python编码和解码
一、什么是编码
编码是指信息从一种形式或格式转换为另一种形式或格式的过程。
在计算机中,编码,简而言之,就是将人能够读懂的信息(通常称为明文)转换为计算机能够读懂的信息。众所周知,计算机能够读懂的是高低电平,也就是二进制位(0,1组合)。
而解码,就是指将计算机的能够读懂的信息转换为人能够读懂的信息。
二、 编码的发展渊源
由于计算机最早在美国发明和使用,所以一开始人们使用的是ASCII编码。ASCII编码占用1个字节,8个二进制位,最多能够表示2**8=256个字符。
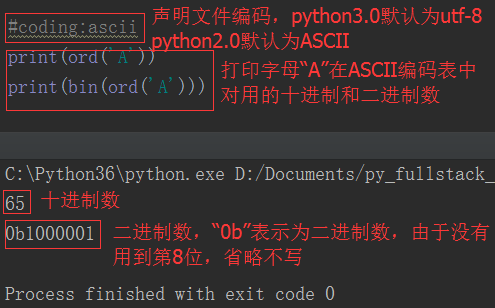
随着计算机的发展,ASCII码已经不能满足世界人民的需求。因为世界各国语言繁多,字符远远超过256个。所以各个国家都在ASCII基础上搞自己国家的编码。
例如中国,为了处理汉字,设计了GB2312编码,一共收录了7445个字符,包括6763个汉字和682个其它符号。1995年的汉字扩展规范GBK1.0收录了21886个符号。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。

但是,在编码上,各国”各自为政“,很难互相交流。于是出现了Unicode编码。Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
Unicode规定字符最少使用2个字节表示,所以最少能够表示2**16=65536个字符。这样看来,问题似乎解决了,各国人民都能够将自己的文字和符号加入Unicode,从此就可以轻松交流了。
然而,在当时,计算机的内存容量可是寸土寸金的情况下,美国等北美洲国家是不接受这个编码的。因为这凭空增加了他们文件的体积,进而影响了内存使用率,影响工作效率。这就尴尬了。
显然国际标准在美国这边不受待见,所以应运而生产生了utf-8编码。
UTF-8,是对Unicode编码的压缩和优化,它不再要求最少使用2个字节,而是将所有的字符和符号进行分类:ASCII码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
这样,大家各取所需,皆大欢喜。
三、utf-8是如何节省存储空间和流量的
当计算机在工作时,内存中的数据一直是以Unicode的编码方式表示的,当数据要保存到磁盘或者网络传输时,才会使用utf-8编码进行操作。
在计算机中,”I'm 杰克"的unicode字符集是这样的编码表:
|
1
2
3
4
5
6
|
I 0x49 ' 0x27m 0x6d 0x20杰 0x6770克 0x514b |
每个字符对应一个十六进制数(方便人们阅读,0x代表十六进制数),但是计算机只能读懂二进制数,所以,实际在计算机内表示如下:
|
1
2
3
4
5
6
|
I 0b1001001' 0b100111m 0b1101101 0b100000杰 0b110011101110000克 0b101000101001011 |
由于Unicode规定,每个字符最少占用2个字节,所以,以上字符串在内存中的实际占位如下:
|
1
2
3
4
5
6
|
I 00000000 01001001' 00000000 00100111m 00000000 01101101 00000000 00100000杰 01100111 01110000克 01010001 01001011 |
这串字符总共占用了12个字节,但是对比中英文的二进制码,可以发现,英文的前9位都是0,非常的浪费空间和流量。
看看utf-8是怎么解决的:
|
1
2
3
4
5
6
|
I 01001001' 00100111m 01101101 00100000杰 11100110 10011101 10110000克 11100101 10000101 10001011 |
utf-8用了10个字节,对比Unicode,少了2个字节。但是,我们的程序中很少用到中文,如果我们程序中90%的内容都是英文,那么可以节省45%的存储空间或者流量。
所以,在存储和传输时,大部分时候遵循utf-8编码

四、Python2.x与Python3.x中的编解码
1. 在Python2.x中,有两种字符串类型:str和unicode类型。str存bytes数据,unicode类型存unicode数据
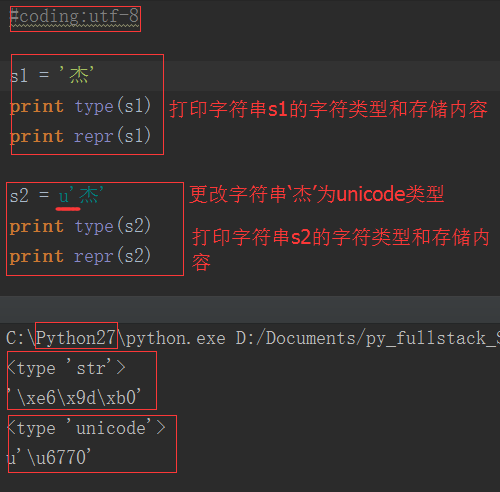
由上图可以看出,str类型存储的是十六进制字节数据;unicode类型存储的是unicode数据。utf-8编码的中文占3个字节,unicode编码的中文占2个字节。
字节数据常用来存储和传输,unicode数据用来显示明文,那如何转换两种数据类型呢:
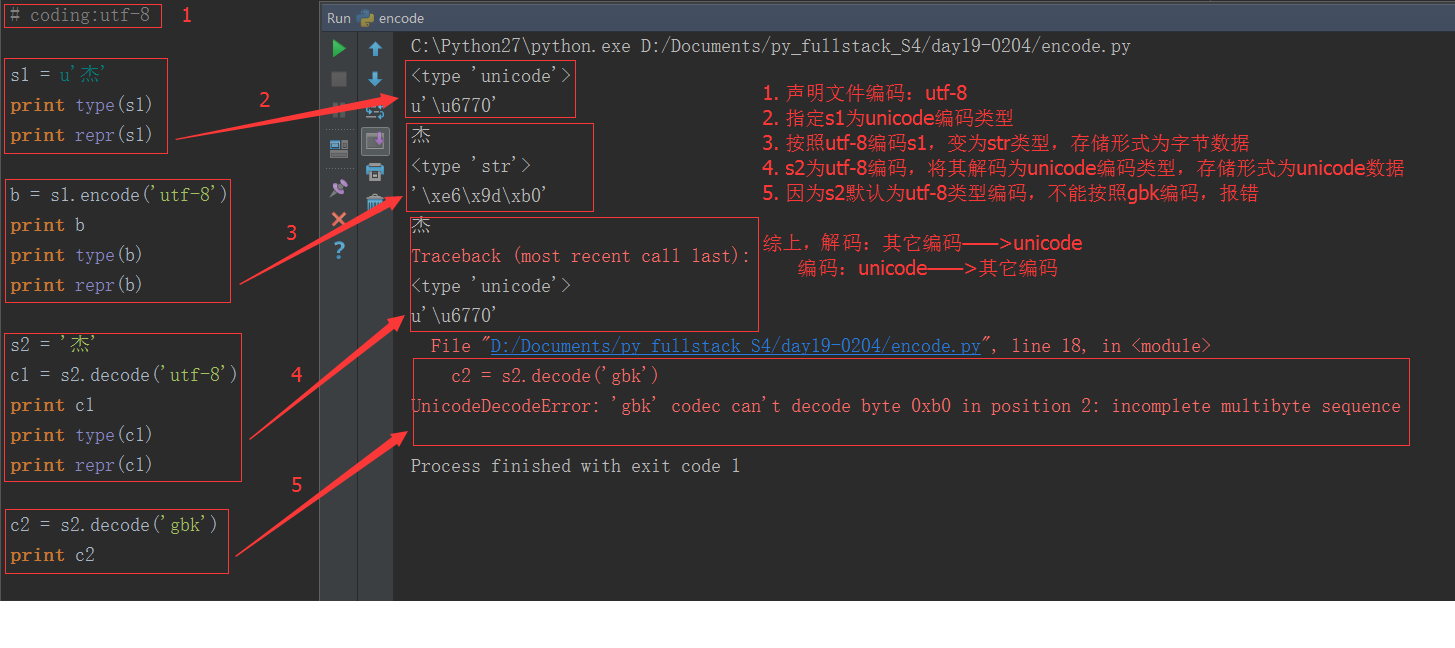
无论是utf-8还是gbk都只是一种编码规则,一种把unicode数据编码成字节数据的规则,所以utf-8编码的字节一定要用utf-8的规则解码,否则就会出现乱码或者报错的情况。
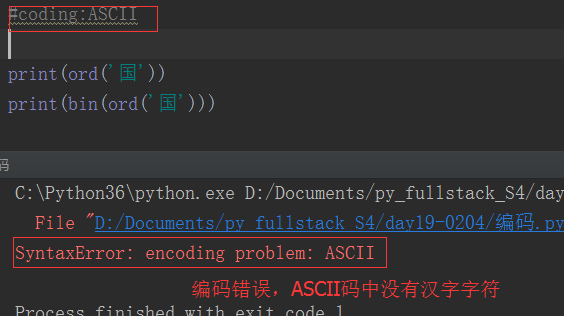
python2.x编码的特色:
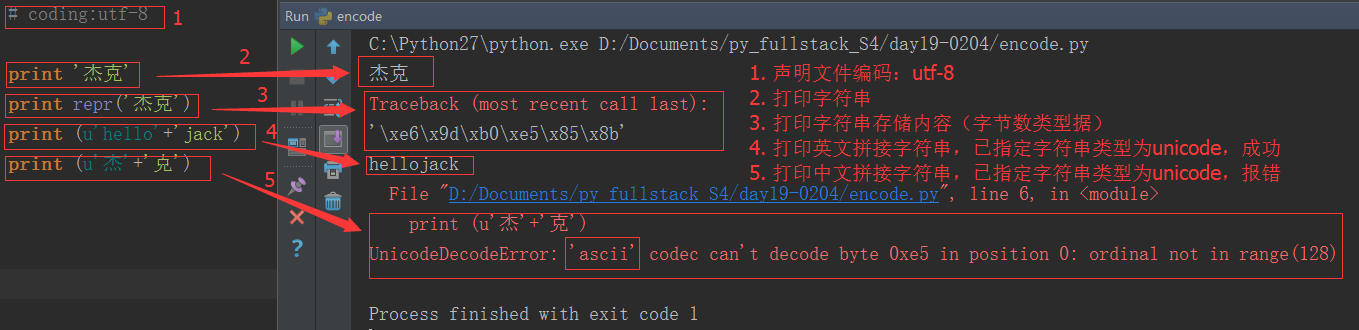
为什么英文拼接成功了,而中文拼接就报错了?
这是因为在python2.x中,python解释器悄悄掩盖掉了 byte 到 unicode 的转换,只要数据全部是 ASCII 的话,所有的转换都是正确的,一旦一个非 ASCII 字符偷偷进入你的程序,那么默认的解码将会失效,从而造成 UnicodeDecodeError 的错误。python2.x编码让程序在处理 ASCII 的时候更加简单。你付出的代价就是在处理非 ASCII 的时候将会失败。
2. 在Python3.x中,也只有两种字符串类型:str和bytes类型。
str类型存unicode数据,bytse类型存bytes数据,与python2.x比只是换了一下名字而已。
还记得之前博文中提到的这句话吗?ALL IS UNICODE NOW
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.

Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。
注意:无论python2,还是python3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
五、文件从磁盘到内存的编码
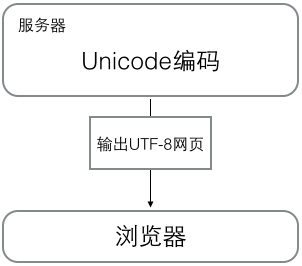
当我们在编辑文本的时候,字符在内存对应的是unicode编码的,这是因为unicode覆盖范围最广,几乎所有字符都可以显示。但是,当我们将文本等保存在磁盘时,数据是怎么变化的?
答案是通过某种编码方式编码的bytes字节串。比如utf-8,一种可变长编码,很好的节省了空间;当然还有历史产物的gbk编码等等。于是,在我们的文本编辑器软件都有默认的保存文件的编码方式,比如utf-8,比如gbk。当我们点击保存的时候,这些编辑软件已经"默默地"帮我们做了编码工作。
那当我们再打开这个文件时,软件又默默地给我们做了解码的工作,将数据再解码成unicode,然后就可以呈现明文给用户了!所以,unicode是离用户更近的数据,bytes是离计算机更近的数据。
其实,python解释器也类似于一个文本编辑器,它也有自己默认的编码方式。python2.x默认ASCII码,python3.x默认的utf-8,可以通过如下方式查询:
|
1
2
|
import sysprint(sys.getdefaultencoding()) |
如果我们不想使用默认的解释器编码,就得需要用户在文件开头声明了。还记得我们经常在python2.x中的声明吗?
|
1
|
#coding:utf-8 |
如果python2解释器去执行一个utf-8编码的文件,就会以默认的ASCII去解码utf-8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf-8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf-8来解码。而python3的解释器因为默认utf-8编码,所以就方便很多了。
六,总结
1.UTF 是为unicode编码 设计 的一种在存储和传输时节省空间的编码方案。
# python3 文件默认编码是utf-8 , 字符串编码是 unicode
以utf-8 或者 gbk等编码的代码,加载到内存,会自动转为unicode正常显示。 # python2 文件默认编码是ascii , 字符串编码也是 ascii , 如果文件头声明了是gbk,那字符串编码就是gbk。
以utf-8 或者 gbk等编码的代码,加载到内存,并不会转为unicode,编码仍然是utf-8或者gbk等编码。
2、字符在硬盘上的存储
首先要明确的一点就是,无论以什么编码在内存里显示字符,存到硬盘上都是2进制(0b是说明这段数字是二进制,0x表示是16进制。0x几乎所有的编译器都支持,而支持0b的并不多)。理解这一点很重要。
还要注意的一点是:存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读(开头声明或转换),要不然就乱了。
3、编码与转换
虽然有了unicode and utf-8 ,但是由于历史问题,各个国家依然在大量使用自己的编码,
比如中国的windows,默认编码依然是gbk,而不是utf-8。
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
所以该怎么办呢?
还记得我们讲unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,这时就派上用场了。
无论你以什么编码存储的数据,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑上,加载到内存里,变成了unicode,
中文就可以正常展示啦。
# 1、解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
# 2、把代码字符串按照语法规则进行解释
# 3、所有的变量字符都会以unicode编码声明
在py3上 把你的代码以utf-8编写, 保存,然后在windows上执行。
发现可以正常执行!
其实utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode ,
但是这只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如 万恶的python2 就不是,
它是ASCII(龟叔当初设计Python时的一点缺陷),想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器
仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,
加载到内存里,你的变量字符串就也是utf-8, 这意味着什么?意味着,你以utf-8编码的文件,在windows是乱码。
其实乱是正常的,不乱才不正常,因为只有2种情况 ,你的windows上显示才不会乱。
Python2并不会自动的把文件编码转为unicode存在内存里。
1、字符串以GBK格式显示
2、字符串是unicode编码
所以我们只有手动转,Python3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)。
方法如下:
UTF-8/GBK --> decode 解码 --> Unicode Unicode --> encode 编码 --> GBK / UTF-8
1
python编码和解码的更多相关文章
- Python编码与解码
# -*- coding: utf-8 -*- # 直接保存为Python脚本,对照执行结果会好看点. # 实验的内容都是在Python 2.7.x下进行的. # Python3默认采用unicode ...
- Python—编码与解码(encode()和decode())
编码与解码 decode英文意思是解码,encode英文原意是编码. Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化.编码是 unicode -> str ...
- python 编码与解码 decode解码 encode 编码
>>> '无' #gbk字符'\xce\xde'>>> str1 = '\xce\xde'>>> str1.decode('gbk') # ...
- python 编码和解码
- python base64编码和解码图片
简介 在实际项目中,可能需要对图片进行大小的压缩,较为常见的方法则是将图片转换为base64的编码,本文就python编码和解码图片做出一定的介绍. 代码 import base64 import o ...
- python3中编码与解码的问题
python3中编码与解码的问题 ASCII .Unicode.UTF-8 ASCII 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此 ...
- Python中进行Base64编码和解码
Base64编码 广泛应用于MIME协议,作为电子邮件的传输编码,生成的编码可逆,后一两位可能有“=”,生成的编码都是ascii字符.优点:速度快,ascii字符,肉眼不可理解缺点:编码比较长,非常容 ...
- python中的编码与解码
编码与解码 首先,明确一点,计算机中存储的信息都是二进制的 编码/解码本质上是一种映射(对应关系),比如‘a’用ascii编码则是65,计算机中存储的就是00110101,但是显示的时候不能显 ...
- Python的编码和解码
Python的编码和解码 在不同的国家,存在不同的文字,由于现在的软件都要做到国际化通用,所以必须要有一种语言或编码方式,来实现各种编码的解码,然后重新编码. 在西方国家,没有汉字,只有英文,所以最开 ...
随机推荐
- Android Butterknife使用方法总结 IOC框架
前言: ButterKnife是一个专注于Android系统的View注入框架,以前总是要写很多findViewById来找到View对象,有了ButterKnife可以很轻松的省去这些步骤.是大神J ...
- Swift编码总结1
1. fileprivate (set) var hasSetDiscount = false中fileprivate (set)表示什么意思: //设置setter私有,但是getter为publi ...
- didMoveToSuperview方法认识和使用
由来: 今天给项目添加新功能——点击弹出阳历,阴历日期选择. 弹出日期选择是弹出的控制器,里面的日期选择控件是封装的View,View使用Xib画的, 遇到的问题是:控制器传数据给View,在awak ...
- 无法复制CSD内容,复制后出现一行长字符串解决
先打开一个linux文件,然后把复制的内容放到linux文件中即可解决
- log4net使用简明教程,快看看哟
在项目当中经常会遇到各种各样的问题,如何可以尽快找到问题,那么就只能靠日志了,所以一个系统的日志是否完备合理就尤为重要. 在日志管理插件中log4net相当流行,下面就简单说明一下使用方法. log4 ...
- anywhere随启随用的静态文件服务器
手机移动端调试,也可以使用anywhere anywhere -p 8080 指定端口 anywhere -s 保持浏览器关闭 anywhere -h localhost -p 8080 通过主机名 ...
- 【OpenGL开发】关于GLEW扩展库
GLEW是一个跨平台的C++扩展库,基于OpenGL图形接口.使用OpenGL的朋友都知道,window目前只支持OpenGL1.1的涵数,但 OpenGL现在都发展到2.0以上了,要使用这些Open ...
- 【GStreamer开发】GStreamer基础教程08——pipeline的快捷访问
目标 GStreamer建立的pipeline不需要完全关闭.有多种方法可以让数据在任何时候送到pipeline中或者从pipeline中取出.本教程会展示: 如何把外部数据送到pipeline中 如 ...
- jvm误区--动态对象年龄判定
原文链接:https://blog.csdn.net/u014493323/article/details/82921740 虚拟机并不是永远地要求对象的年龄必须达到了MaxTenuringThres ...
- [转帖]MySQL latch小结
MySQL latch小结 https://www.cnblogs.com/liang545621/p/9439816.html 学习一下 一个是数据库内容 一个是内存内容 与oracle的读写锁 应 ...