Generative Adversarial Nets(原生GAN学习)
学习总结于国立台湾大学 :李宏毅老师
Author: Ian Goodfellow
• Paper: https://arxiv.org/abs/1701.00160
• Video: https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks
一. 限制玻尔兹曼机 RBM (Restricted Boltzmann Machine)
二. 自编码器 AE (Auto-encoder) & 变分自动编码器VAE(Variational Auto-encoder)

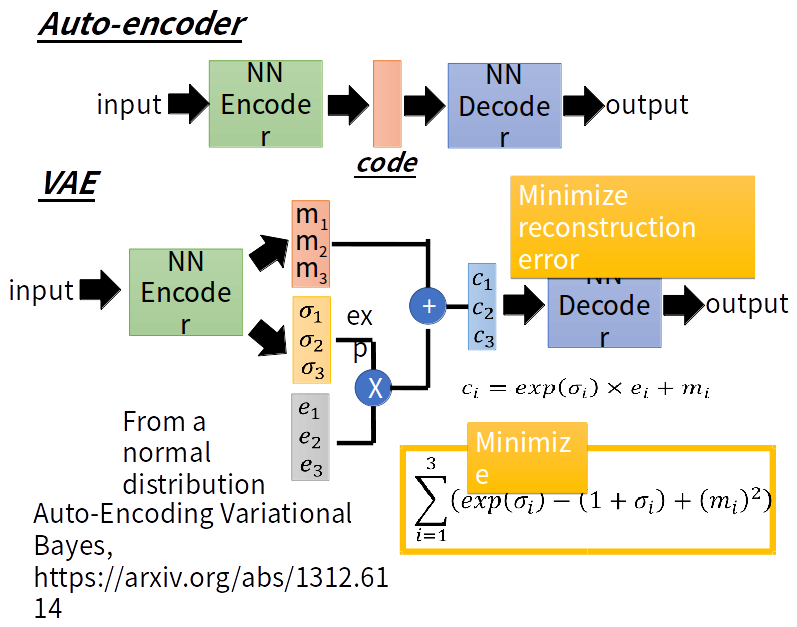
学习编码解码过程,然后任意输入一个向量作为code通过解码器生成一张图片。
VAE与AE的不同之处是:VAE的encoder产生与noise作用后输入到decoder
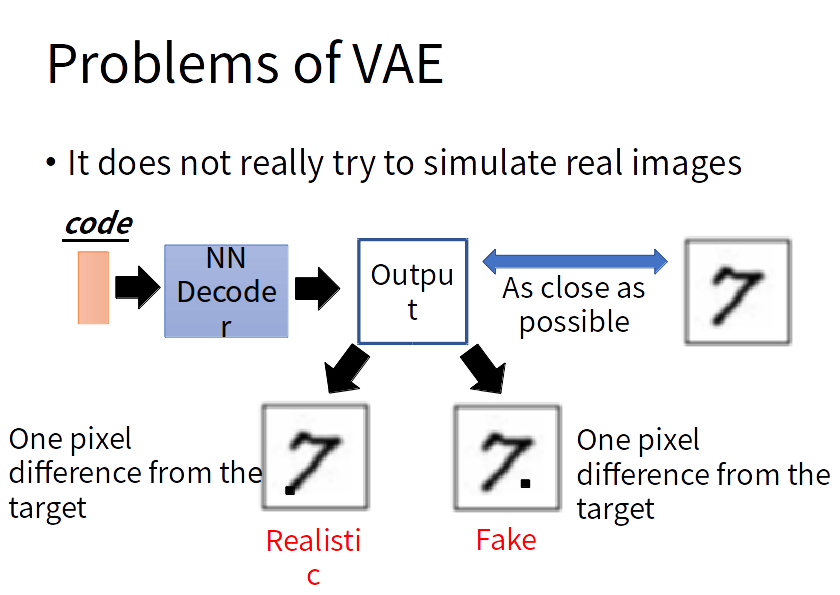
VAE的问题:VAE的decoder的输出与某一张越接近越好,但是对于机器来说并没有学会自己产生realistic的image。它只会模仿产生的图片和database里面的越像越好,而不会产生新的图片。
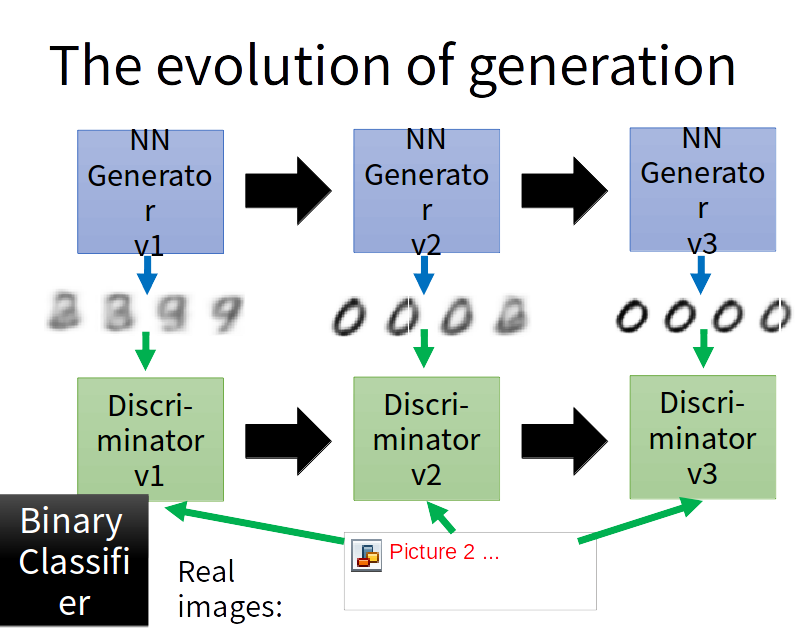
GAN
GAN的生成器与VAE的decoder一样,GAN的判别器为 1/0 (real/fake)的二分类器。
GAN的第一代生成器生成的图片经过判别器得到一个相似度判定,GAN的第二代生成器由梯度下降在第一代生成器的基础上生成,要能够骗过第一代的判别器,也就是说第二代生成器产生的图片与真实图片通过第一代判别器结果需要接近1。
首先引入最大似然估计:Maximum Likelihood Estimation
由全体图片得到其分布:Pdata(x) . 那么假如它代表全体动漫人物头像的分布,如果我们想凭空照一张图片服从此分布,可能得找一个漫画家来帮我们画一张图,这太麻烦,所以我们想有自己的一个分布,由我们自己操控,可以得到和Pdata(x)一样的分布(逼近Pdata(x))。那么假如我们自己的分布为PG(x; θ) , 而参数θ有我们控制,我们想另PG(x; θ)越接近Pdata(x)越好。 特别的比如说PG(x; θ) 可为高斯混合模型,θ为高斯均值与方差,我们想找到一个合适的θ来实现PG(x; θ)与Pdata(x)的接近。那怎么做呢?可以这样,从Pdata(x)中采样m个样本,已知θ我们可以计算出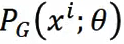 ,那么生成样本的似然函数为:
,那么生成样本的似然函数为:
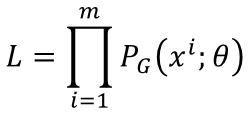
也就是给定 一组高斯混合的θ 可以得到似然函数,我们需要找到一组合适的 θ,使这个似然函数最大。一般似然函数都要取log变乘法为加法,单调性不变。

那么 要找的 θ 即使似然函数值最大:
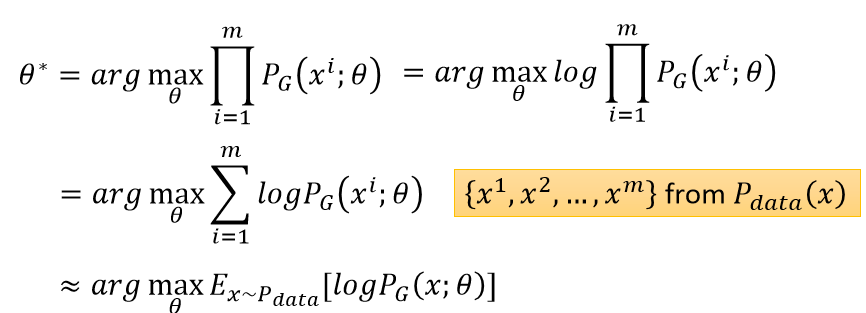
注意上图的约等于是因为不可能将全体样本都找出来,只是采样一些样本,所以是近似等于满足Pdata 这一分布的x的期望值,进一步,θ等于:
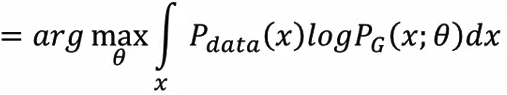
为了将最大似然转换为最小化KL divergence(KLD),此式子后面再减掉一项和θ无关的式子,即为θ等于: 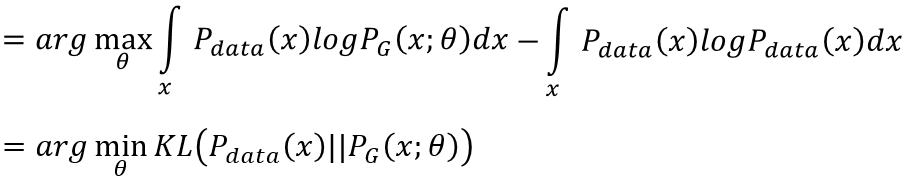 1)
1)
上式推导过程:
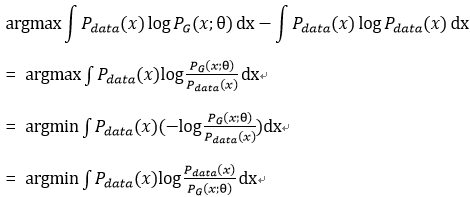
由Gibbs吉布斯不等式:
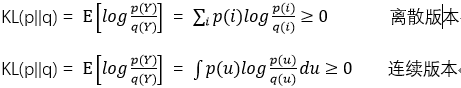
故得到1)式结果。
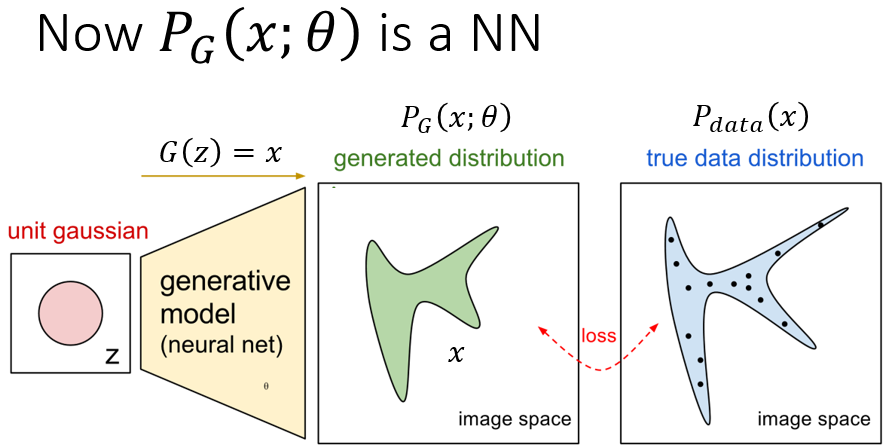
那么怎么获得一个很普遍的,很general的PG(x; θ)呢,按照前面所说,这个可以为高斯混合模型,但它不具有普遍性,所以它生成的图会很模糊。高斯混合模型与Pdata(x)差太多,无法真的模拟Pdata的分布并逼近Pdata(x)。所以gan带给我们第一个好处是令网络来作为PG(x; θ)去逼近Pdata(x)。
此时,PG(x; θ)为一个NN(neural network).我们令G(z) = x. 其中z为NN输入,x为NN的输出,例如z为输入的vector,那么x可以为一张图片,x为图像空间。假设z是从unit gaussian(单位高斯分布)中采样得到,那么x就是输出对应的分布,所谓输入为分布,输出为分布。可能会有人问输出的x会不会没有模拟复杂分布的能力呢,会不会x很接近z的分布呢?不会的。因为NN的非线性能力很强大,几乎可以模拟任意分布。所以现在我们的任务就是去寻找一个网络的参数 θ,使得这个网络可以将输入转化到另一个分布,而让这个生成的分布接近于Pdata(x)就好。即下图:
那么,这个NN网络PG(x; θ)的形式写出来是什么样子呢?
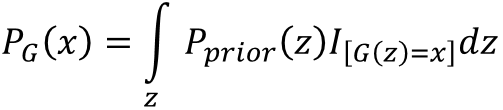
但是这个形式无法算出似然函数。那么GAN的最大贡献就是调整生成器的参数 θ,使得生成器产生的分布可以逼近data的分布。
GAN的基本思想:
 G和D都为函数,z作为输入是从一个已知分布采样的来,将z输入G得到x,那么PG(x)就是由G决定的x的分布。
G和D都为函数,z作为输入是从一个已知分布采样的来,将z输入G得到x,那么PG(x)就是由G决定的x的分布。
判别器怎么计算两个分布的divergence呢,先定义一个函数,计算下面的函数V(G, D):
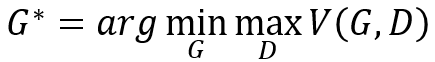 2)
2)
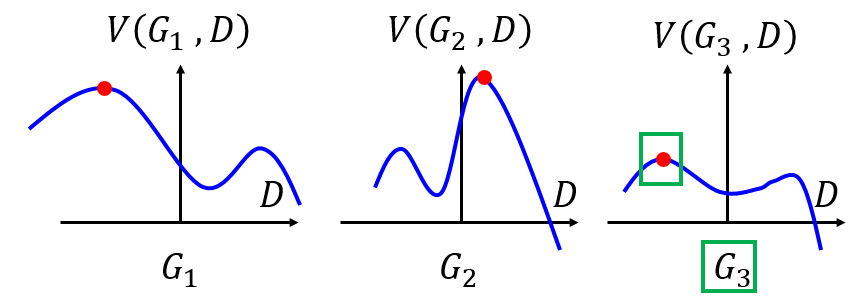
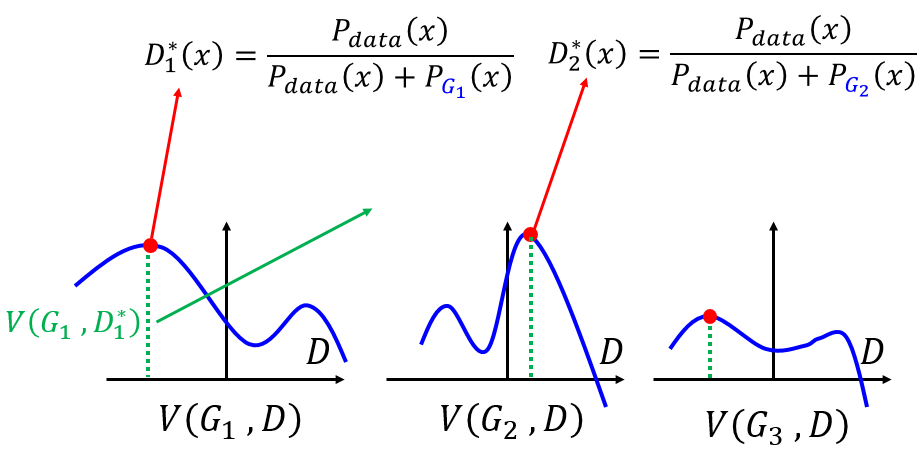
V(G,D)的意义是给定一个生成器和判别器来得到一个数值。这个式子怎么理解,有最大和最小化。我们分步骤来看:首先maxV(G,D)这个式子。假定生成器G已经给定且有三种情况,分别为三种不同的生成器G1,G2,G3,那么max(G,D)取值分别为下图中的红点:然后再看min这项,就是在三个最大值中找一个最小值,即下图中的G3对应的绿框:
先给出V的定义:
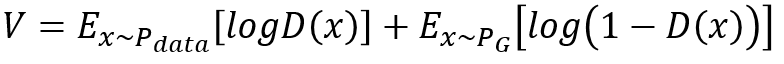 3)
3)
那么V的这个定义使得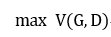 是什么意思呢?V是divergence(差异的简写),就是说给定一个生成器G, 评估PG和Pdata的差异性。
是什么意思呢?V是divergence(差异的简写),就是说给定一个生成器G, 评估PG和Pdata的差异性。
那为啥是这样呢,为啥V这样定义就可以衡量G,D的差异?解释如下: 给定G,那么D可以有任何取值,有如下式子:
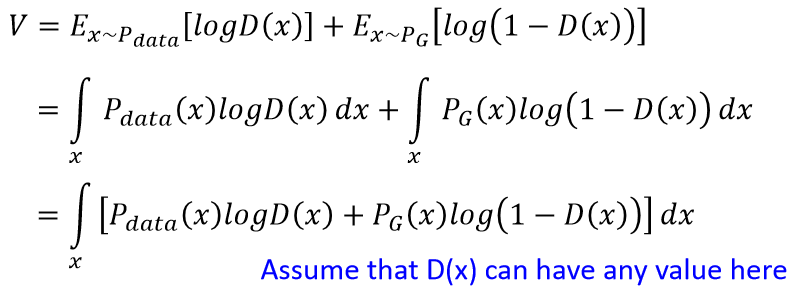
要最大V(G,D),就是最大化上面中括号里的式子,就是说给定G,找一个D来让V,也就是中括号里的式子最大:
- 假设已知G,求D:
那么data分布是给定的,G也是给定的,那么Pdata 和 PG 都看作scalar,所以有下面式子:
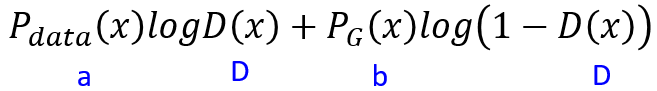
上式求D就很简单了,简单微分移项就可以:
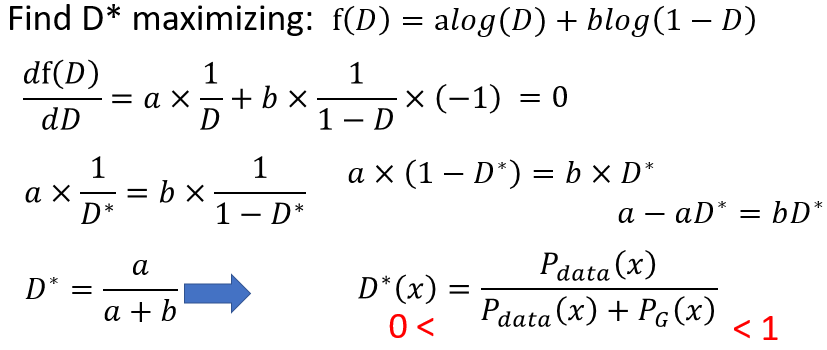
所以要找的最好的D处于0~1之间。目前实现了每给定一个G,就可以找到一个最好的D,见下图,不同的G可以找到对应这个G的最好的D,V(G,D)就是此时函数的高:
将D的形式带入3)式V的表达式:
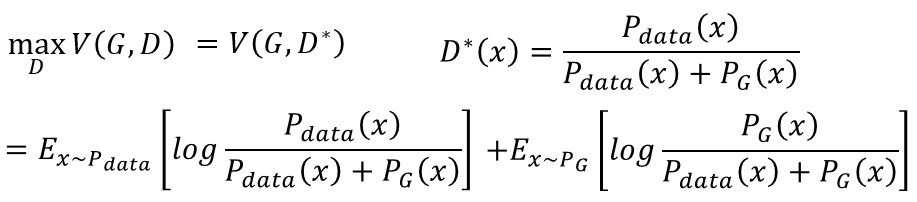
对上面式子分子分母同乘以1/2,然后提出来:
 4)
4)
所以证明了maxV(G,D) 等价于 JSD,也就是一种衡量diergence的手段。JSD的取值范围在 0~log2 之间。也就是说这两个分布完全一样即JSD=0,若完全不一样则JSD=log2.
上式就是maxV(G,D),而目标是2)式,2)中min这一步就是要使得4)式子最小。即找一个G使得4)式最小,从上面看到4)最小时对应于Pdata和PG这两个分布完全相同,此时JSD为0.
也就是说最好的G能使得: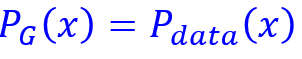
- 此时给定G,就有由G确定的D,此时根据D选择最好的G:
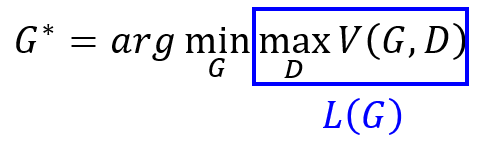 5)
5)
5)式子中,因为每每给定G,就能确定下maxV(G,D),所以max这一项可以看作只受G影响,故作L(G). L(G)就是生成器G的loss函数! 那么此时找G的过程就变成了梯度下降法:
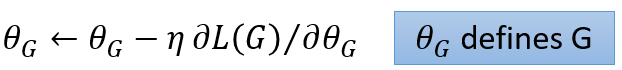
有人说L里面有max项,可以微分吗,答案是可以的。max操作可以看作是分段函数:
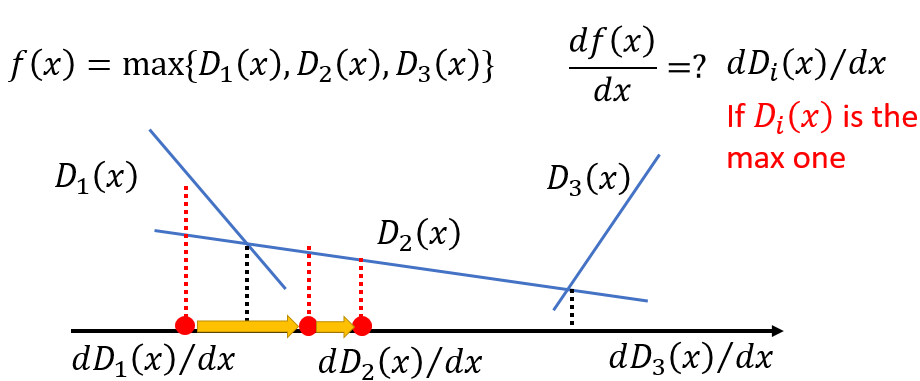
迭代算法如下:每给定G,根据最大V(G,D)的过程得到一个D,然后去梯度下降L(G)去找到下一个G....
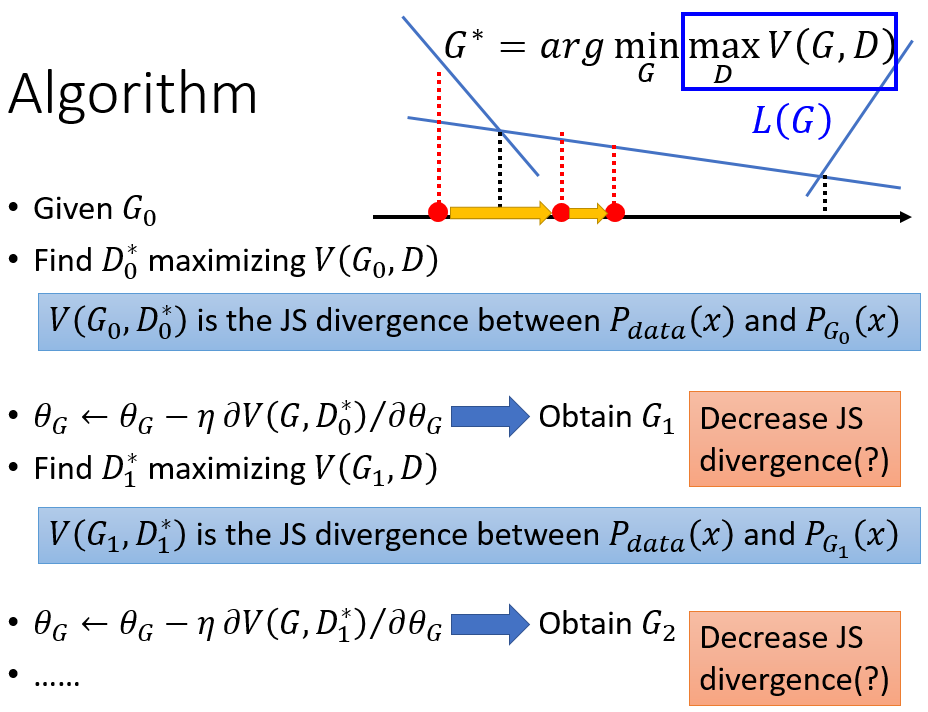
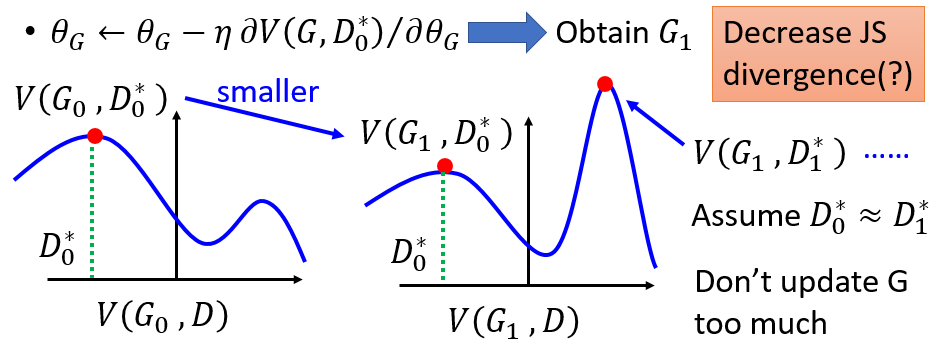
但这样有个问题,update G的时候可能不小心更新太多,使得V(G1,D)不会变的比V(G0, D)小。而我们看看2)式的目的是不断使得G和D的divergence也就是V(G,D)变小,如下图这样就可能使得divergence不减反增:
以上为理论,下面为具体实现:
我们无法对Pdata和PG真的做积分,因为他们都是真实的所有图像空间的分布,但我们能分别从两个分布中抽样:
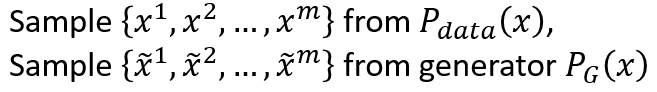
所以max 3)式变成了:
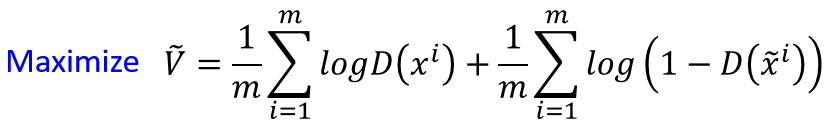 6)
6)
6)式很熟悉,就是二分类器的交叉熵损失函数: D的意义就是一个二分类器
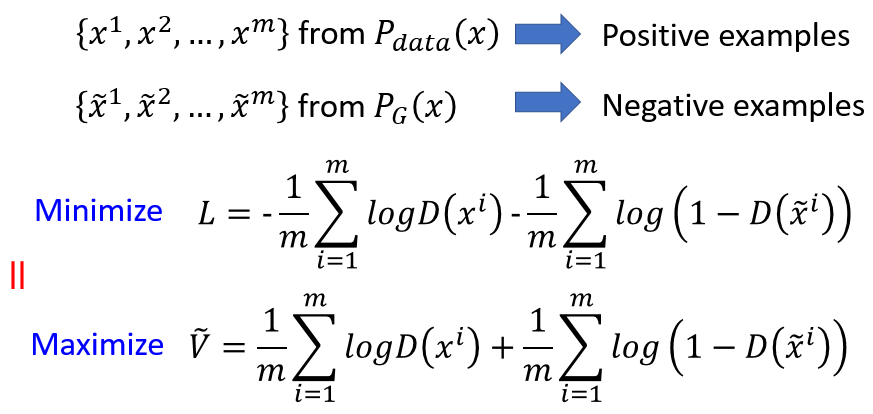
所以要maxV(G,D),就是找到一个D来最大化JS divergence,然而找这个D的过程相当于最小化一个二分类器的损失函数L。怎么理解这个等式呢?
就是说给定两个分布,分别生成正负样本,如果L损失值很大,也就是说无法分辨出来正负两个样本,同时说明了JS divergence很小,即这两个分布确实很相似。同理,若L损失很小,即正负样本很好区分,也侧面说明这两个分布很不相似,即JS divergence很大。
Q:那么怎么训练呢?训练过程:

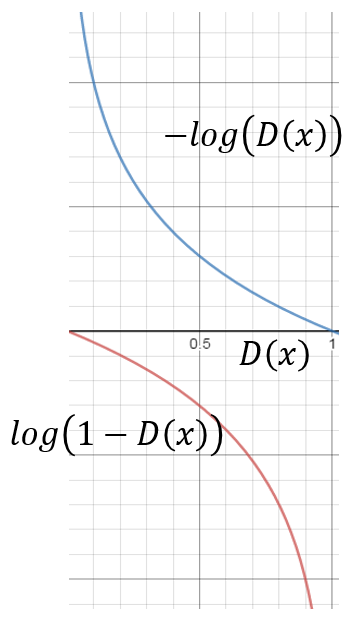
上图左,首先给定一个初始的G(固定G),学习D的过程为最大化V。要重复多次,因为多次才能找到D可以让V(G,D)最大,实际也只能找到一个局部最优。因为要mxmize,所以采用梯度上升。下面式学习G的过程是最小化V,所以是梯度下降。而G只出现在式子的第二项,所以可以将与生成器无关的第一项删掉,所以只需更新一次就可以了(上面说的G更新太大可能使得divergence不降反增)。其实原作者说学习D的过程也1次就好了。
问题又出来了,实操时3)式其实只要后半部分就好了。D(X)值小的意思(值越小代表fake,越大代表True)是现在generaor生成的x会无法骗过判别器。初始generator产生的东西会很容易被判别器发现。所以一开始D(X)值很小。然而看图知道刚开始其微分也很小,训练会很慢。所以要改一下V的表达式:
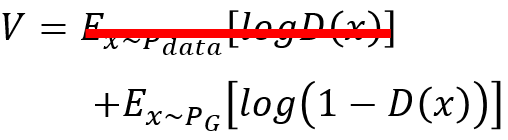 改为:
改为: 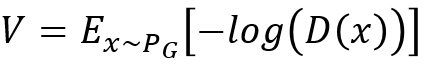
上图右, 看到表达式修改后,两者单调性不变,但是改变的是后者在D(X)很小的时候,生成的X集中在最左边,判别器很容易将他们判为fake,并且初始的微分很大,训练也快,到后面生成器越来越厉害,D(X)的值越来越大,生成的结果越来越难以辨别,同时训练也慢了下来。
实操问题:
WGAN等论文提出这样优化V的时候是优化一个很奇怪的divergence,但这样做也有好处:真正实现的时候是以PG产生的结果为正样本positive。
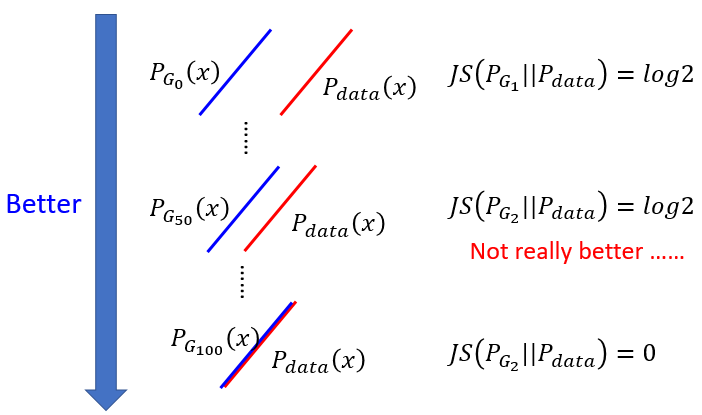
其他论文指出 discriminator的loss就是衡量JS divergence。loss大divergence就大。 随意可以依靠JS divergence的值来调generator。但这是理想状况。对于JS divergence 由判别器给出的信息非常少。并且discriminator的损失值loss多数几乎为零,且无变化。见下图:下图(上)中有三种discriminator。25轮的那个判别器已经是最好的了,但是它对应的判别器的accuracy还是1.0,即loss为0。就是说这么好的generator生成的图片,被判别器一眼识别出来(判别器accuracy=1)。下图(下)两个不同的generator能力不同,weak generaotr无法生出有意义的图片,而strong generator可以生出逼真的图片,但是两者的disciminator的loss都几乎为零,无区分度。
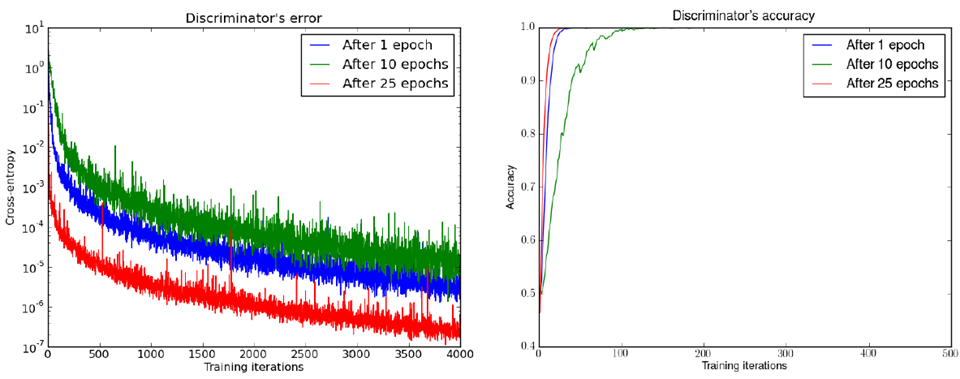
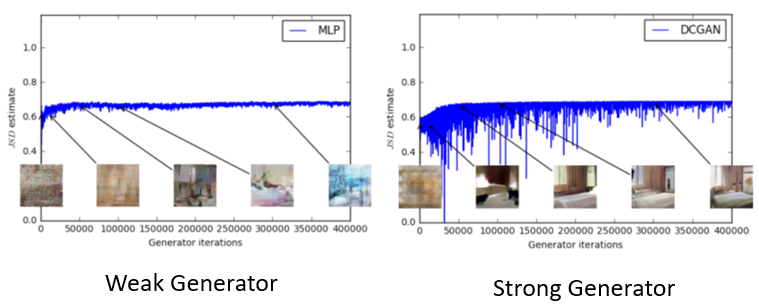
此图来自paper:Martin Arjovsky, Léon Bottou, Towards Principled Methods for Training Generative Adversarial Network
Q:所以为什么discriminator的loss都几乎为0呢?
我们再拿出discriminator的loss:loss为0说明两个分布的JSD最大,即分布几乎不一样,或者说两个分布的overlap(重叠)太小。
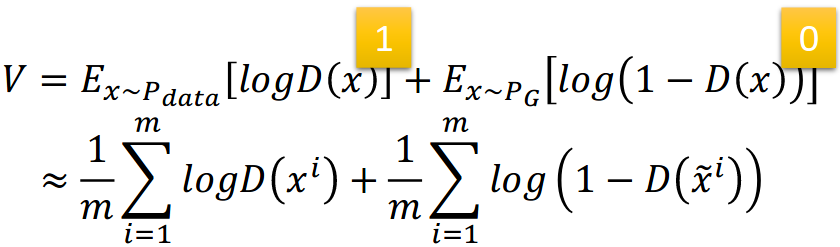
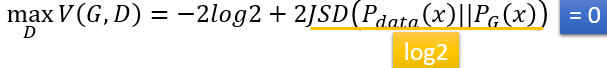
- 我们没法得到所有样本的积分,只能去sample。可能discriminator太强大硬是将两个分布的不同给分开,即将正负样本分开。那么discriminator的loss就去近于0了。解决方法:weaken your discriminator,使得它无法过拟合,无法太强。但问题是不知道调整discriminator的度。
- 数据问题。image是高维的数据。Both Pdata和PG are low-dim manifold in high-dim space ,通常它们没有任何overlap。这两个分布开始重叠很小,或者毫无交集,那么好的优化应该使得两个分布越来越相似,或者两者的分布overlap越来越大。但是如下图,有个问题是在变好的过程中,损失没有变化,当重叠的时候损失突然变成0。那么损失没有渐变就没有动力去学习相似的分布。好的方法例如是WGAN。当然还有比较一般的方法:例如加些noise:可以在discriminator的输入加些noise,可以给discriminator的label加些noise。
下图加了一些noise后就长宽了,overlap也多了,有overlap就可以算它们的JS divergence了,同时discriminator就无法得到值为0的loss了(无法硬是把两个分布完全给分开)。 那么你就可以得到一些loss的值,可以计算JS divergence了。当然实操时希望noise的值越来越小,不影响你的真正分布。
 ----add noise-->
----add noise--> ----can't classify easily-->
----can't classify easily--> 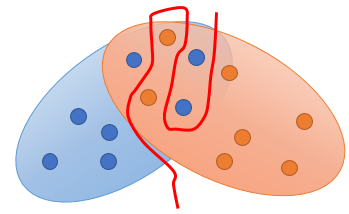
Mode Collapse
学到的分布只是真正分布的一部分,如下图:
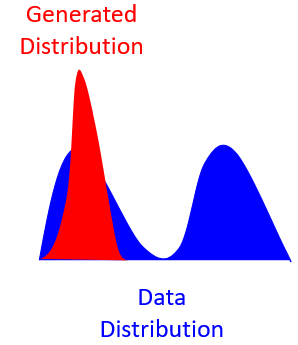
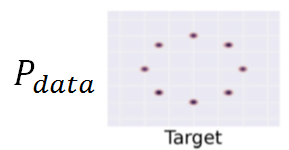
再假设上图(右)是真实的(高斯混合)分布,我们所期待generator应如下图,在training的过程中慢慢学到了真正的分布

但实操时往往会是下图:它只会产生某一个高斯。下图generator生成的分布的调整过程是不断的被discriminator发现,混不下去了,所以又跳到下一个高斯...即没办法停止。

Flaw in Optimization?
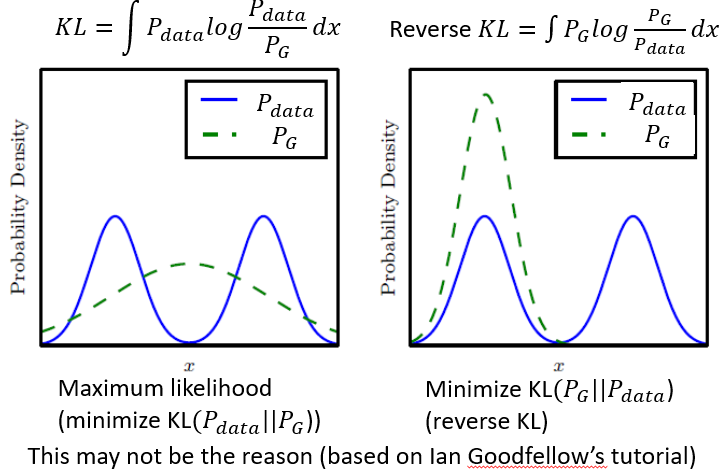
上图(左)什么时候KL divergence会产生无穷大的值?(看分子分母)即Pdata有值,而PG无值。所以上图Pdata为两个高斯分布,如果PG能产生两个高斯分布最好,但如果你的generator的capacity不够,只能产生一个高斯分布,那么generator趋向于覆盖住整个Pdata的取值范围,就算几率不一样也不一样,就只是保证Pdata有值的时候PG也一定要有。
上图(右)是reverse KL divergence。即两个分布位置相反。那什么时候产生无穷大的值呢?(看分子分母)即PG 有值,而Pdata无值。就是说PG 产生的某一张image不像是真正的image,那么此时就会产生无穷大的reverse KL divergence。那就会造成PG 的分布非常保守。它宁可产生无数张一样的realistic的iamge,也不愿意产生一些不一样的image。所以上图(右)PG如果只能有一个distribution,那它 只会固守住某一个distribution。
各种GAN:
Conditional GAN
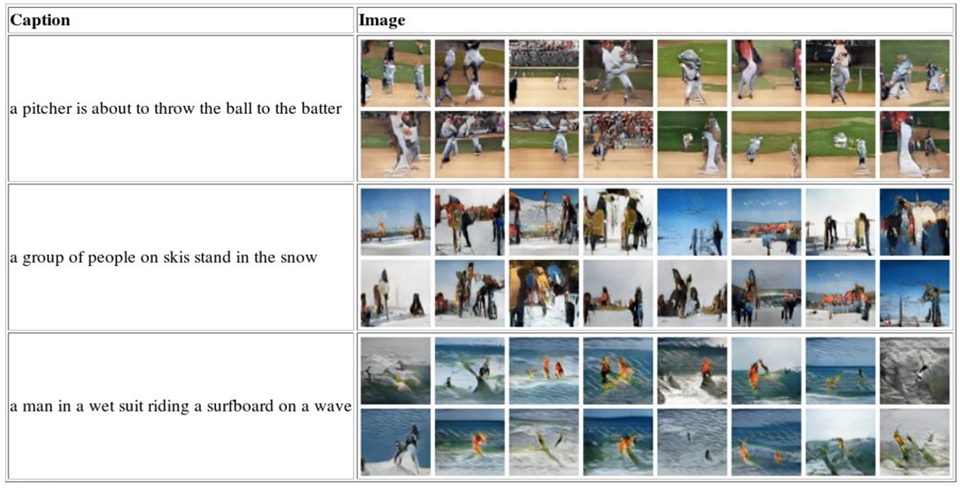
考虑下图的任务:Test to Image: “Generative Adversarial Text-to-Image Synthesis”, ICML 2016

每次输入一个文本c,输出一张图像。但是问题是给定一个文本’train‘,如下图:火车可能是正面而来的,也可能是侧面的,这是两种不同的情况,但是如果当作一种情形,就会学到它们的平均,即一张模糊的图片

所以要改进模型,从先验分布里sample一些样本z,再加上c一起扔到NN里来generate image,这些生成的图片也会是一种distribution: 真正实操时要学习慢慢忽略先验分布z。
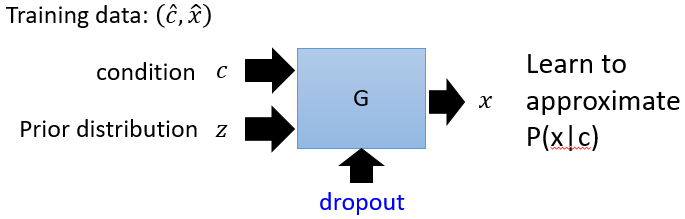
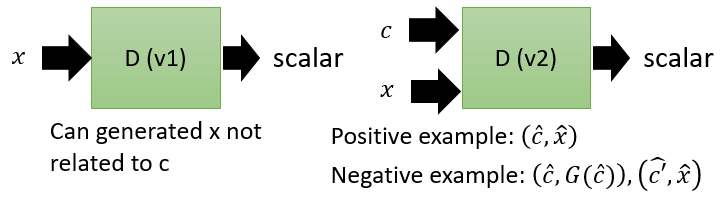
说完了Conditional GAN的generator,Conditional GAN里有两种版本的discriminator:下图(左)输入一张图片x,输出一个scalar实值来判定它是否是realistic,和文本c无关。下图(右)就更高级一点,给判别器的正样本:正确的文本描述和真实的图片,负样本(有两种):真实的描述+描述经过generator的产生的图片、真实的图片+图文无关的描述。而generator就希望负样本:真实的描述+描述经过generator的产生的图片 可以被划分为正样本。
论文实现结果:
注:GAN公式推导存在的一个问题:
目标函数本来应是这样的:
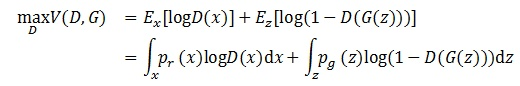 7)
7)
而上文中直接给出的目标函数是:
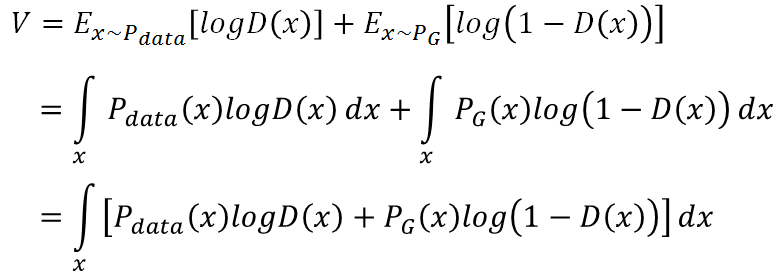 8)
8)
7)式是最初的目标函数,z是生成器的输入啊,即最初的噪声分布。因为7)式的两部分的积分区域不同,计算困难,所以应将两个积分区域统一。们将生成图像G(z)的分布与真实图像x的分布做一个投射,只要判别式能够在真实数据出现的地方保证判别正确最大化即可,于是公式就变成了:
 9)
9)
这时9)式即为8)中的结果。
在 GAN 原论文中,有一个思想和其它很多方法都不同,即生成器 G 不需要满足可逆条件。Scott Rome 认为这一点非常重要,因为实践中 G 就是不可逆的。而很多证明笔记都忽略了这一点,他们在证明时错误地使用了积分换元公式,而积分换元却又恰好基于 G 的可逆条件。Scott 认为证明只能基于以下等式的成立性:
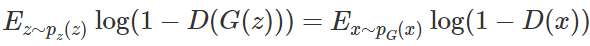
该等式来源于测度论中的 Radon-Nikodym 定理,它展示在原论文的命题 1 中,并且表达为以下等式:

我们看到这里使用了积分换元公式,但进行积分换元就必须计算 G^(-1),而 G 的逆却并没有假定为存在。并且在神经网络的实践中,它也并不存在。可能这个方法在机器学习和统计学文献中太常见了,因此我们忽略了它。
附:
机器之心GitHub项目:GAN完整理论推导与实现,Perfect!
深度学习的三大生成模型:VAE、GAN、GAN
深入浅出 GAN·原理篇文字版(完整)|干货
博客:
Generative Adversarial Nets in TensorFlow (Part I)
An introduction to Generative Adversarial Networks (with code in TensorFlow)
Generative Adversarial Nets(原生GAN学习)的更多相关文章
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Generative Adversarial Nets[Improved GAN]
0.背景 Tim Salimans等人认为之前的GANs虽然可以生成很好的样本,然而训练GAN本质是找到一个基于连续的,高维参数空间上的非凸游戏上的纳什平衡.然而不幸的是,寻找纳什平衡是一个十分困难的 ...
- 一文读懂对抗生成学习(Generative Adversarial Nets)[GAN]
一文读懂对抗生成学习(Generative Adversarial Nets)[GAN] 0x00 推荐论文 https://arxiv.org/pdf/1406.2661.pdf 0x01什么是ga ...
- Generative Adversarial Nets(GAN Tensorflow)
Generative Adversarial Nets(简称GAN)是一种非常流行的神经网络. 它最初是由Ian Goodfellow等人在NIPS 2014论文中介绍的. 这篇论文引发了很多关于神经 ...
- Generative Adversarial Nets (GAN)
目录 目标 框架 理论 数值实验 代码 Generative Adversarial Nets 这篇文章,引领了对抗学习的思想,更加可贵的是其中的理论证明,证明很少却直击要害. 目标 GAN,译名生成 ...
- GAN(Generative Adversarial Nets)的发展
GAN(Generative Adversarial Nets),产生式对抗网络 存在问题: 1.无法表示数据分布 2.速度慢 3.resolution太小,大了无语义信息 4.无reference ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- Generative Adversarial Nets[BEGAN]
本文来自<BEGAN: Boundary Equilibrium Generative Adversarial Networks>,时间线为2017年3月.是google的工作. 作者提出 ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
随机推荐
- MT【66]寻找对称中心
设函数$f(x)=2x-cosx,{a_n}$是公差为$\frac{\pi}{8}$的等差数列,$f(a_1)+f(a_2)+f(a_3)+f(a_4)+f(a_5)=5\pi$,则 $[f(a_3) ...
- BZOJ 400题纪念
应该是最后一次纪念了吧! 想当年,我可是发过"BZOJ 10题纪念"的人--那时候(一年前?)的自己真的好菜啊,只能说掌握了c++的基础语法的样子.当时觉得省选级别的BZOJ题是世 ...
- 青蛙跳台阶(C、Python)
C语言: /* ----------------------------------- 当n = 1, 只有1中跳法:当n = 2时,有两种跳法:当n = 3 时,有3种跳法:当n = 4时,有5种跳 ...
- Bean和Spirng模块
容纳Bean 在Spring中,应用对象生存于Spring容器中,如图所示,Spring容器可以创建.装载.配置这些Bean,并且可以管理它们的生命周期. Spring的容器实现 Bean工厂(org ...
- service的生命周期
Managing the Lifecycle of a Service service的生命周期,从它被创建开始,到它被销毁为止,可以有两条不同的路径: A started service 被开启的s ...
- qbxt的题:找一个三元环
有向图中找一个三元环 题意: 考虑 N 个人玩一个游戏, 任意两个人之间进行一场游戏 (共 N*(N-1)/2 场),且每场一定能分出胜负.现在,你需要在其中找到三个人构成的这样的局面:A战胜B,B战 ...
- babel的使用及babel与gulp结合工作流
Babel 通过语法转换器支持最新版本的 JavaScript . 它有非常多的插件,这些插件能够允许我们立刻使用新语法,无需等待浏览器支持. 那我们怎么使用babel呢? 首先我们来了解babel基 ...
- python之配置日志的几种方式
作为开发者,我们可以通过以下3种方式来配置logging: 1)使用Python代码显式的创建loggers, handlers和formatters并分别调用它们的配置函数: 2)创建一个日志配置文 ...
- CentOS/Linux下设置IP地址
CentOS/Linux下设置IP地址 1:临时修改:1.1:修改IP地址# ifconfig eth0 192.168.100.100 1.2:修改网关地址# route add default g ...
- banner轮播无缝滚动 jq代码
HTML: <div class="box"> <ul> <li>11111</li> <li>22222</li ...