模型压缩-ThiNet
转载:https://blog.csdn.net/u014380165/article/details/77763037
https://www.twblogs.net/a/5b8d02472b717718833929d6/zh-cn
GitHub网址:https://github.com/Roll920/ThiNet https://github.com/Roll920/ThiNet_Code
项目资料网址:http://lamda.nju.edu.cn/luojh/project/ThiNet_ICCV17/ThiNet_ICCV17_CN.html
论文:ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression - ICCV2017
论文链接:https://arxiv.org/abs/1707.06342
论文:ThiNet: Pruning CNN Filters for a Thinner Net - TPAMI2018
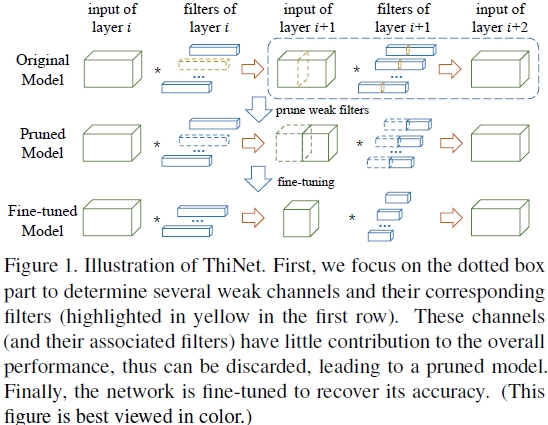
框架的流程图如上Figure1,第一行是filter selection,选择的依据是:如果我们可以用第i+1层的输入channel的一个子集作为第i+1层的输入且近似得到第i+1层的输出,那么这个子集以外的channel就可以去掉了,因为第i+1层的一个输入channel对应第i层的一个filter(卷积核),因此去掉第i+1层的channel同时也就可以去掉第i层的filter。第二行是prune,将第一步的weak channel和对应的前面一层的filter去掉,得到更窄(thin)的网络,这也是ThiNet名称的由来。第三行是Fine-tuning,这里为了节约时间,当对每一层做prune后,都fine-tune1到2个epoch,然后等所有层都prune后,再fine-tune多个epoch。因此整体上就是上面这三步迭代应用到每一层上,依次对每一层做prune。
去掉冗余filter做prune的研究还有很多,关键在于选择方式,比如计算filter的绝对值和,认为如果一个filter的绝对值和比较小,说明该filter并不重要,这种算法暂且叫Weight sum;还有计算激活层输出的feature map的值的稀疏程度,如果feature map的值很稀疏,也就是大部分值是0,那么该feature map对应的filter也是冗余的,可以去掉,这种算法暂且叫APoZ(Average Percentage of Zeros)。这两种压缩算法在后面的实验中都会提到。
效果:
在ILSVRC-12数据集上,在VGG16上能够降低3.31×的FLOPs,16.63×的网络参数,而top-5准确度下降仅为0.52%。
对于ResNet-50这样紧凑的网络,ThiNet也能减少超过一半的的参数与FLOPs,而top-5仅降低1%。
ThiNet能将VGG16网络模型剪枝到只有5.05MB的大小,保留AlexNet级别的精度,却拥有更强的泛化性能。
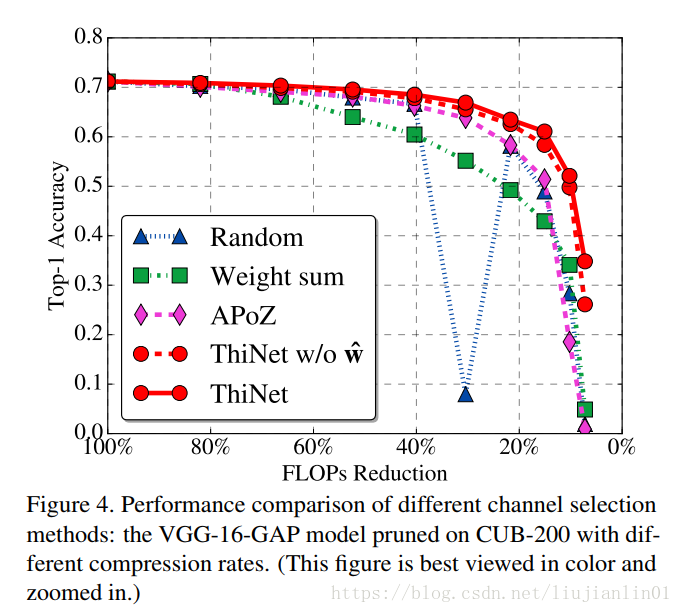
不同选择算法的性能比较:
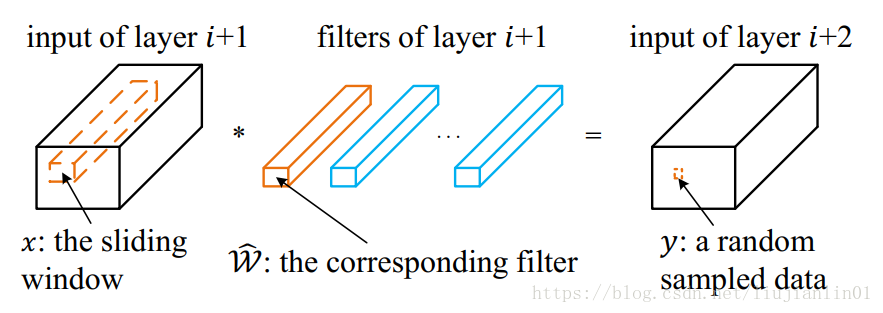
通道选择(数据驱动):
为了确定哪个通道可以安全移除,将收集用于重要性评估的训练集。如图所示,由y表示的元素从张量(ReLU之前)中进行随机采样。
通常,带偏置项b的卷积计算如下:
现在,如果我们定义:
便能将上面公式简化为:
这里 y^=y−b。 若我们能够找到一个通道子集S⊂{1,2,…,C},使得下式
总是成立,那么我们便能不再依赖于任何c∉S的通道。因此,这些通道(及其对应的filter)便能在不改变CNN网络模型精度的前提下被安全移除。当然,上面的公式不可能对于所有的x^与y^总保持成立。但我们可以手动提取一部分训练样本,来计算一个使得上式近似正确的子集S。
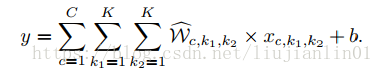
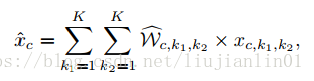
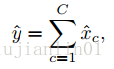
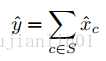
一种用于通道选择的贪心算法:
给定m(m由图片数量与位置数量决定)个训练样本{(x^i,y^i)},原通道选择问题可以转化为如下的优化问题:
这里,|S|为子集S的元素数量,r为预定义的压缩率(即保留多少个通道)。令T为被移除的通道集合(S∪T={1,2,…,C} 同时 S∩T=∅),我们便能最小化另一等价优化目标:
求解公式是一个NP难的问题,因此我们提出了一种快速的贪心算法进行求解。
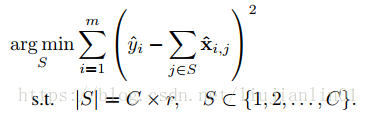
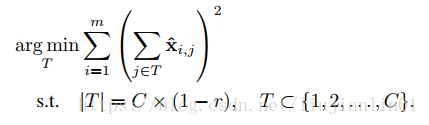

最小化重构误差:
在决定保留哪几个滤波器之后,我们可以通过对每一个通道赋予权重来进一步地减小重构误差。
上式可以通过普通的最小二乘法来求解。
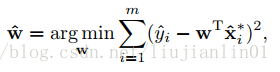
算法步骤:
1.filter选择。
使用layer(i + 1)的输入中的一个通道子集来逼近layer(i + 1)中的输出,则其他通道可以安全地从layer(i + 1)的输入中移除。layer(i + 1)的输入中的一个通道由第i层中的一个filter产生,因此可以同时修剪第i层中的相应filter。
2.修剪。
3.微调。
4.重复步骤1修剪下一层。
注意事项:
1)对于VGG-16网络,由于前面10层卷积占据了90%的计算量,而全连接层又占据了86%的参数,因此作者采用对前面10层卷积层进行prune,达到加速目的,另外将所有全连接层用一个global average pooling层代替。
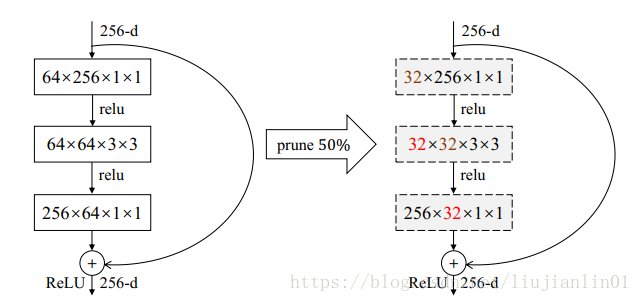
2)对于ResNet网络,作者采用只对一个block的前两层卷积做prune,而不动最后一个卷积层,如下图。
模型压缩-ThiNet的更多相关文章
- 模型压缩,模型减枝,tf.nn.zero_fraction,统计0的比例,等。
我们刚接到一个项目时,一开始并不是如何设计模型,而是去先跑一个现有的模型,看在项目需求在现有模型下面效果怎么样.当现有模型效果不错需要深入挖掘时,仅仅时跑现有模型是不够的,比如,如果你要在嵌入式里面去 ...
- CNN 模型压缩与加速算法综述
本文由云+社区发表 导语:卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,CNN模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一. 前言 自从AlexNet一举夺得 ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- tensorflow 模型压缩
模型压缩 为了将tensorflow深度学习模型部署到移动/嵌入式设备上,我们应该致力于减少模型的内存占用,缩短推断时间,减少耗电.有几种方法可以实现这些要求,如量化.权重剪枝或将大模型提炼成小模型. ...
- 【模型压缩】MetaPruning:基于元学习和AutoML的模型压缩新方法
论文名称:MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning 论文地址:https://arxiv.org/ ...
- 模型压缩-Learning Efficient Convolutional Networks through Network Slimming
Zhuang Liu主页:https://liuzhuang13.github.io/ Learning Efficient Convolutional Networks through Networ ...
- 模型压缩一半,精度几乎无损,TensorFlow推出半精度浮点量化工具包,还有在线Demo...
近日,TensorFlow模型优化工具包又添一员大将,训练后的半精度浮点量化(float16 quantization)工具. 有了它,就能在几乎不损失模型精度的情况下,将模型压缩至一半大小,还能改善 ...
- 对抗性鲁棒性与模型压缩:ICCV2019论文解析
对抗性鲁棒性与模型压缩:ICCV2019论文解析 Adversarial Robustness vs. Model Compression, or Both? 论文链接: http://openacc ...
- 模型压缩95%:Lite Transformer,MIT韩松等人
模型压缩95%:Lite Transformer,MIT韩松等人 Lite Transformer with Long-Short Range Attention Zhanghao Wu, Zhiji ...
随机推荐
- 15.Vue组件中的data
1.组件中展示数据和响应事件: // 1. 组件可以有自己的 data 数据 // 2. 组件的 data 和 实例的 data 有点不一样,实例中的 data 可以为一个对象 // 3. 但是组件中 ...
- idou教你学Istio10 : 如何用Istio实现K8S Egress流量管理
上一篇我们了解了如何控制入口流量,本文主要介绍在使用Istio时如何访问集群外服务,即对出口流量的管理. 默认安装的Istio是不能直接对集群外部服务进行访问的,如果需要将外部服务暴露给 Istio ...
- 编码、加密、Hash
今天没有编码,还是属于纯理论的东东,概念也比较多,但是实际真正完全理解它们的人不多,也很重要,这些东东在实际中也经常被用到,但需要真正理解了才能正确的使用它们,这里列一下相关司:MD5.SHA1.RS ...
- BZOJ 3716 [PA2014]Muzeum 贪心SET最大闭合子图
看上去像是一个最大权闭合子图裸题但是数据太大 我们可以先把守卫的视野转换到第二象限(每个守卫可以看到横坐标比他小 纵坐标比他大的宝物) 然后按X从小到大 再按Y从大到小排 这样我们就可以按SORT序遍 ...
- MySQL进阶8 分页查询(limit) - 【SQL查询语法执行顺序及大致结构】- 子查询的3个经典案例
#进阶8 分页查询 /* 应用场景: 当要显示的数据,一页显示不全,需要分页提交sql请求 语法: select 查询列表 #7 from 表1 #执行顺序:#1 [join type join 表2 ...
- 小白学Python | 最简单的Django 简明教程
作者:浅雨凉 来源:http://www.cnblogs.com/qianyuliang/p/6814376.html 一.Django简介 1. web框架介绍 具体介绍Django之前,必须先介绍 ...
- python_网络编程socket(UDP)
服务端: import socket sk = socket.socket(type=socket.SOCK_DGRAM) #创建基于UDP协议的socket对象 sk.bind(('127.0.0. ...
- JSP基础语法总结
任何语言都有自己的语法,Java中有.JSP虽然是在Java上的一种应用,但是依然有其自己扩充的语法,而且在Jsp中,所有Java语句都可以使用. 一.Jsp的模板元素 Jsp页面中的HTML内容称为 ...
- selenium报错以及各解决方法
1.driver.findElement(By.name("wd")).sendKeys("selenium"); 报错:The method sendKeys ...
- Appium自动化测试教程-自学网-monkey事件
操作事件简介 Monkey所执行的随机事件流中包含11大事件,分别是触摸事件.手势事件.二指缩放事件.轨迹事件.屏幕旋转事件.基本导航事件.主要导航事件.系统按键事件.启动Activity事件.键盘事 ...