requests库爬取豆瓣热门国产电视剧数据并保存到本地
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构:
这是接口地址,可以大概的分析一下各个参数的规则:
- type=tv,表示的是电视剧的分类
- tag=国产剧,表示是国产剧的分类
- sort参数,这里猜测是一个排序方式
- page_limit=20,这个一定就是每页所存取的数据数量了
- page_start=0,表示的是这页从哪条数据开始,比如第二页就为page_start=20,第三页为page_start=40,以此类推
- 最终我们要用到的主要是page_start和page_limit两个参数
下面这里是返回的json数据格式,可以看出我们要的是json中subjects列表中的每条数据,在之后的程序中会把每一个电视剧的信息保存到文件里的一行

有了这些,就直接上程序了,因为感觉程序还是比较好懂,主要还是遵从面向对象的程序设计:
import json
import requests class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地""" def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
} def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode() def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list def save_content_list(self, content_list): # 保存
with open('douban.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!') def run(self): # 实现主要逻辑
num = 0
while True:
# 1. start_url
url = self.url_temp.format(num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
if len(content_list) < 20:
break
# 5. 构造下一页url地址,进入循环
num += 20 # 每一页有二十条数据 if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
上面是利用循环遍历每一页,后来我又想到用递归也可以,虽然递归效率可能不高,这里还是展示一下,只需要改几个地方而已:
import json
import requests class DoubanSpider(object):
"""爬取豆瓣热门国产电视剧的数据并保存到本地"""
def __init__(self):
# url_temp中的start的值是动态的,所以这里用{}替换,方便后面使用format方法
self.url_temp = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start={}'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
self.num = 0 def pass_url(self, url): # 发送请求,获取响应
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode() def get_content_list(self, json_str): # 提取数据
dict_ret = json.loads(json_str)
content_list = dict_ret['subjects']
return content_list def save_content_list(self, content_list): # 保存
with open('douban2.txt', 'a', encoding='utf-8') as f:
for content in content_list:
f.write(json.dumps(content, ensure_ascii=False)) # 一部电视剧的信息一行
f.write('\n') # 写入换行符进行换行
print('保存成功!') def run(self): # 实现主要逻辑
# 1. start_url
url = self.url_temp.format(self.num)
# 2. 发送请求,获取响应
json_str = self.pass_url(url)
# 3. 提取数据
content_list = self.get_content_list(json_str)
# 4. 保存
self.save_content_list(content_list)
# 5. 构造下一页url地址,进入循环
if len(content_list) == 20:
self.num += 20 # 每一页有二十条数据
self.run() if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()
最终文件得到的结果:
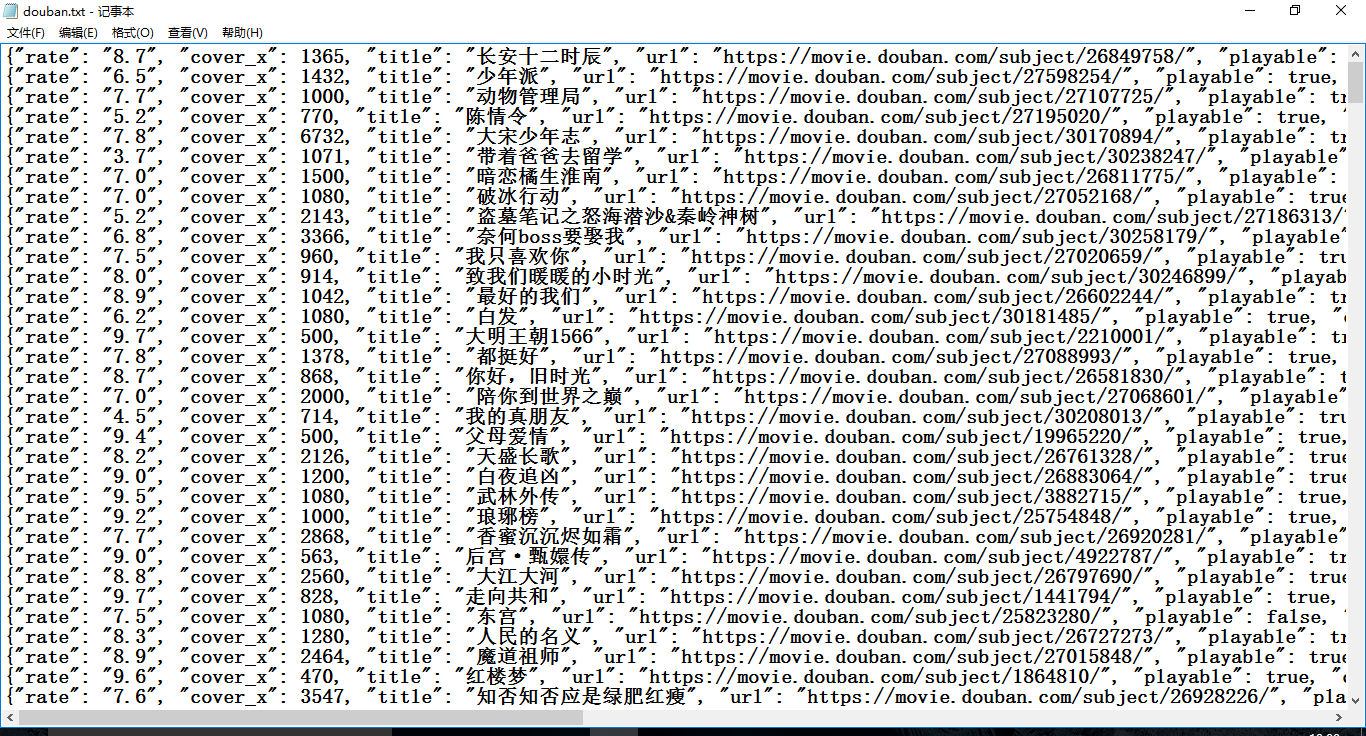
requests库爬取豆瓣热门国产电视剧数据并保存到本地的更多相关文章
- python--爬取豆瓣热门国产电视剧保存为文件
# -*- coding: utf-8 -*- __author__ = 'Frank Li' import requests import json class HotSpider(object): ...
- requests+正则爬取豆瓣图书
#requests+正则爬取豆瓣图书 import requests import re def get_html(url): headers = {'User-Agent':'Mozilla/5.0 ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- scrapy爬取校花网男神图片保存到本地
爬虫四部曲,本人按自己的步骤来写,可能有很多漏洞,望各位大神指点指点 1.创建项目 scrapy startproject xiaohuawang scrapy.cfg: 项目的配置文件xiaohua ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- requests库/爬取zhihu表情包
先学了requests库的一些基本操作,简单的爬了一下. 用到了requests.get()方法,就是以GET方式请求网页,得到一个Response对象.不加headers的话可能会400error所 ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
随机推荐
- 大体知道java语法2----------理解面向对象
我参加过大大小小n场面试,被好几位面试官问到过:能不能谈谈面向对象的几大特征?什么是面向对象?对于这两个问题,我始终觉得一定要理解,其实不只是这种概念题(姑且算它是概念题吧),包括各种语法都应该去理解 ...
- svn 同步备份的所有问题,亲测可用
svnsync 异地同步收获 (2010-07-06 10:06:19) 转载▼ 标签: 杂谈 分类: svn svnsync 异地同步收获: 来自:我用Subversion - http://www ...
- [论文理解] FoveaBox: Beyond Anchor-based Object Detector
FoveaBox: Beyond Anchor-based Object Detector Intro 本文是一篇one-stage anchor free的目标检测文章,大体检测思路为,网络分两路, ...
- 在Excel中,已知身份证号码,如何批量计算其实际年龄?
昨天,上司问我:..,你会在Excel中计算年龄吗?当时,一下促住了.说真的,还真不会.今天研究了一下,写下来,方便日后查看. 首先,得有一张已知姓名和相应身份证号的原表吧. 在这张表上再加上三列:出 ...
- H5 页面适配几种展现形式
1.contain 模式:以内容中心为基点按照视觉稿的宽高比缩放以适配窗口显示全页面内容,窗口与内容的宽度比或高度比之间较小者缩放填满窗口,当窗口宽高比和视觉稿不同时,另一方向的两侧出现留空部分. 2 ...
- openerp学习笔记 统计、分析、报表(过滤条件向导、分组报表、图形分析、比率计算、追加视图排序)
待解决:图形中当改变分组时,图例不正确 存储比率计算时,分组合计不正确 wizard:过滤条件向导,用于输入过滤条件 wizard/sale_chart.py # -*- cod ...
- flutter Could not find the built application bundle at build/ios/iphonesimulator/Runner.app
运行flutter run时报错 提示如下: Could not find the built application bundle at build/ios/iphonesimulator/Runn ...
- Mysql密码忘记,修改密码方法
1.set password for ‘root’@’localhost’ = password(‘czllss’); -- czllss为新密码
- 微服务简介和SOA比较
https://blog.csdn.net/chszs/article/details/78515231https://blog.csdn.net/wuxiaobingandbob/article/d ...
- This application's application-identifier entitlement does not match that of the installed application. These values must match for an upgrade to be allowed.
真机运行测试的时候Xcode会报这样的错误: 原因: 你的手机上已经安装了此项目. 解决办法: 把你以前安装的卸掉, 或者把这个项目的 bunldID 改了,再次运行即可.