spark教程(一)-集群搭建
spark 简介
建议先阅读我的博客 大数据基础架构
spark 一个通用的计算引擎,专门为大规模数据处理而设计,与 mapreduce 类似,不同的是,mapreduce 把中间结果 写入 hdfs,而 spark 直接写入 内存,这使得它能够实现实时计算。
spark 由 scala 语言开发,他能够和 scala 完美结合,同时实现了 java、python、R 等接口。
搭建模式
spark 有 3 种搭建模式
local 模式:即单机模式,这种安装加压即可,具体安装方法穿插在 Standalone 模式
Standalone 模式:即搭建 spark 集群,但不与其他框架集成,如 yarn,此时 spark 运行在集群中
基于 yarn 的 spark 集群部署:yarn 集群 + spark 集群,此时 spark 运行在 yarn 中
local 和 standalone 模式必须启动 spark,yarn 模式无需启动 spark
具体怎么理解这 3 种模式,后面有空我会详细讲
Standalone 模式
第一步:安装环境
1. 安装java:很简单,请自行百度
2. 安装 hadoop 集群:具体参考我的博客 hadoop 集群搭建
// 如果 spark 读取 hdfs 就需要 hadoop,如果只玩本地,无需这步
3. 安装 scala:spark tar 包带有 scala 依赖,所以无需专门安装
4. python2.7 以上版本:如果要使用 pyspark 才需要安装,也就是说玩 python 才需要这步
第二步:下载并安装
1. 官网下载 spark
下载地址 spark
注意选择 hadoop 对应的版本

2. 解压 tar 包
上传至集群的每个节点,解压,设置环境变量
export SPARK_HOME=/usr/lib/spark
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH
至此已经完成单机模式的 spark 安装
3. 配置 spark
进入 spark 解压目录,需要配置 conf/slaves,conf/spark-env.sh 两个文件
注意这两个文件是不存在的,需要 cp 复制一下
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
slaves
末尾去掉 localhost,加上以下内容
hadoop10
hadoop11
hadoop12
hadoop13
spark-env.sh
加上以下内容
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk.x86_64
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1G
设置 spark 的主节点 和 端口;
spark_worker_memory 表示计算时使用的内存,越大越好,spark 是基于内存的计算
4. 向其他节点远程下发配置
scp -r conf/ root@hadoop11:/usr/lib/spark
scp -r conf/ root@hadoop12:/usr/lib/spark
scp -r conf/ root@hadoop13:/usr/lib/spark
5. 启动 spark
cd /usr/lib/spark/sbin、
./start-all.sh
停止就是对应的 stop
6. 验证是否启动成功
6.1 jsp 查看进程
主节点显示 master 和 worker 两个进程
从节点显示 worker 进程
Standalone 模式显示的是 master worker,yarn 显示的不是
6.2 浏览器访问 http://192.168.10.10:8080/
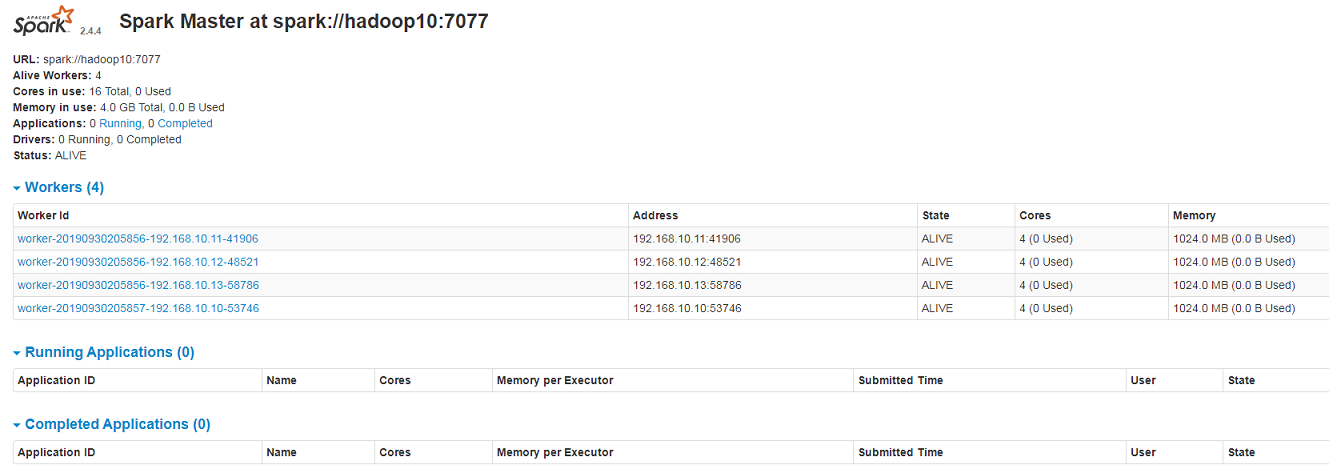
第三步:操作 spark 集群
这里只做简单介绍,验证 spark 是否启动,然后看看长啥样即可
客户端操作 spark 集群的命令都在 spark 的 bin 目录下

1. spark-shell 模式 【 scala 模式】
输入命令
spark-shell # 也可以设置参数
spark-shell --master spark://hadoop10:7077 --executor-memory 600m
[root@hadoop10 spark]# bin/spark-shell
19/10/09 17:47:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = local[*], app id = local-1570668484546).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/ Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_222)
注意绿色的两句,意思是 shell 中内置了 可用的 spark context 和 spark session,名字分别为 sc 和 spark
按 :quit 退出
2. pyspark 模式 【python 模式】
输入命令 pyspark 即可
[root@hadoop10 spark]# bin/pyspark
Python 2.7.12 (default, Oct 2 2019, 19:43:15)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
19/10/02 22:08:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.4
/_/ Using Python version 2.7.12 (default, Oct 2 2019 19:43:15)
SparkSession available as 'spark'.
>>>
注意这里只有 spark session,但是 spark context 也可以直接用
如果出现 NameError: name 'memoryview' is not defined,说明 python 版本不对,2.7 及以上
如果出现未导入包什么的,请自行解决,一般是 python 没装好
基于 yarn 的 spark 部署
第一步:安装环境
1. 安装java:很简单,请自行百度
2. 安装 hadoop 集群:具体参考我的博客 hadoop 集群搭建;必须有,因为要用 yarn
3. 安装 scala:spark tar 包带有 scala 依赖,所以无需专门安装
4. python2.7 以上版本:如果要使用 pyspark 才需要安装,也就是说玩 python 才需要这步
第二步:安装 spark
spark on yarn 模式只需在 hadoop 集群的任一节点安装 spark 即可,不需要 spark 集群;
因为 spark 应用提交到 yarn 后,yarn 负责集群资源调度。
spark 安装参照 Standalone 模式,大致如下:
1. 配置环境变量
2. spark-env.sh 添加如下内容
YARN_CONF_DIR=/usr/lib/hadoop-2.6.5/etc/hadoop
这个地址是 hadoop yarn 的配置文件的地址
第三步:修改 hadoop yarn 的配置
修改 yarn-site.xml,添加如下内容
<!-- spark 部署到 yarn 上需要这两个配置 -->
<!-- 是否启动一个线程检查每个任务正在使用的物理内存,如果超出分配值,则直接杀掉该任务,默认为 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property> <!-- 是否启动一个线程检查每个任务正在试用的虚拟内存,如果超出分配值,则直接杀掉该任务,默认为 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- spark 部署到 yarn 上需要这两个配置 -->
分发到各节点
不配置这步可能报错,特别是分配内存较小时,如虚拟机情况下。
至此配置完毕,注意,无需启动 spark
第四步:操作 yarn 模式
spark-shell --master yarn-client # 这种方式在 spark2.x 中被废弃,替代命令为下面这句
spark-shell --master yarn --deploy-mode client
yarn 模式 不在 spark UI 上监控,而是在 hadoop UI 上,地址为 http://192.168.10.10:8088
参考资料:
https://www.cnblogs.com/swordfall/p/7903678.html 安装
https://www.jianshu.com/p/5626612bf10c 安装
https://blog.csdn.net/penyok/article/details/81483527 安装
https://blog.csdn.net/chengyuqiang/article/details/77864246 spark on yarn
spark教程(一)-集群搭建的更多相关文章
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- [spark]-Spark2.x集群搭建与参数详解
在前面的Spark发展历程和基本概念中介绍了Spark的一些基本概念,熟悉了这些基本概念对于集群的搭建是很有必要的.我们可以了解到每个参数配置的作用是什么.这里将详细介绍Spark集群搭建以及xml参 ...
- spark完全分布式集群搭建
最近学习Spark,因此想把相关内容记录下来,方便他人参考,也方便自己回忆吧 spark开发环境的介绍资料很多,大同小异,很多不能一次配置成功,我以自己的实际操作过程为准,详细记录下来. 1.基本运行 ...
- Spark —— 高可用集群搭建
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark on Yarn集群搭建
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这五部机, 每部主机的用户名都为centos ...
- spark高可用集群搭建及运行测试
文中的所有操作都是在之前的文章spark集群的搭建基础上建立的,重复操作已经简写: 之前的配置中使用了master01.slave01.slave02.slave03: 本篇文章还要添加master0 ...
- hadoop - spark on yarn 集群搭建
一.环境准备 1. 机器: 3 台虚拟机 机器 角色 l-qta3.sp.beta.cn0 NameNode,ResourceManager,spark的master l-querydiff1.sp ...
- Apache Spark介绍及集群搭建
简介 Spark是一个针对于大规模数据处理的统一分析引擎.其处理速度比MapReduce快很多.其特征有: 1.速度快 spark比mapreduce在内存中快100x,比mapreduce在磁盘中快 ...
- Hadoop 集群搭建和维护文档
一.前言 -- 基础环境准备 节点名称 IP NN DN JNN ZKFC ZK RM NM Master Worker master1 192.168.8.106 * * * * * * maste ...
随机推荐
- docker启动、关闭、重启命令
docker启动命令,docker重启命令,docker关闭命令 启动 systemctl start docker守护进程重启 sudo systemctl daemon-relo ...
- CSS效果篇--这里有你想要的CSS3漂亮的自定义Checkbox各种复选框
在原来有一篇文章写到了<CSS效果篇--纯CSS+HTML实现checkbox的思路与实例>.这篇文章主要写各种自定义的checkbox复选框,实现如图所示的复选框: 大致的html代码都 ...
- 黑马vue---13、事件修饰符的介绍
黑马vue---13.事件修饰符的介绍 一.总结 一句话总结: .stop 阻止冒泡:input type="button" value="戳他" @click ...
- react 的基础知识
react 是目前最流行的框架: 其中是采用 mvvm 的思想,让我们把所有的只关注视图层和逻辑层, 从而可以更好的书写代码: 在 react 中我们的 html 结构也是通过 js 来实现的,而且在 ...
- 数据库开源框架之ormlite
主页: http://ormlite.com/ 配置: 添加以下依赖 * compile 'com.j256.ormlite:ormlite-android:4.48' * compile 'com. ...
- Ironic 的 Rescue 救援模式实现流程
目录 文章目录 目录 救援模式 实现 UML 图 救援模式 以往只有虚拟机支持救援模式,裸机是不支持的.直到 Queen 版本 Ironic 实现了这个功能.救援模式下,用户可以完成修复.Troubl ...
- webpack对vue单文件组件的解析
vue2.0 Step0: 首先vuelLoaderPlugin会在webpack初始化的时候 注入pitcher这个rule,然后将rules进行排序, [pitcher,...clonedRule ...
- 五十二:WTForms表单验证之基本使用
作用:1.做表单验证,把用户提交的数据验证是否合法2.做模板渲染 安装:pip install wtforms 表单验证1.自定义一个表单类,继承wtforms.Form2.定义好需要验证的字段,字段 ...
- MySQL 按照数据库表字段动态排序 查询列表信息
MySQL 按照数据库表字段动态排序 查询列表信息 背景描述 项目中数据列表分页展示的时候,前端使用的Table组件,每列自带对当前页的数据进行升序或者降序的排序. 但是客户期望:随机点击某一列的时候 ...
- linux网络管理命令"ip"用法
Linux的ip命令和ifconfig类似,但前者功能更强大,并旨在取代后者.使用ip命令,只需一个命令,你就能很轻松地执行一些网络管理任务. ip help命令: 显示ip相关命令的帮助: # i ...