AC自动机模版
我以前一直觉得AC自动机就是我打一个代码,然后可以帮我自动AC题目,现在才知道原来是处理字符串的一个有意思的东西,然后我们现在就来看一下这个东西
1464: [视频]【AC自动机】统计单词出现个数
时间限制: 1 Sec 内存限制: 128 MB
提交: 327 解决: 114
[提交] [状态] [讨论版] [命题人:admin]题目描述
【题意】
有n(n<=10000)个单词(长度不超过50,保证都为小写字母)和一句话(长度不超过1000000)
求出这句话包括几个单词
【输入格式】
输入t,表示有t组数据
每组数据第一行输入n,第i+1~i+n行输入n个单词,最后一行输入一句话
【输出格式】
输出这句话包括的单词个数(注意:一个单词重复出现,只算作出现了一个单词,如果有多个重复的单词,那么重复单词应该计算多次)
【样例输入】
1
5
she
he
say
shr
her
yasherhs
【样例输出】
3
首先把每一个单词建成一个字典树
如图:样例:
1
5
she
he
say
shr
her
yasherhs
黑色编号表示点的编号,黑色字母表示单词字符,下面是我们要处理的这句话这个时候引入一个新的知识:失败指针
这个失败指针是用来当我们匹配到一个点,发现不匹配时,我们所跳到的另一个点上,这个和KMP的p数组有一点点相似失败指针的定义:
如果i点的失败指针指向j的时候
s[i]表示从root到i点所构成的字符串
s[j]表示从root到j点所构成的字符串当j点为i点的失败指针时,满足s[j]为s[i]的后缀 (失败指针的定义一定要记住啊)
因为在字典树里面讲过,每个点都可以代表一个独立的单词(字符串)
比如说:如图
如果我们按照失败指针的操作的话,编号为2的h指向编号为4的h,因为从root到4号点所构成的字符串只有h一个,而从root到2号点所构成的字符串有sh两个,我们就可以看出h其实是sh的后缀,这个时候编号为2的h的失败指针就会指向编号为4的h,
注意:失败指针指向的那个点,因为我们一个点有可能会有很多个后缀,而有可能很多个后缀都在字典树里面出现过,这个指针指向的必定是所有当中满足条件的最长后缀
然后的话还是看代码的实现吧
因为我们提到了失败指针的概念,所以要在结构体当中定义一个fail,表示失败指针
又因为是多组数据,所以用一个clean函数来时时刻刻清空这棵字典树
还有一个bfs()函数,也就是宽搜,是用来构建失败指针的,
要定义一个优先队列,这个是用来存储我们失败指针的这个点的,优先队列只是一个队列,不会对我们插进去的队列进行操作,只是用来保存而已如果不存在,就继续找我的下一个指针,这个和KMP的思想是一样的,定义一个变量j来保存我们的失败指针
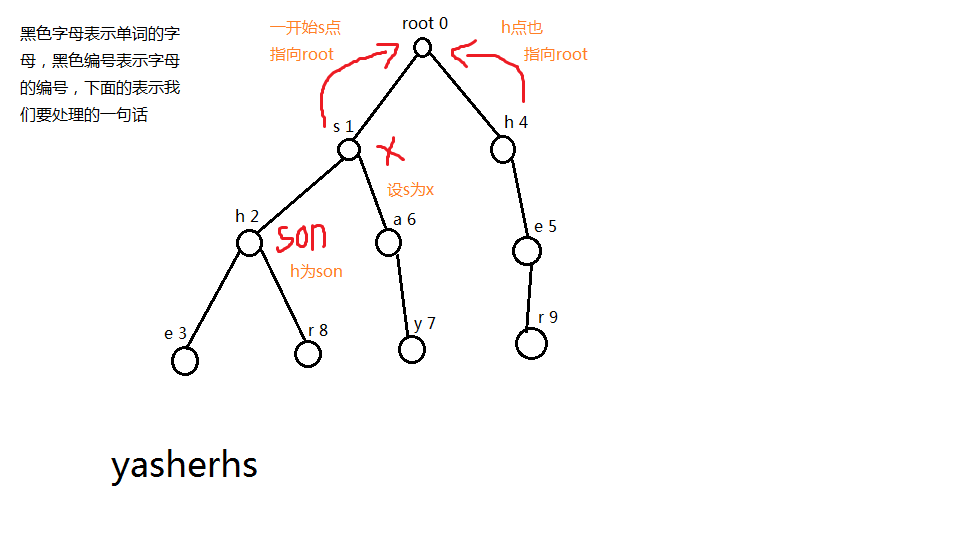
看图:
一开始s指向root,编号为4的h也指向root,然后我们看向编号为2的h,这个时候我们设s为x,编号为2的h为son,然后我们先去找x的失败指针,找到root这里,也就是0,如果=0,我们就会自动跳出搜索的while,tr[son].fail= max(tr[j].c[i],0);
看到这句话,为什么是max呢?因为有可能我匹配到root这个点的时候,root是不存在第i个孩子的,所以有可能这个tr[j].c[i]=-1,但是我们字典 树当中的所有点一但找不到适合的j点的时候,统统指向根,也就是0,假如他不是0,而且他又没有这个孩子的话,那么我们就继续找j的失败指针,其实我们在找j的失败指针的时候,j的失败指针也可以当作我x的失败指针,为什么呢?
因为我们在讲定义的时候,
如果i点的失败指针指向j的时候
s[i]表示从root到i点所构成的字符串
s[j]表示从root到j点所构成的字符串
当j点为i点的失败指针时,满足s[j]为s[i]的后缀就比如说代码里面的j点,他的s[j]是满足s[x]的后缀的,那么s[j]这个假设j点的失败指针为k,那么s[k]为s[j]的后缀,然后s[j]又为s[x]的后缀,那么s[k]一定是s[x]的后缀,所以我们就可以直接用这一点来不断的更新的son的失败指针
然后我们每一次询问完之后,我们就把我们的孩子推进我们的优先队列里面,又因为我们的x已经操作完毕了,我们就从优先队列里面踢出来
但是我们在建树的时候,我们在每个单词的末尾那里,定义一个s,把s++表示这个点是一个单词的结尾
然后我们用solve来求出一个单词的解
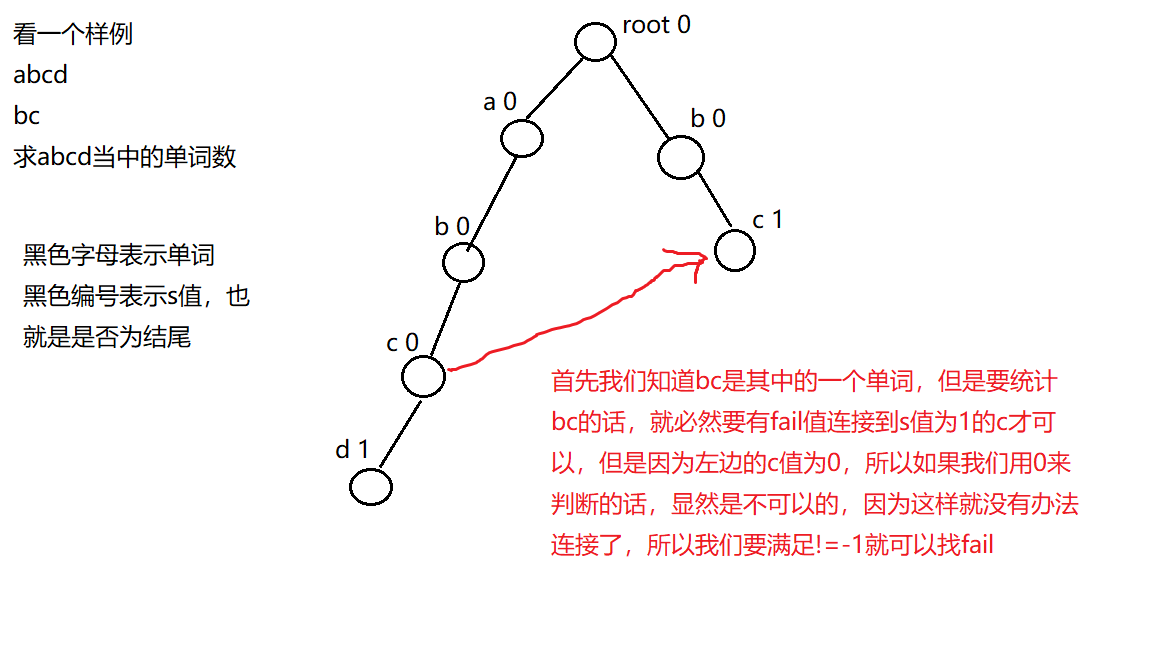
一开始x为根,假如当前x不为根,并且当前的x是没有y这个孩子的话,我们就找到x的失败指针,找完之后x就等于他的儿子,如果等于x=-1,就说明这个孩子不存在,那么就从根开始重新找,遍历到下一个字符,定义一个j是为了防止改变x的值,如果当前的这个点是一个单词的结尾或者多个单词的结尾,ans就记录下这个答案, 然后清零,因为已经使用过了,然后就找他的失败指针,重点在这里,我们的重点不是为了记录答案,而是为了找fail因为如果这个单词能够成立的话,那么我们的失败指针所指向的那个点所构成的字符串也是可以到达的,所以我们要找他的失败指针,也要加上他的单词数但是我们判断结尾的时候一定是不等于-1,而不是不等于0
如图

我有点不厚道的在上面就把代码实现的过程讲了一下,但是现在还是来看一下代码实现吧
(注释版,如果真的非常非常理解就不看注释版,不然的话就看一眼吧)
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<cmath>
#include<iostream>
using namespace std;
char a[];
int tot,ans;
int list[];
struct node/*trie是字典树*/
{
int s,fail,cnt[];/*s表示单词的结尾,fail表示失败指针,cnt表示第几个孩子*/
/*
失败指针的定义
如果i点的失败指针指向j的时候
s[i]表示从root到i点所构成的字符串
s[j]表示从root到j点所构成的字符串
当j点为i点的失败指针时,满足s[j]为s[i]的后缀
*/
node()
{
s=fail=;
memset(cnt,-,sizeof(cnt));/*初始化*/
}
}tr[];
void clean(int x)/*多组数据,每一次都要清空树*/
{
tr[x].s=tr[x].fail=;
memset(tr[x].cnt,-,sizeof(tr[x].cnt));
}
void build_tree(int root)/*建树,相当于字典树的建树,就是有一个小小的不一样的地方*/
{
int x=root,len=strlen(a+);
for(int i=;i<=len;i++)
{
int y=a[i]-'a'+;/*1~26*/
if(tr[x].cnt[y]==-)
{
tr[x].cnt[y]=++tot;/*新增加一个点*/
clean(tot);/*将这个点的子树全部清空*/
/*这样子就可以做到初始化的操作了*/
}
x=tr[x].cnt[y];
}
tr[x].s++;/*s++表示这个点是一个单词的结尾*/
}
void bfs()/*宽搜,优先队列,用来存构造失败指针的点*/
{
list[]=; int head=,tail=;
while(head<=tail)
{
int x=list[head];
for(int i=;i<=;i++)/*从26个孩子开始*/
{
int son=tr[x].cnt[i];/*son表示x的第i个孩子节点*/
if(son==-) continue;/*等于-1,代表我这个孩子不存在,找下一个孩子*/
if(x==) tr[son].fail=;
/*如果x=0,就说明x是root,root所有孩子的失败指针都为0,因为是第一个字母,
所以不会有除了他本身和他匹配的点,所以他的失败指针都是指向root*/
else
{
/*构造失败指针*/
int j=tr[x].fail;/*j等于x的失败指针*/
while(j!= && tr[j].cnt[i]==-) j=tr[j].fail;
/*询问j的第i个孩子是否存在,假如不存在就继续找我们失败指针,这个和KMP的思想是差不多的
j=0也就是指向root就会自动跳出来*/ /*假如他不是0,而且他又没有这个孩子的话,那么我们就继续找j的失败指针,其实我们在找j的失败指针的时候,
j的失败指针也可以当作我x的失败指针,为什么呢? 因为我们在讲定义的时候,
如果i点的失败指针指向j的时候
s[i]表示从root到i点所构成的字符串
s[j]表示从root到j点所构成的字符串
当j点为i点的失败指针时,满足s[j]为s[i]的后缀 就比如说代码里面的j点,他的s[j]是满足s[x]的后缀的,那么s[j]这个假设j点的失败指针为k,那么s[k]为s[j]的后缀,
然后s[j]又为s[x]的后缀,那么s[k]一定是s[x]的后缀,所以我们就可以直接用这一点来不断的更新的son的失败指针*/
tr[son].fail=max(tr[j].cnt[i],);
/*为什么是max呢?因为有可能我匹配到root这个点的时候,root是不存在第i个孩子的,所以有可能这个tr[j].c[i]=-1,
但是我们字典树当中的所有点一但找不到适合的j点的时候,统统指向根,也就是0*/
}
list[++tail]=son;/*询问完毕就将孩子推进优先队列*/
}
head++;/*x已经操作完毕,就踢出优先队列*/
}
}
void solve()
{
int x=; int len=strlen(a+);/*一开始x为根*/
for(int i=;i<=len;i++)
{
int y=a[i]-'a'+;
while(x!= && tr[x].cnt[y]==-) x=tr[x].fail;
/*假如当前x不为根,并且当前的x是没有y这个孩子的话,我们就找到x的失败指针*/
x=tr[x].cnt[y];/*找完之后x就等于他的儿子*/
if(x==-) {x=; continue;}/*假如孩子不存在,就从根开始重新找*/
int j=x;/*为了不改变x的值*/
while(tr[j].s!=-)/*如果这个是单词的结尾或者多个单词的结尾,就可以记录答案
这里为什么是-1而不是0呢?如图*/
{
ans+=tr[j].s;/*记录答案*/
tr[j].s=-;/*因为我们已经用过了*/
j=tr[j].fail;/*因为如果这个单词能够成立的话,那么我们的失败指针所指向的那个点所构成的字符串也是可以到达的,
所以我们要找他的失败指针,也要加上他的单词数*/
}
}
}
int main()
{
int t; scanf("%d",&t);
while(t--)
{
int n; scanf("%d",&n);
ans=; tot=; clean();
for(int i=;i<=n;i++)
{
scanf("%s",a+);
build_tree();/*建树*/
}
bfs();/*构造失败指针*/
scanf("%s",a+);
solve();/*寻找答案*/
printf("%d\n",ans);
}
return ;
}
Tristan Code 注释版
(非注释版,我建议完全打懂了之后用这个来测试一下自己是不是真的懂)
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<cmath>
#include<iostream>
using namespace std;
char a[];
int tot,ans;
int list[];
struct node
{
int s,fail,cnt[];
node()
{
s=fail=;
memset(cnt,-,sizeof(cnt));
}
}tr[];
void clean(int x)
{
tr[x].s=tr[x].fail=;
memset(tr[x].cnt,-,sizeof(tr[x].cnt));
}
void build_tree(int root)
{
int x=root,len=strlen(a+);
for(int i=;i<=len;i++)
{
int y=a[i]-'a'+;
if(tr[x].cnt[y]==-)
{
tr[x].cnt[y]=++tot;
clean(tot);
}
x=tr[x].cnt[y];
}
tr[x].s++;
}
void bfs()
{
list[]=; int head=,tail=;
while(head<=tail)
{
int x=list[head];
for(int i=;i<=;i++)
{
int son=tr[x].cnt[i];
if(son==-) continue;
if(x==) tr[son].fail=;
else
{
int j=tr[x].fail;
while(j!= && tr[j].cnt[i]==-) j=tr[j].fail;
tr[son].fail=max(tr[j].cnt[i],);
}
list[++tail]=son;
}
head++;
}
}
void solve()
{
int x=; int len=strlen(a+);
for(int i=;i<=len;i++)
{
int y=a[i]-'a'+;
while(x!= && tr[x].cnt[y]==-) x=tr[x].fail;
x=tr[x].cnt[y];
if(x==-) {x=; continue;}
int j=x;
while(tr[j].s!=-)
{
ans+=tr[j].s;
tr[j].s=-;
j=tr[j].fail;
}
}
}
int main()
{
int t; scanf("%d",&t);
while(t--)
{
int n; scanf("%d",&n);
ans=; tot=; clean();
for(int i=;i<=n;i++)
{
scanf("%s",a+);
build_tree();
}
bfs();
scanf("%s",a+);
solve();
printf("%d\n",ans);
}
return ;
}
Tristan Code 非注释版
AC自动机模版的更多相关文章
- HDU 2222 Keywords Search(AC自动机模版题)
Keywords Search Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- HDU 3695 Computer Virus on Planet Pandora(AC自动机模版题)
Computer Virus on Planet Pandora Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 256000/1280 ...
- HDU 2222 AC自动机模版题
所学的AC自动机都源于斌哥和昀神的想法. 题意:求目标串中出现了几个模式串. 使用一个int型的end数组记录,查询一次. #include <cstdio> #include <c ...
- hdu 2896 AC自动机模版题
题意:输出出现模式串的id,还是用end记录id就可以了. 本题有个关键点:“以上字符串中字符都是ASCII码可见字符(不包括回车).” -----也就说AC自动机的Trie树需要128个单词分支. ...
- hdu 2222(AC自动机模版题)
Keywords Search Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- hdu 3065 AC自动机模版题
题意:输出每个模式串出现的次数,查询的时候呢使用一个数组进行记录就好. 同上题一样的关键点,其他没什么难度了. #include <cstdio> #include <cstring ...
- HDU 2222 AC自动机(模版题)
Keywords Search Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- poj 1625 (AC自动机好模版,大数好模版)
题目 给n个字母,构成长度为m的串,总共有n^m种.给p个字符串,问n^m种字符串中不包含(不是子串)这p个字符串的个数. 将p个不能包含的字符串建立AC自动机,每个结点用val值来标记以当前节点为后 ...
- 【模版】AC自动机(简单版)
题目背景 这是一道简单的AC自动机模版题. 用于检测正确性以及算法常数. 为了防止卡OJ,在保证正确的基础上只有两组数据,请不要恶意提交. 题目描述 给定n个模式串和1个文本串,求有多少个模式串在文本 ...
随机推荐
- R-seq()
seq(0, 1, length.out = 11) > seq(0, 1, length.out = 11) [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0 ...
- Git与Repo 的使用
一.Linux常用命令 pwd 用于显示工作目录,执行pwd指令可立刻得知您目前所在的工作目录的绝对路径名称. chmod 用来变更文件或目录的权限. > ...
- ftp协议在linux上的配置
第一步:安装 yum install -y vsftpd 第二步:启动ftp服务:vsftpd [root@localhost ~]# systemctl start vsftpd 第三步:查看启动状 ...
- 使用SpringBoot校验客户端传来的数据
前端的数据校验都是辣鸡!后端天下第一! 很多时候我们后端需要前端传数据过来, 比如注册, 修改用户名, 修改密码等等.很可能有些用户就喜欢搞事, 喜欢发一大堆乱七八糟的数据到后端来, 甚至有些前端老哥 ...
- nvl(sum(字段),0) 的时候,能展示数据0,但是group by 下某个伪列的时候,查不到数据(转载)
今天碰到一个比较有疑惑的问题,就是在统计和的时候,我们往往有时候查不到数据,都会再加个 nvl(sum(字段),0) 来显示这个字段,但是如果我们再加个group by ,就算有加入这个 nvl(nu ...
- 依赖注入框架之androidannotations
主页: http://androidannotations.org/ 用途: 1. 使用依赖注入Views,extras,System Service,resources 2. 简化线程模型 3. 事 ...
- Maven-SSM框架整合
1.创建Maven项目 配置pom.xml依赖 <!-- 允许创建jsp页面 --> <dependency> <groupId>javax.servlet< ...
- (转)java8实现对象列表去重
java8实现列表去重,java8的stream和lambda的使用实例 通过普通的方式也可以达到去重的效果,但是借助java8新特性可以很方便的实现列表去重,测试demo如下 实体类: public ...
- Markdown 介绍
Markdown 是目前互联网上最流行的写作语言,它使用一些简单的符号(* / ` > [] () #)来标记文本格式,其简洁的语法.优美的格式以及强大的软件支持深受广大网友的喜爱.维基百科上对 ...
- 使用第三方UITableView+FDTemplateLayoutCell计算cell行高注意点
现在很方便的计算单元格的行高大部分都是使用的第三方框架UITableView+FDTemplateLayoutCell,不知道你在使用这个框架的时候有没有遇到和我一样的问题,比如: 在这样计算cell ...