type f -size 0 -delete
2 查看进程,按内存从大到小排列 ps -e -o “%C : %p : %z : %a”|sort -k5 -nr
3 按cpu利用率从大到小排列 ps -e -o “%C : %p : %z : %a”|sort -nr
4 打印说cache里的URL grep -r -a jpg /data/cache/* | strings | grep “http:” | awk -F’http:’ ‘{print “http:”$2;}’
5 查看http的并发请求数及其TCP连接状态 netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’
6 sed在这个文里Root的一行,匹配Root一行,将no替换成yes。 sed -i ‘/Root/s/no/yes/’ /etc/ssh/sshd_config
7 如何杀掉mysql进程 ps aux |grep mysql |grep -v grep |awk ‘{print $2}’ |xargs kill -9 killall -TERM mysqld kill -9 `cat /usr/local/apache2/logs/httpd.pid`
8 显示运行3级别开启的服务(从中了解到cut的用途,截取数据) ls /etc/rc3.d/S* |cut -c 15-
9 如何在编写SHELL显示多个信息,用EOF cat << EOF +————————————————————–+ | === Welcome to Tunoff services === | +————————————————————–+ EOF
10 for的用法(如给mysql建软链接) cd /usr/local/mysql/bin for i in * do ln /usr/local/mysql/bin/$i /usr/bin/$i done
11 取IP地址 ifconfig eth0 |grep “inet addr:” |awk ‘{print $2}’|cut -c 6- ifconfig | grep ‘inet addr:’| grep -v ’127.0.0.1′ |cut -d: -f2 | awk ‘{ print $1}’
12 内存的大小 free -m |grep “Mem” | awk ‘{print $2}’
13 查看80端口的连接,并排序 netstat -an -t | grep “:80″ | grep ESTABLISHED | awk ‘{printf “%s %s\n”,$5,$6}’ | sort
14 查看Apache的并发请求数及其TCP连接状态 netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’
15 统计一下服务器下面所有的jpg的文件的大小 find / -name *.jpg -exec wc -c {} \;|awk ‘{print $1}’|awk ‘{a+=$1}END{print a}’
16 CPU的数量 cat /proc/cpuinfo |grep -c processor
17 CPU负载 cat /proc/loadavg
18 CPU负载 mpstat 1 1
19 内存空间 free
20 磁盘空间 df -h
21 如发现某个分区空间接近用尽,可以进入该分区的挂载点,用以下命令找出占用空间最多的文件或目录 du -cks * | sort -rn | head -n 10
22 磁盘I/O负载 iostat -x 1 2
23 网络负载 sar -n DEV
24 网络错误 netstat -i cat /proc/net/dev
25 网络连接数目 netstat -an | grep -E “^(tcp)” | cut -c 68- | sort | uniq -c | sort -n
26 进程总数 ps aux | wc -l
27 查看进程树 ps aufx
28 可运行进程数目 vmwtat 1 5
29 检查DNS Server工作是否正常,这里以61.139.2.69为例 dig www.baidu.com @61.139.2.69
30 检查当前登录的用户个数 who | wc -l
31 日志查看、搜索 cat /var/log/rflogview/*errors grep -i error /var/log/messages grep -i fail /var/log/messages tail -f -n 2000 /var/log/messages
32 内核日志 dmesg
33 时间 date
34 已经打开的句柄数 lsof | wc -l
35 网络抓包,直接输出摘要信息到文件。 tcpdump -c 10000 -i eth0 -n dst port 80 > /root/pkts
36 然后检查IP的重复数 并从小到大排序 注意 “-t\ +0″ 中间是两个空格,less命令的用法。 less pkts | awk {‘printf $3″\n”‘} | cut -d. -f 1-4 | sort | uniq -c | awk {‘printf $1″ “$2″\n”‘} | sort -n -t\ +0
37 kudzu查看网卡型号 kudzu –probe –class=network
在Unix/Linux下,高效工作方式不是操作图形页面,而是命令行操作,命令行意味着更容易自动化。使用过Linux系统的朋友应该都知道它的命令行强大之处。本文讲述了Linux下的查找,删除,打包,解压,查询及VIM等30个常用命令技巧
1、Vim自动添加注释及智能换行
# vi ~/.vimrc
set autoindent
set tabstop=4
set shiftwidth=4
function AddTitle()
call setline(1,"#!/bin/bash")
call append(1,"#====================================================")
call append(2,"# Author: lizhenliang")
call append(3,"# Create Date: " . strftime("%Y-%m-%d"))
call append(4,"# Description: ")
call append(5,"#====================================================")
endf
map <F4> :call AddTitle()<cr>
打开文件后,按F4就会自动添加注释,省了不少时间!
2、查找并删除/data这个目录7天前创建的文件
# find /data -ctime +7 -exec rm -rf {} \;
# find /data -ctime +7 | xargs rm -rf
3、tar命令压缩排除某个目录
# tar zcvf data.tar.gz /data --exclude=tmp #--exclude参数为不包含某个目录或文件,后面也可以跟多个
4 查看tar包存档文件,不解压
# tar tf data.tar.gz #t是列出存档文件目录,f是指定存档文件
5、使用stat命令查看一个文件的属性
访问时间(Access)、修改时间(modify)、状态改变时间(Change)
stat index.php
Access: 2018-05-10 02:37:44.169014602 -0500
Modify: 2018-05-09 10:53:14.395999032 -0400
Change: 2018-05-09 10:53:38.855999002 -0400
6、批量解压tar.gz
方法1:
# find . -name "*.tar.gz" -exec tar zxf {} \;
方法2:
# for tar in *.tar.gz; do tar zxvf $tar; done
方法3:
# ls *.tar.gz | xargs -i tar zxvf {}
7、筛除出文件中的注释和空格
方法1:
# grep -v "^#" httpd.conf |grep -v "^$"
方法2:
# sed -e ‘/^$/d' -e ‘/^#/d' httpd.conf > http.conf
或者
# sed -e '/^#/d;/^$/d' #-e 执行多条sed命令
方法3:
# awk '/^[^#]/|/"^$"' httpd.conf
或者
# awk '!/^#|^$/' httpd.conf
8、筛选/etc/passwd文件中所有的用户
方法1:
# cat /etc/passwd |cut -d: -f1
方法2:
# awk -F ":" '{print $1}' /etc/passwd
9、iptables网站跳转
先开启路由转发:
echo "1" > /proc/sys/net/ipv4/ip_forward #临时生效
内网访问外网(SNAT):
iptables –t nat -A POSTROUTING -s [内网IP或网段] -j SNAT --to [公网IP]
#内网服务器要指向防火墙内网IP为网关
公网访问内网(DNAT)(公网端口映射内网端口):
iptables –t nat -A PREROUTING -d [对外IP] -p tcp --dport [对外端口] -j DNAT --to [内网IP:内网端口]
#内网服务器要配置防火墙内网IP为网关,否则数据包回不来。另外,这里不用配置SNAT,因为系统服务会根据数据包来源再返回去。
10、iptables将本机80端口转发到本地8080端口
# iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
11、find命令查找文件并复制到/opt目录
方法1:
# find /etc -name httpd.conf -exec cp -rf {} /opt/ \;: #-exec执行后面命令,{}代表前面输出的结果,\;结束命令
方法2:
# find /etc -name httpd.conf |xargs -i cp {} /opt #-i表示输出的结果由{}代替
12、查看根目录下大于1G的文件
# find / -size +1024M
默认单位是b,可以使用其他单位如,C、K、M
13、查看服务器IP连接数
# netstat -tun | awk '{print $5}' | cut -d: -f1 |sort | uniq -c | sort -n
-tun:-tu是显示tcp和udp连接,n是以IP地址显示
cut -d:-f1:cut是一个选择性显示一行的内容命令,-d指定:为分隔符,-f1显示分隔符后的第一个字段。
uniq -c:报告或删除文中的重复行,-c在输出行前面加上出现的次数
sort -n:根据不同类型进行排序,默认排序是升序,-r参数改为降序,-n是根据数值的大小进行排序
14、插入一行到391行,包括特殊符号"/"
# sed -i "391 s/^/AddType application\/x-httpd-php .php .html/" httpd.conf
15、列出nginx日志访问最多的10个IP
方法1:
# awk '{print $1}' access.log |sort |uniq -c|sort -nr |head -n 10
sort :排序
uniq -c:合并重复行,并记录重复次数
sort -nr :按照数字进行降序排序
方法2:
# awk '{a[$1]++}END{for(v in a)print v,a[v] |"sort -k2 -nr |head -10"}' access.log
16、显示nginx日志一天访问量最多的前10位IP
# awk '$4>="[16/May/2017:00:00:01" && $4<="[16/May/2017:23:59:59"' access_test.log |sort |uniq -c |sort-nr |head -n 10
# awk '$4>="[16/Oct/2017:00:00:01" && $4<="[16/Oct/2017:23:59:59"{a[$1]++}END{for(i in a){print a[i],i|"sort -k1 -nr |head -n 10"}}' access.log
17、获取当前时间前一分钟日志访问量
# date=`date +%d/%b/%Y:%H:%M --date="-1 minute"` ; awk -vd=$date '$0~d{c++}END{print c}' access.log
# date=`date +%d/%b/%Y:%H:%M --date="-1 minute"`; awk -vd=$date '$4>="["d":00" && $4<="["d":59"{c++}END{print c}' access.log
# grep `date +%d/%b/%Y:%H:%M --date="-1 minute"` access.log |awk 'END{print NR}'
# start_time=`date +%d/%b/%Y:%H:%M:%S --date="-5 minute"`;end_time=`date +%d/%b/%Y:%H:%M:%S`;awk -vstart_time="[$start_time" -vend_time="[$end_time" '$4>=start_time && $4<=end_time{count++}END{print count}' access.log
18、找出1-255之间的整数
方法1:
# ifconfig |grep -o '[0-9]\+' #+号匹配前一个字符一次或多次
方法2:
# ifconfig |egrep -o '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
19、找出IP地址
# ifconfig |grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' #-o只显示匹配字符
20、给文档增加开头和结尾说明信息
# awk ‘BEGIN{print "开头显示信息"}{print $1,$NF} END{print "结尾显示信息"}'/etc/passwd
# awk 'BEGIN{printf " date ip\n------------------\n"} {print $3,$4} END{printf "------------------\nend...\n"}' /var/log/messages
date ip
------------------
03:13:01 localhost
10:51:45 localhost
------------------
end...
21、查看网络状态命令
# netstat -antp #查看所有网络连接
# netstat -lntp #只查看监听的端口信息
# lsof -p pid #查看进程打开的文件句柄
# lsof -i:80 #查看端口被哪个进程占用
22、生成8位随机字符串
方法1:
# echo $RANDOM |md5sum |cut -c 1-8
方法2:
# openssl rand -base64 4
方法3:
# cat /proc/sys/kernel/random/uuid | cut -c 1-8
23、while死循环
while true; do #条件精确等于真,也可以直接用条件[ "1" == "1" ],条件一直为真
ping -c 2 www.baidu.com
done
24.awk格式化输出
将文本列进行左对齐或右对齐。
左对齐:
# awk '{printf "%-15s %-10s %-20s\n",$1,$2,$3}' test.txt
右对齐:
# awk '{printf "%15s %10s %20s\n",$1,$2,$3}' test.txt
25.整数运算保留小数点
方法1:
# echo 'scale=2; 10/3;'|bc #scale参数代表取小数点位数
方法2:
# awk BEGIN'{printf "%.2f\n",10/3}'
26.数字求和
# cat a.txt
方法1:
#!/bin/bash
while read num;
do
sum=`expr $sum + $num`
done < a.txt
echo $sum
方法2:
# cat a.txt |awk '{sum+=$1}END{print sum}'
27、判断是否为数字(字符串判断也如此)
# [[ $num =~ ^[0-9]+$ ]] && echo yes || echo no #[[]]比[]更加通用,支持模式匹配=~和字符串比较使用通配符`
^ $:从开始到结束是数字才满足条件
=~:一个操作符,表示左边是否满足右边(作为一个模式)正则表达式
28、删除换行符并将空格替换别的字符
# cat a.txt |xargs echo -n |sed 's/[ ]/|/g' #-n 不换行
# cat a.txt |tr -d '\n' #删除换行符
29、查看文本中20至30行内容(总共100行)
方法1:
# awk '{if(NR > 20 && NR < 31) print $0}' test.txt
方法2:
# sed -n '20,30p' test.txt
方法3:
# head -30 test.txt |tail
30、文本中两列位置替换
# cat a.txt
60.35.1.15 www.baidu.com
45.46.26.85 www.sina.com.cn
# awk '{print $2"\t"$1}' a.txt
head -n 1 filtered_dataset_576.csv|awk -F ',' '{print NF}'
watch -n 1 'ls -l|grep 355'
watch -n 1 'free -h'
free -s 10 -h
源码安装 expect
Expect是在Tcl基础上创建起来的,它还提供了一些Tcl所没有的命令,它可以用来做一些linux下无法做到交互的一些命令操作,在远程管 理方面发挥很大的作用。
spawn命令激活一个Unix程序来进行交互式的运行。
send命令向进程发送字符串。
expect 命令等待进程的某些字符串。
expect支持正规表达式并能同时等待多个字符串,并对每一个字符串执行不同的操作.
A. Tcl 安装
主页: http://www.tcl.tk
下载地址: http://www.tcl.tk/software/tcltk/downloadnow84.tml
1.下载源码包
wget http://nchc.dl.sourceforge.net/sourceforge/tcl/tcl8.4.11-src.tar.gz
2.解压缩源码包
tar xfvz tcl8.4.11-src.tar.gz
3.安装配置
cd tcl8.4.11/unix
./configure --prefix=/usr/tcl --enable-shared
make
make install
安装完毕以后,进入tcl源代码的根目录,把子目录unix下面的tclUnixPort.h copy到子目录generic中。
暂时不要删除tcl源代码,因为expect的安装过程还需要用。
B. expect 安装 (需Tcl的库)
主页: http://expect.nist.gov/
1.下载源码包
wget https://liquidtelecom.dl.sourceforge.net/project/expect/Expect/5.45.4/expect5.45.4.tar.gz
2.解压缩源码包
tar xzvf expect5.45.tar.gz
3.安装配置
cd expect5.45
./configure --prefix=/usr/expect --with-tcl=/usr/tcl/lib --with-tclinclude=../tcl8.4.11/generic
make
make install
ln -s /usr/tcl/bin/expect /usr/expect/bin/expect
交互式 demo 小例子
#!/bin/bash
read -p "host: " host
read -p "db name: " dbName
read -p "db user: " dbUser
read -p "db password: " dbPassword
host=${host:-xxx}
dbName=${dbName:-xxx}
dbUser=${dbUser:-pgxxx}
dbPassword=${dbPassword:-xxx}
expect << EOF
spawn psql -h ${host} -U ${dbUser} -d ${dbName} -p 5432
expect "Password*"
send "${dbPassword}\r"
expect "psql*"
interact
EOF
& 与 nohup 的 区别
ctrl + c 产生SIGINT信号,关闭shell窗口产生SIGHUP信号
可以看到即使我们使用了ctrl + c ,storm的nimbus进程也依旧存活,但是当我们关掉当前shell窗口的话,进程就会被杀死。因为&只对SIGINT信号免疫,而对SIGHUP信号不免疫
nohup的意思是忽略SIGHUP信号
可见nohup对SIGINT信号并不免疫。
总而言之 & 意味着 免疫 ctrl+c 发送的 SIGINT 信号
nohup 免疫 窗口关闭 产生的 SIGHUP 信号
为了方便生活
sudo ln -s /home2/ray/anaconda/envs/py37/bin/python /usr/bin/python37
# 获取本机 外网 ip 地址
curl ifconfig.me
curl icanhazip.com
curl curlmyip.com
curl ip.appspot.com
curl ipinfo.io/ip
curl ipecho.net/plain
curl www.trackip.net/i
curl ip.sb
丑陋的 shell 来一遍的更多相关文章
- shell中各种括号的作用()、(())、[]、[[]]、{}
一.小括号,圆括号() 1.单小括号 () ①命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用.括号中多个命令之间用分号隔开,最后一个命令可以没有 ...
- Shell中的空格和引号
空格对于linux的shell是一种很典型的分隔符,所以给变量赋值的时候中间不能够有空格.而单引号和双引号,都是为了解决中间有空格的问题.比如string1=this is a string,这样执行 ...
- shell脚本中的几个括号总结(小括号/大括号/花括号)--from:http://www.cnblogs.com/hanyan225/archive/2011/10/06/2199652.html
在Shell中的小括号,大括号结构和有括号的变量,命令的用法如下: 1.${var}2.$(cmd)3.()和{}4.${var:-string},${var:+string},${var:=stri ...
- shell中括号的使用
在这里我想说的是几种shell里的小括号,大括号结构和有括号的变量,命令的用法,如下: 1.${var} 2.$(cmd) 3.()和{} 4.${var:-string},${var:+string ...
- Linux shell中的符号
.单小括号 () ①命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用. 括号中多个命令之间用分号隔开,最后一个命令可以没有分号,各命令和括号之间不必有空 ...
- Shell 编程基础之括号的作用
一.小括号() 单小括号 命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用.括号中多个命令之间用分号隔开,最后一个命令可以没有分号,各命令和括号之间不必 ...
- shell之小括号、中括号、大括号
1.Shell中变量的原形:${var} 一串命令的执行 #等价于 $ var=test $ echo $var test #例如,用在这个位置 $ echo ${var}AA testAA 2.命 ...
- shell 中各种括号的作用()、(())、[]、[[]]、{}
一.小括号,圆括号 () 1.单小括号 () 命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用.括号中多个命令之间用分号隔开,最后一个命令可以没有分号, ...
- shell入门(二):()、(())、[]、[[]]、{}
1.() 命令组. 括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用.括号中多个命令之间用分号’;’隔开,最后一个命令可以没有分号,各命令和括号之间不必有空格. ...
随机推荐
- HashMap三两事
前言 JDK8中对HashMap做了优化,依然是用数组存储数据,但是扩容时采用双链表的方式避免了高并发情况下导致出现循环链表的问题,另外也引入了红黑树,提高碰撞元素的搜索速度. 一段代码 下面这段代码 ...
- 一、基础篇--1.3进程和线程-CountDownLatch、CyclicBarrier 和 Semaphore
下面对上面说的三个辅助类进行一个总结: 1)CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同: CountDownLatch一般用于某个线程A等待 ...
- linux中的i2c控制器驱动应该做些什么?
答:完成读写功能即可,不要涉及任何针对从设备的特殊操作,这样就可以避免与从设备的代码产生冗余,linux中的i2c控制器驱动就做的特别棒,做好最简单的读写,然后其它的从设备驱动就是直接调用这些最简单的 ...
- 使用SlidingDrawer(滑动式抽屉)实现抽屉效果
SlidingDrawer隐藏屏外的内容,并允许用户通过handle以显示隐藏内容.它可以垂直或水平滑动,它有俩个View组成,其一是可以拖动的handle,其二是隐藏内容的View.它里面的控件必须 ...
- matplotlib展现混淆矩阵
1.展现混淆矩阵 import matplotlib.pyplot as plt import itertools def plot_confusion_matrix(cm, classes, tit ...
- mongodb增删改查操作
Note:mongodb存储的是文档,且文档是json格式的对象,所以增删改查都必须是json格式对象. 注:mongodb常用库和表操作,但mongodb在插入数据时,不需要先创建表. show d ...
- MyBatis Mapper Demo
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-/ ...
- 阶段3 3.SpringMVC·_04.SpringMVC返回值类型及响应数据类型_4 响应之返回值是ModelAndView类型
ModelAndView是SpringMvc提供的一个对象 ModelAndView底层源码用也是ModelMap.ModelMap实现过Model的接口 ModelAndView可以直接new出来. ...
- spring_quartz的实现
一.在spring配置文件中引用对应的定时任务配置文件 二.定义定时任务的业务代码 三.配置定时任务配置文件spring-quartz.xml <?xml version="1.0&q ...
- Void pointers in C
In this article we are learning about “void pointers” in C language. Before going further it will be ...