elk之logstash
环境:
centos7
jdk8
1.创建Logstash源
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
touch /etc/yum.repos.d/logstash.repo
vi /etc/yum.repos.d/logstash.repo
[logstash-.x]
name=Elasticsearch repository for .x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=
autorefresh=
type=rpm-md
2.使用yum安装logstash
yum makecache
yum install logstash -y
3.利用 log4j 搜集日志
a.pom.xml 引入
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.</version>
<scope>provided</scope>
</dependency>
b.log4j.properties添加
log4j.rootLogger = debug, socket
log4j.appender.socket=org.apache.log4j.net.SocketAppender
log4j.appender.socket.Port=
log4j.appender.socket.RemoteHost=192.168.158.128
log4j.appender.socket.layout = org.apache.log4j.PatternLayout
log4j.appender.socket.layout.ConversionPattern = %d [%t] %-5p %c - %m%n
c.在logstash服务器上添加配置 log4j-to-es.conf
output 是输出到elasticsearch,可翻阅前面的文章 elk之elasticsearch安装
input {log4j {type => "log4j-json" port => }}
output {
elasticsearch {
action => "index"
hosts => "192.168.158.128:9200"
index => "applog"
}
}
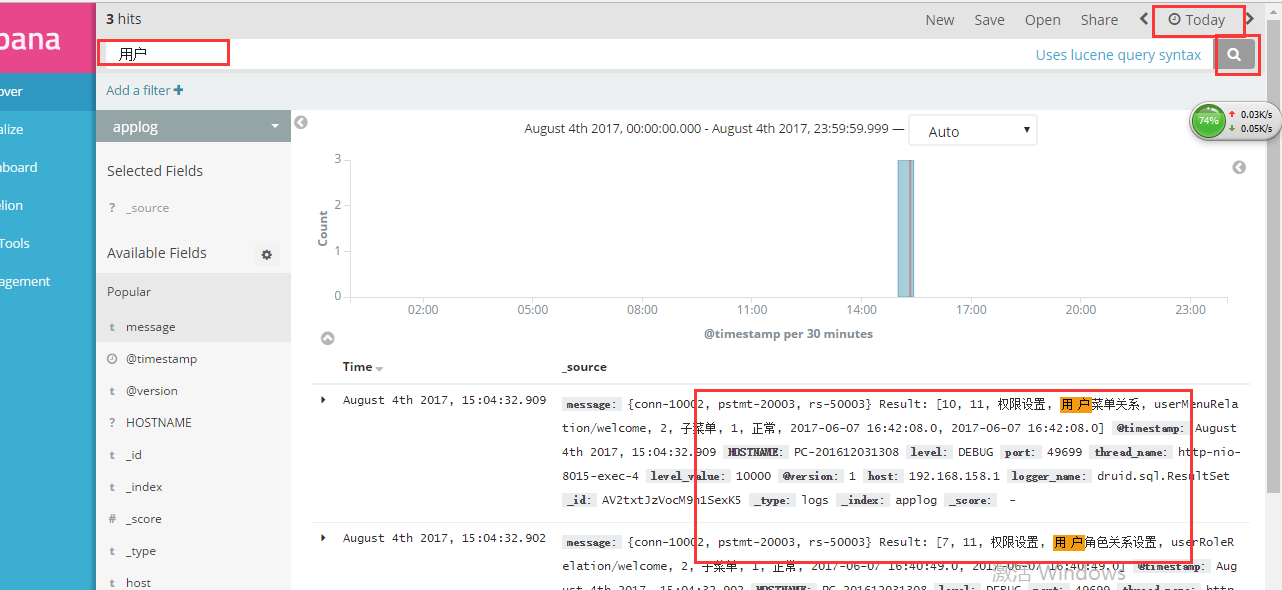
然后重启 logstash ,打开kibana 指定 index or pattern 为我们这里配置的 applog,设置搜索时间就可以查看到日志了
4.利用logback 搜集日志
a.pom.xml 引入
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.6</version>
</dependency>
b.配置logback.xml,添加appender
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 文件输出格式 -->
<property name="PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{50} - %msg%n" />
<!-- test文件路径 -->
<property name="LOG_HOME" value="C:/Users/Administrator/Desktop/logs" /> <!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符 -->
<pattern>${PATTERN}</pattern>
</encoder>
</appender> <!-- logstash 收集日志 -->
<appender name="stash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.158.128:</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" />
</appender> <!-- 按照每天生成日志文件 -->
<appender name="FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件输出的文件名 -->
<FileNamePattern>${LOG_HOME}/yun.%d{yyyyMMdd}.log
</FileNamePattern>
<!--日志文件保留天数 -->
<!-- <MaxHistory></MaxHistory> -->
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符 -->
<pattern>${PATTERN}</pattern>
</encoder>
<!--日志文件最大的大小 -->
<triggeringPolicy
class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>500MB</MaxFileSize>
</triggeringPolicy>
</appender> <logger name="org.springframework.web" level="DEBUG" additivity="false">
<appender-ref ref="STDOUT" />
</logger> <logger name="druid.sql" level="DEBUG" additivity="false">
<appender-ref ref="FILE" />
<appender-ref ref="STDOUT" />
<appender-ref ref="stash" />
</logger>
<logger name="com.yun" level="DEBUG" additivity="false">
<appender-ref ref="FILE" />
<appender-ref ref="STDOUT" />
<appender-ref ref="stash" />
</logger> <!-- 日志输出级别 -->
<root level="DEBUG">
<appender-ref ref="FILE" />
<appender-ref ref="STDOUT" />
<appender-ref ref="stash" />
</root>
</configuration>
c.logstash服务器上添加配置 logback-to-es.conf
input {tcp {port => codec => "json_lines"}}
output {
elasticsearch {
action => "index"
hosts => "192.168.158.128:9200"
index => "applog"
}
}
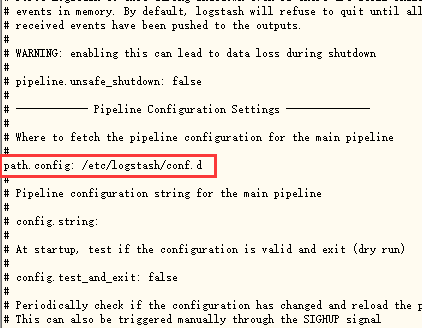
配置目录请认准 /etc/logstash/conf.d
可以打开 logstash.yml 查看 cat /etc/logstash/logstash.yml
d.重启logstash,启动项目产生日志,然后去kibana 查看日志
5.利用filebeat搜集日志
elk之logstash的更多相关文章
- 使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践--转载
原文地址:https://wsgzao.github.io/post/elk/ 另外可以参考:https://www.digitalocean.com/community/tutorials/how- ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- [转] ELK 之 Logstash
[From] https://blog.csdn.net/iguyue/article/details/77006201 ELK 之 Logstash 简介: ELK 之 LogstashLogsta ...
- CentOS 6.x ELK(Elasticsearch+Logstash+Kibana)
CentOS 6.x ELK(Elasticsearch+Logstash+Kibana) 前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案, ...
- 基于CentOS6.5或Ubuntu14.04下Suricata里搭配安装 ELK (elasticsearch, logstash, kibana)(图文详解)
前期博客 基于CentOS6.5下Suricata(一款高性能的网络IDS.IPS和网络安全监控引擎)的搭建(图文详解)(博主推荐) 基于Ubuntu14.04下Suricata(一款高性能的网络ID ...
- 键盘侠Linux干货| ELK(Elasticsearch + Logstash + Kibana) 搭建教程
前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案,分析网站的访问情况时我们一般会借助 Google / 百度 / CNZZ 等方式嵌入 JS ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- ELK——安装 logstash 2.2.0、elasticsearch 2.2.0 和 Kibana 3.0
本文内容 Elasticsearch logstash Kibana 参考资料 本文介绍安装 logstash 2.2.0 和 elasticsearch 2.2.0,操作系统环境版本是 CentOS ...
- CentOS 7.x安装ELK(Elasticsearch+Logstash+Kibana)
第一次听到ELK,是新浪的@ARGV 介绍内部使用ELK的情况和场景,当时触动很大,原来有那么方便的方式来收集日志和展现,有了这样的工具,你干完坏事,删除日志,就已经没啥作用了. 很多企业都表示出他们 ...
- ELK(ElasticSearch, Logstash, Log4j)系统日志搭建
1.elk平台介绍 Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等. Logsta ...
随机推荐
- Java类成员变量的默认值
1.布尔型(boolean)变量默认值为false,byte.short.int.long为0,字符型为'\u0000'(空字符),浮点型(float double)为0.0,引用类型(String) ...
- 利用Vistual Studio自带的xsd.exe工具,根据XML自动生成XSD
利用Vistual Studio自带的xsd.exe工具,根据XML自动生成XSD 1, 命令提示符-->找到vs自带的xsd.exe工具所在的文件夹 例如: C:\Program Files ...
- wdcp环境安装filephp扩展
网址 :https://blog.csdn.net/m_nanle_xiaobudiu/article/details/80838424
- gitlab 集成Jenkins
项目:使用git+jenkins实现持续集成 开始构建 General 源码管理 我们安装的是Git插件,还可以安装svn插件 我们将git路径存在这里还需要权限认证,否则会出现error 我 ...
- Beautiful Paintings CodeForces - 651B (贪心)
大意: 给定序列$a$, 可以任意排序, 求最大下标i的个数, 满足$a_i<a_{i+1}$. 这个贪心挺好的, 答案就为n-所有数字出现次数最大值.
- IntelliJ Idea设置单击打开文件或者双击打开文件、自动定位文件所在的位置
- kohana操作数据库
一.读取数据库记录 读取数据库记录需要使用到 DB::select() 方法 // 返回一个结果对象 $result = DB::select('column')->from('table_na ...
- 转-如何使用iTunes制作iPhone铃声
新版iTunes(iTunes11)推出以后,界面上发生了一些改变,给人带来一种面貌一新的感觉,但也给许多朋友带来一些操作上的不太适应.下面就大家比较关心的iPhone的铃声制作方法,我在iTunes ...
- 转-【exp/imp】将US7ASCII字符集的dmp文件导入到ZHS16GBK字符集的数据库中
原帖地址:http://blog.csdn.net/lihuarongaini/article/details/71512116 1.2 前言部分 1.2.1 导读和注意事项 各位技术爱好者,看完 ...
- python中sorted和.sorted 、reversed和reverse的注意点
L=[1,2,3,4]l1=[123,123,23]if l1.sort() == L.reverse(): #这个判断式是恒等的,因为两个函数的返回值都是None(其实是无返回值) pri ...