Deep Learning系统实训之一:深度学习基础知识
K-近邻与交叉验证
1 选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好的那个。
2 如果训练数据量不够,使用交叉验证法,它能帮助我们在选取最优超参数的时候减少噪音。
3 一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
4 最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试时过于消耗计算能力。
5 最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体本身。
1 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。
2 如果数据是高维数据,考虑使用降维方法。如PCA。
3 将数据随机分入训练集和验证集。按照一般规律,70%-90%数据作为训练集。
4 在验证集上调优,尝试足够多的K值,尝试L1和L2两种范数计算方式。
超参数(曼哈顿距离与欧氏距离):

损失函数:
任何一个算法都会有一个损失函数。
我们希望损失为零,为什么呢?损失越多说明我们错的越多,损失为零说明我们没做错啊。o(* ̄︶ ̄*)o

Softmax分类器:
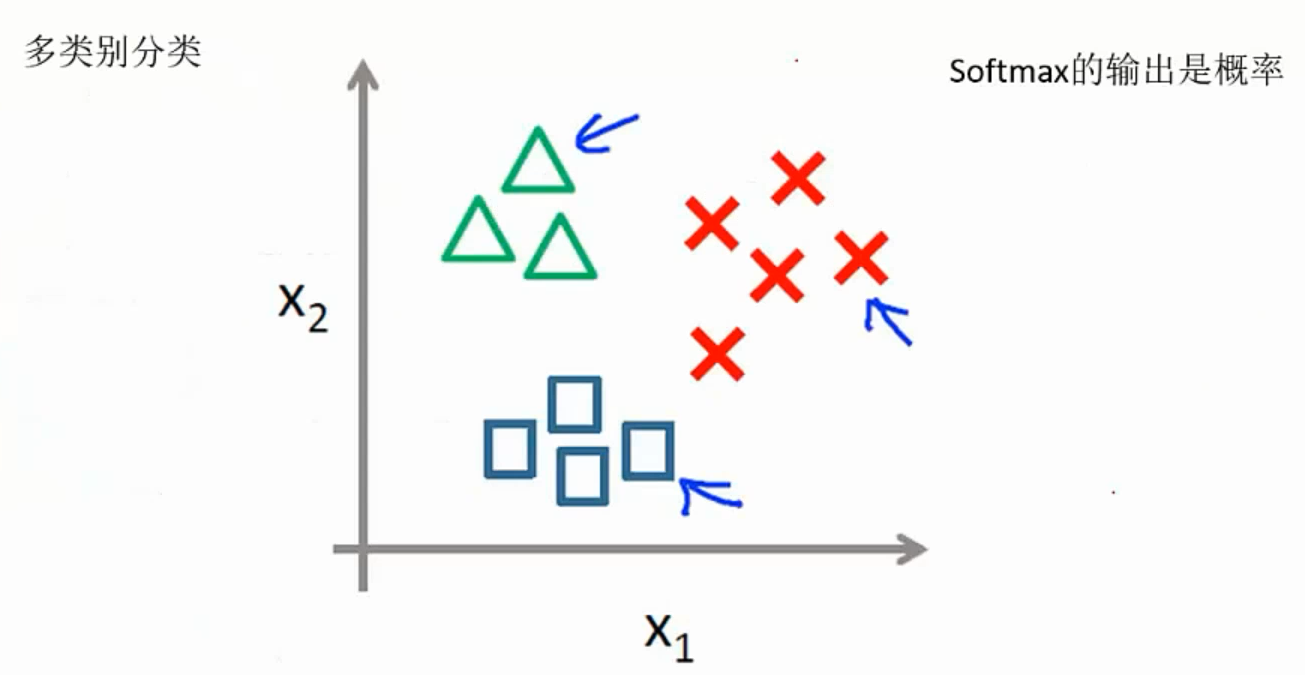
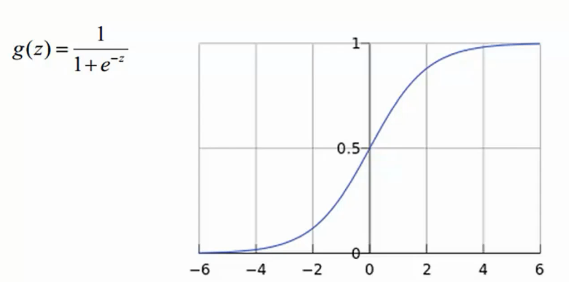
Sigmoid函数:

softmax实例:

Deep Learning系统实训之一:深度学习基础知识的更多相关文章
- Deep Learning系统实训之三:卷积神经网络
边界填充(padding):卷积过程中,越靠近图片中间位置的像素点越容易被卷积计算多次,越靠近边缘的像素点被卷积计算的次数越少,填充就是为了使原来边缘像素点的位置变得相对靠近中部,而我们又不想让填充的 ...
- Deep Learning系统实训之二:梯度下降原理
基本概念理解: 一个epoch:当前所有数据都跑(迭代)了一遍: 那么两个epoch,就是把所有数据跑了两遍,三个epoch就是把所有数据跑了三遍,以此类推. batch_size:每次迭代多少个数据 ...
- 吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 1 - Practical aspects of deep learning(第一周测验 - 深度学习的实践)
Week 1 Quiz - Practical aspects of deep learning(第一周测验 - 深度学习的实践) \1. If you have 10,000,000 example ...
- Predicting effects of noncoding variants with deep learning–based sequence model | 基于深度学习的序列模型预测非编码区变异的影响
Predicting effects of noncoding variants with deep learning–based sequence model PDF Interpreting no ...
- deep learning framework(不同的深度学习框架)
常用的deep learning frameworks 基本转自:http://www.codeceo.com/article/10-open-source-framework.html 1. Caf ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
随机推荐
- 当input获取倒焦点的时候,获得输入内容
描述:当用户点击输入框时,获取到他在input里输入的内容 $().keyup(function(){ $(this).val(); }) $(this).val()==this.value; $(t ...
- location的三种连接方式和区别
location.href是一个属性,要这样使用:location.href='http://www.example.com'而location.assign('http://www.example. ...
- 1032. Sharing (25)
To store English words, one method is to use linked lists and store a word letter by letter. To save ...
- selenium_采集药品数据2_采集所有表格
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- brctl创建虚拟网卡详解
brctl创建虚拟网卡详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 很久之前我分享过一篇关于搭建Openvpn的笔记,在笔记的最后我分享了一个脚本,是用来创建虚拟网卡的,今天 ...
- check nginx配置文件错误:[emerg]: getpwnam(“nginx”) failed
1.错误提示: [root@server include]# /application/nginx/sbin/nginx -t -c /applications/nginx/nginx/nginx.c ...
- Centos下新建用户及修改用户目录
Centos下新建用户及修改用户目录 Hillgo 关注 2015.09.22 01:32* 字数 154 阅读 3492评论 0喜欢 3 添加及删除用户 添加用户 test: adduser tes ...
- postgresql时间处理
时间取到截取 例:select date_trunc('second', "reportTime") from travel_message limit 10; 结果: 他人博客: ...
- 〖C语言学习笔记 〗(二) 数据类型
前言 本文为c语言的学习笔记,很多只是留下来占位的 数据类型 助记:变量就是在内存中挖个坑并给这个坑命名,而数据类型就是挖内存的坑的尺寸 基础类型 整数类型: short int int long i ...
- B树学习总结
1,B树的基本介绍 ①B树,相比于二叉树.红黑树而言,它的特点就是树的高度比其他类型的树要低很多.如何做到低呢?B树中的每个结点的分支数目非常大,即每个结点有很多很多孩子结点.这样,在相同结点数目情况 ...