爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页
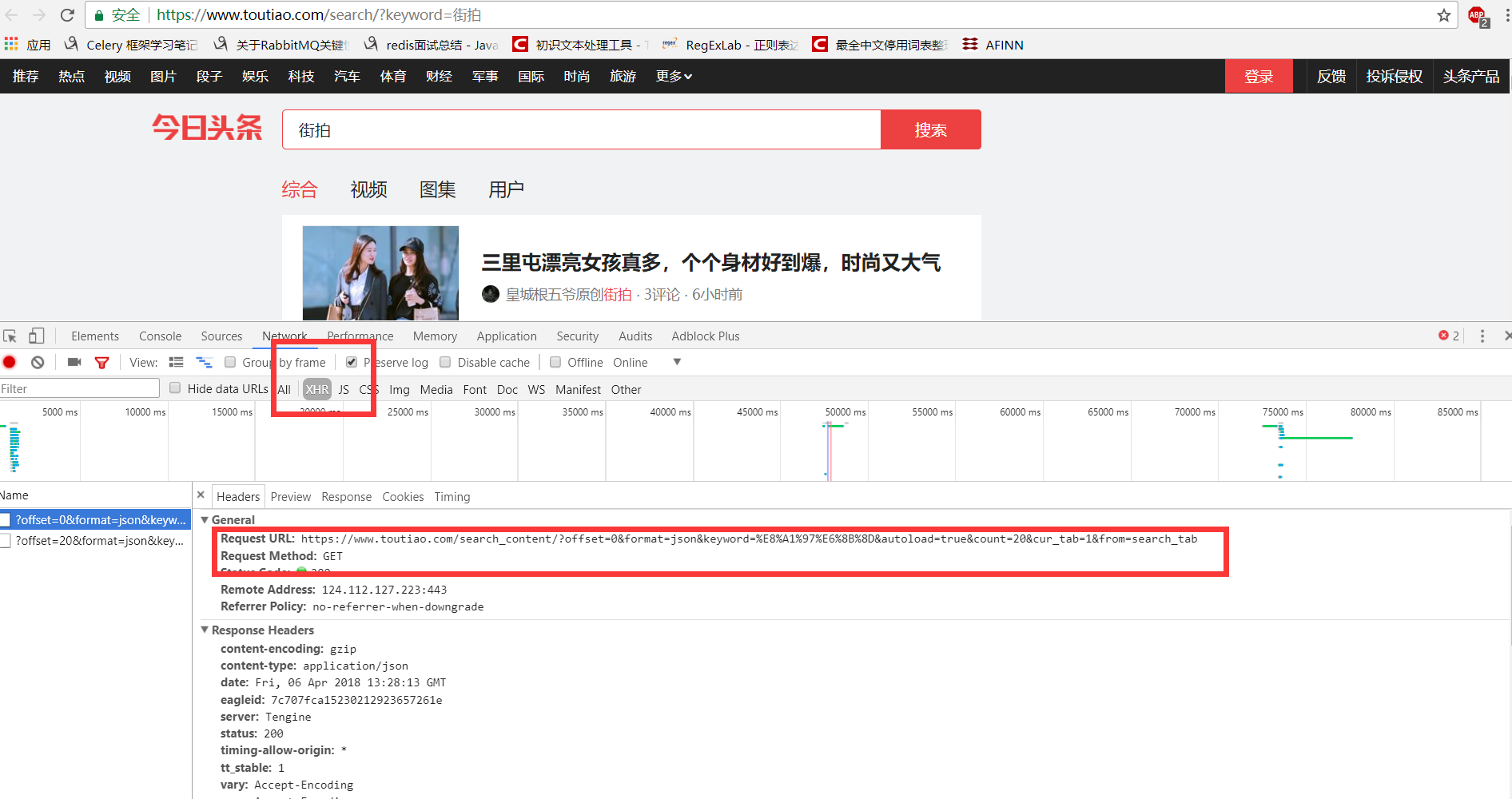
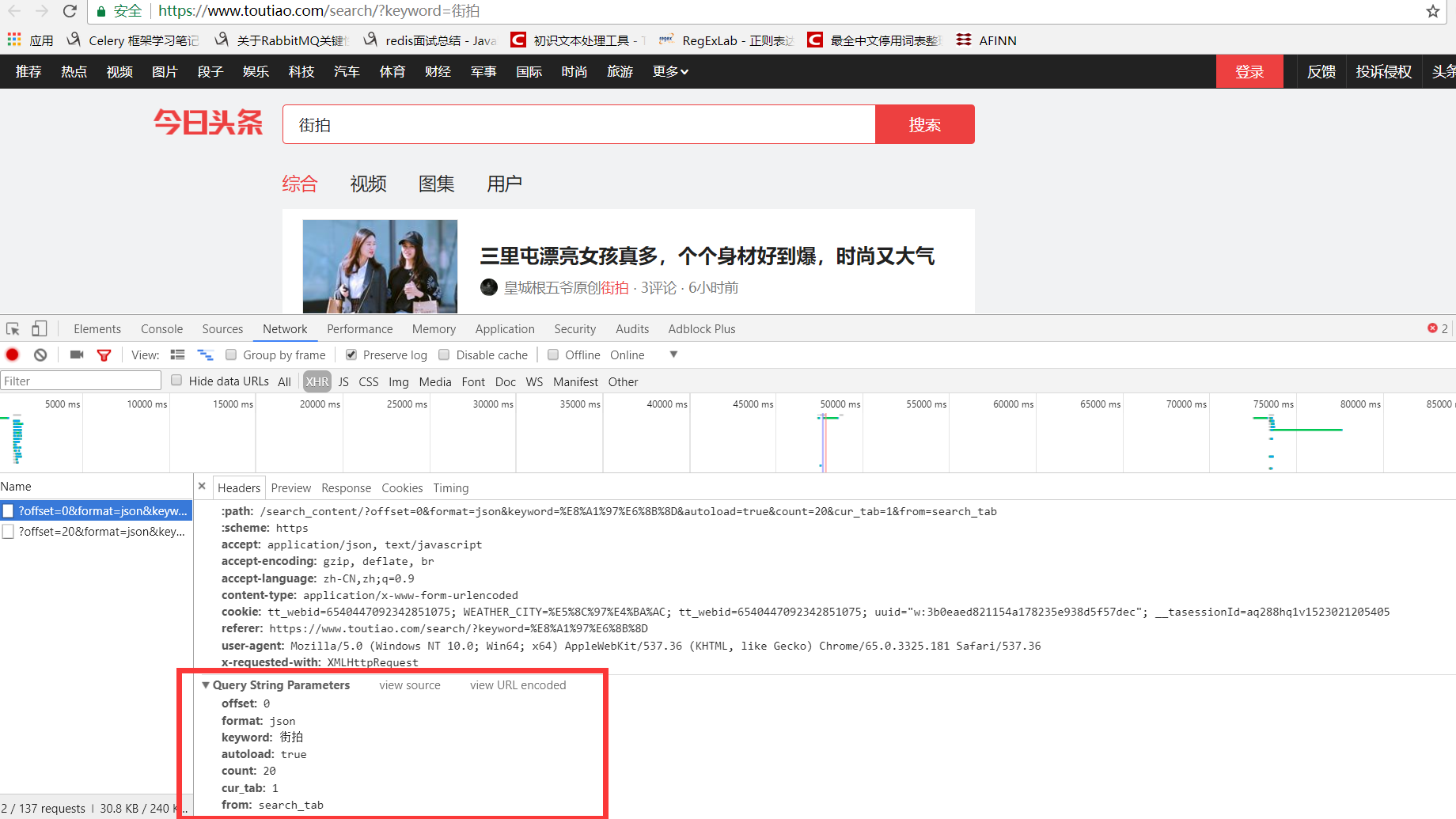
分析ajax的请求网址,和需要的参数。通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求。
(2)上代码
a、通过ajax请求获取页面数据
# 获取页面数据
def get_page_index(offset, keyword):
# 参数通过分析页面的ajax请求获得
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '',
'cur_tab': '',
'from': 'search_tab',
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 将字典转换为url参数形式
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('请求索引页错误')
return None
b、分析ajax请求的返回结果,获取图片集的url
# 分析ajax请求的返回结果,获取图片集的url
def parse_page_index(html):
data = json.loads(html) # 加载返回的json数据
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
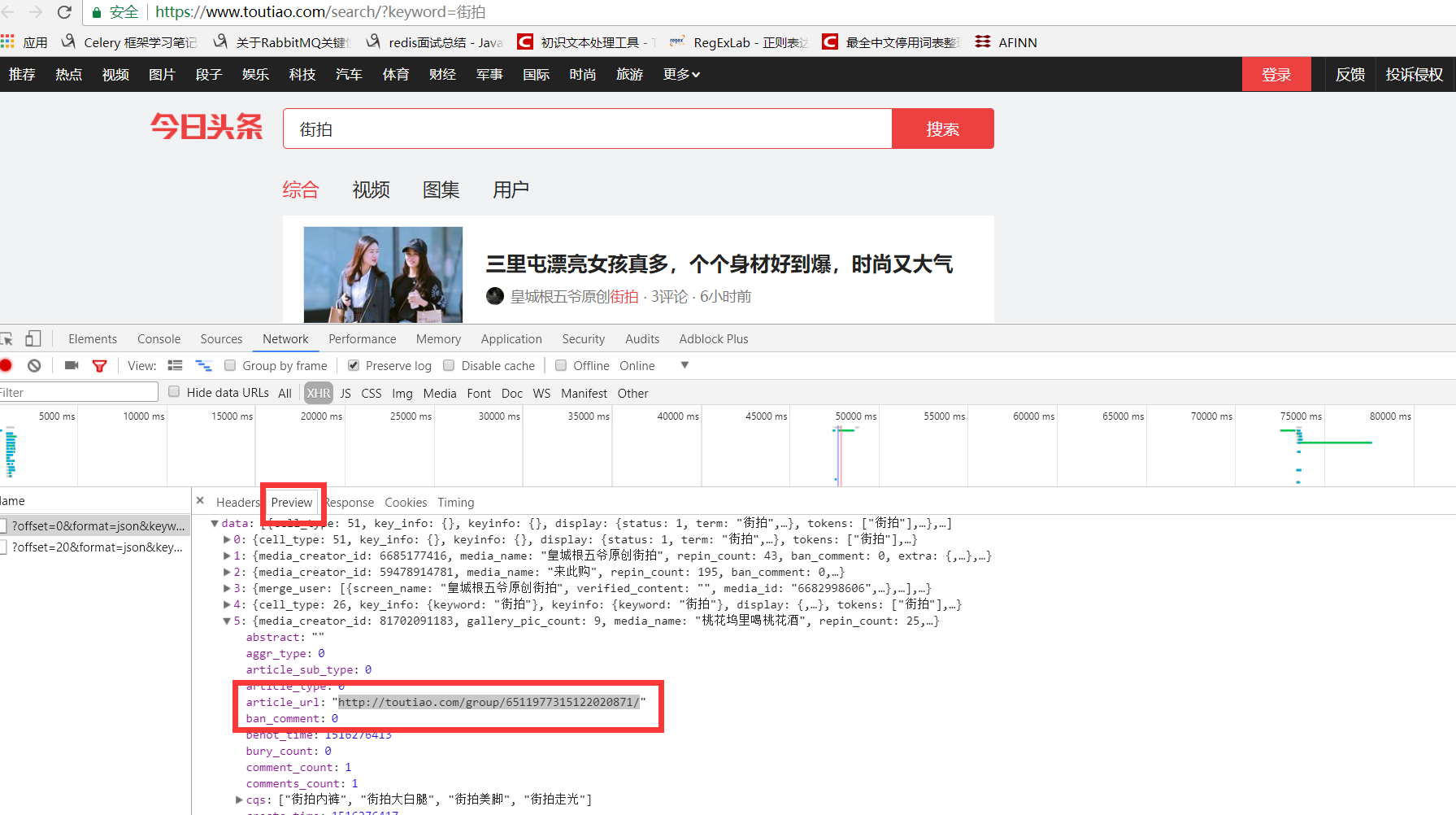
c、得到图集url后获取图集的内容
# 获取详情页的内容
def get_page_detail(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('详情页页错误', url)
return None
d、其他看完整代码
完整代码:
# -*- coding: utf-8 -*-
# @Author : FELIX
# @Date : 2018/4/4 12:49 import json import os
from hashlib import md5 import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import re
import pymongo
from multiprocessing import Pool MONGO_URL='localhost' MONGO_DB='toutiao' MONGO_TABLE='toutiao' GROUP_START=1
GROUP_END=20
KEYWORD='街拍' client = pymongo.MongoClient(MONGO_URL) # 连接MongoDB
db = client[MONGO_DB] # 如果已经存在连接,否则创建数据库 headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
} # 获取页面数据
def get_page_index(offset, keyword):
# 参数通过分析页面的ajax请求获得
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '',
'cur_tab': '',
'from': 'search_tab',
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 将字典转换为url参数形式
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('请求索引页错误')
return None # 分析ajax请求的返回结果,获取图片集的url
def parse_page_index(html):
data = json.loads(html) # 加载返回的json数据
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') # 获取详情页的内容
def get_page_detail(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('详情页页错误', url)
return None def parse_page_detail(html, url):
# soup=BeautifulSoup(html,'lxml')
# print(soup)
# title=soup.select('tetle').get_text()
# print(title)
images_pattern = re.compile('articleInfo:.*?title: \'(.*?)\'.*?content.*?\'(.*?)\'', re.S)
result = re.search(images_pattern, html)
if result:
title = result.group(1)
url_pattern = re.compile('"(http:.*?)"')
img_url = re.findall(url_pattern, str(result.group(2)))
if img_url:
for img in img_url:
download_img(img) # 下载
data = {
'title': title,
'url': url,
'images': img_url,
}
return data def save_to_mongo(result):
if result:
if db[MONGO_TABLE].insert(result): # 插入数据
print('存储成功', result)
return True
return False def download_img(url):
print('正在下载', url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
save_img(response.content)
else:
return None
except RequestException:
print('下载图片错误', url)
return None def save_img(content):
# os.getcwd()获取当前文件路径,用md5命名,保证不重复
file_path = '{}/imgs/{}.{}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb')as f:
f.write(content) def main(offset):
html = get_page_index(offset, KEYWORD)
for url in parse_page_index(html):
html = get_page_detail(url)
print(url,'++++++++++++++++++++++++++++++++++++++++++++++++')
print(html)
if html:
result = parse_page_detail(html, url)
save_to_mongo(result)
# print(result)
# print(url) if __name__ == '__main__':
groups = [i * 20 for i in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
爬虫(八):分析Ajax请求抓取今日头条街拍美图的更多相关文章
- python3爬虫-分析Ajax,抓取今日头条街拍美图
# coding=utf-8 from urllib.parse import urlencode import requests from requests.exceptions import Re ...
- 通过分析Ajax请求 抓取今日头条街拍图集
代码: import os import re import json import time from hashlib import md5 from multiprocessing import ...
- 分析Ajax来爬取今日头条街拍美图并保存到MongDB
前提:.需要安装MongDB 注:因今日投票网页发生变更,如下代码不保证能正常使用 #!/usr/bin/env python #-*- coding: utf-8 -*- import json i ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- 分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部: 在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url: 选中其中一张图片,分析 json 请 ...
随机推荐
- MyBatis Generator 自动生成的POJO对象的使用(二)
四.Example Class使用说明 示例类指定如何构建动态where子句. 表中的每个非BLOB列都可以选择包含在where子句中. 示例是演示此类用法的最佳方法. 示例类可用于生成几乎无限制的w ...
- Java内存模型学习笔记(一)—— 基础
1.并发编程模型的分类 在并发编程中,我们需要处理两个关键的问题:1.线程间如何通信,2.线程间如何同步.通信是指线程之间以何种机制来交换信息,同步是指程序用于不同线程之间操作发生相对顺序的机制. 在 ...
- GoLand中同一个目录下的package无法调用
代码结构: 三个代码的package 都是 pipefilter,执行split_filter_test.go 就会提示 undefined:xxxxxxx Golang实际都可以自己补全另一个文 ...
- 关于Windows下的访问控制模型
在探索Windows操作系统的过程中,发现很多有意思 的东西. Windows下的访问控制模型也是我在Github上浏览代码时,无意中发现的. 项目地址 https://github.com/Krut ...
- WebUploader 上传图片回显
/* fileMaxCount 最大文件数 buttonText 按钮文本 multiple 是否多选 */ (function ($) { $.fn.extend({ uploadImg: func ...
- Gitlab Runner实现CI/CD自动化部署asp.net core应用
环境说明 一台git服务器(192.168.169.7),安装gitlab,docker. 一台web服务器(192.168.169.6),安装git,gitlab runner,docker,dot ...
- 本地安装SQL Server 2017 Express和Microsoft SQL Server Management Studio 18.1
sqlserver下载链接:https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads 这个安装的是免费版的Express,当然也可 ...
- 移动端调试工具Vconsole
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 弹性布局flex 介绍
摘自:http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html 网页布局(layout)是CSS的一个重点应用. 布局的传统解决方案,基于盒状模 ...
- dnmp安装
centos7.2.box下载地址 链接: https://pan.baidu.com/s/1ny20PN2x7YuA6dwYA-P0yQ 提取码: wrdk 1 下载centos.box 新建dnm ...