MapReduce实现与自定义词典文件基于hanLP的中文分词详解
前言:
文本分类任务的第1步,就是对语料进行分词。在单机模式下,可以选择python jieba分词,使用起来较方便。但是如果希望在Hadoop集群上通过mapreduce程序来进行分词,则hanLP更加胜任。
一、使用介绍
hanLP是一个用java语言开发的分词工具, 官网是 http://hanlp.com/ 。 hanLP创建者提供了两种使用方式,一种是portable简化版本,内置了数据包以及词典文件,可通过maven来管理依赖,只要在创建的 maven 工程中加入以下依赖,即可轻松使用(强烈建议大家优先采用这种方法)。

具体操作方法如图示,在pom.xml中,加入上述依赖信息,笔者使用的IDEA编辑器就会自动开始解析依赖关系,并导入左下角的hanlp jar包。
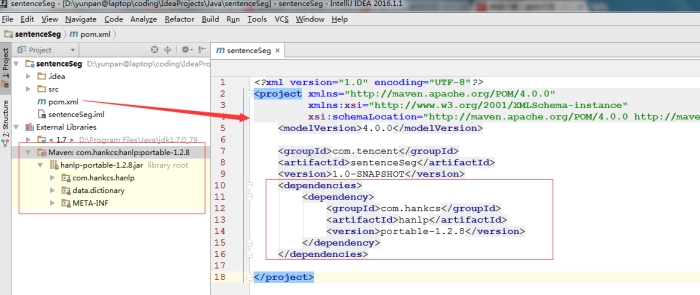
第二种方法需要自己下载data数据文件,并通过一个配置文件hanlp.properties来管理各种依赖信息,其中最重要的是要人为指定data目录的家目录。(不建议大家一上来就使用这种方法,因为真心繁琐!)
二、通过第一种方法,建立maven工程,编写mapreduce完整程序如下(亲测运行良好):

三、添加自定义词典文件 & 单机模式
有时候我们希望根据自己业务领域的一些专有词汇进行分词,而这些词汇可能并不包含在官方jar包自带的分词词典中,故而我们希望提供自己的词典文件。首先,我们定义一个测试的句子,并用系统默认的词典进行分词,可看到效果如下图所示:
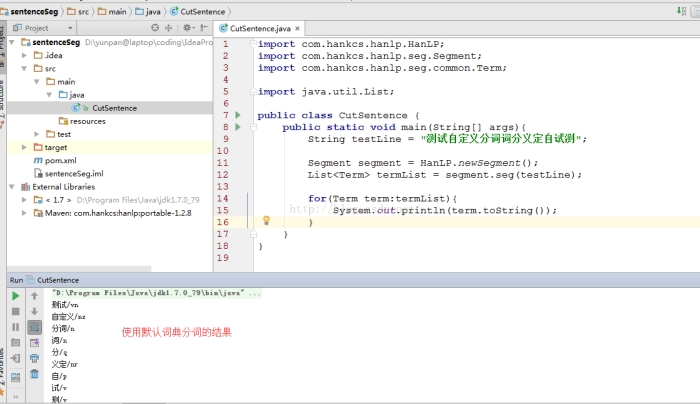
假设在我们的专业领域中,“词分”,“自试” 都是专业术语,那么使用默认词典就无法将这些目标词分出来了。这时就要研究如何指定自定义的词典,并在代码中进行调用。这时有2种方法。
1. 在代码中,通过CustomDictionary.add();来添加自己的词汇,如下图所示, 可以看到这次分词的结果中,已经能将“词分”,“自试” 单独分出来了。
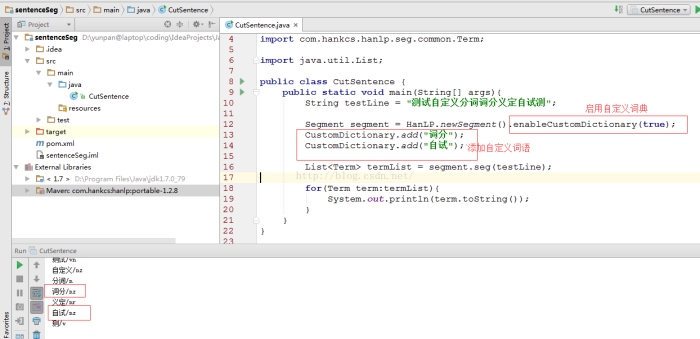
假如说我们想添加的词汇较多呢,通过上面的方法,一个一个 add, 未勉显得不够优雅,这时我们就希望通过一个词典文件的形式来添加自定义词汇。在官方网站上,提供了如下一种方法。该方法要求我们单独下载一个data目录,以及定义一个配置文件。下面我们就来看下如何操作。

首先,下载好上面的hanlp.jar后,在java工程师导入该包。同时在src目录下创建一个hanlp.properties配置文件,内容直接复制官网上的内容,但是注意修改两个地方。
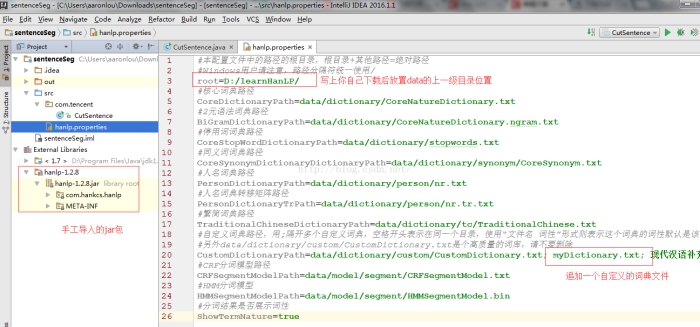
其中myDictionary.txt是我们自己创建的一个词典文件,其内容为:

这时候,再运行方法1同样的代码,可看到如下结果中,也将“词分”、“自试” 分了出来。
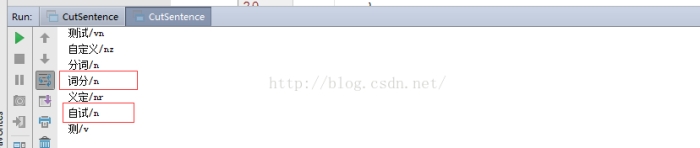
注意,如果你不想显示/n /nr这样的记性,也可以将上述配置文件中最后一行
ShowTermNature=true
修改为
ShowTermNature=false
注意,这时候,运行成功的话,会在词典目录下生成一个词典缓存文件

四、自定义词典文件 & mapreduce提交
写到这里,想必细心的人已经想到了,当我们希望将编辑好的mapreduce程序打成jar包,提交到集群上运行时,上面这种通过配置文件指定data目录的方法还可行吗? 反正我是没有搞定。理论上,要么我们需要把data上传到集群上每个节点,要么把data直接打到jar包中。但是,这两种方法本人尝试都没有成功。最终,跟一位同事相互讨论后,借鉴了对方的方法。即我们猜想,portable版本自带了data数据,且不需要额外指定配置文件。而我们现在想做的就是添加了一些自定义词汇,那么,是否我们将其中的词典缓存文件替换掉,就行了呢?动手试下才知道嘛。这次不通过maven来管理依赖,直接下载portable版本的jar包,然后打开压缩文件,删除data\dictionary\custom目录下的CustomDictionary.txt.bin文件,然后将上一步运行成功的CustomDictionary.txt.bin粘贴进去! 将工程打成jar包,再通过命令行进入其所在目录,执行java -jar 包名, 发现可以执行成功。然后,为了测试是否对这个绝对路径有依赖,我们故意将该jar包剪切到 d:\ , 再执行一下,发现同样是成功的。

具体到提交到集群上运行,我们就不赘述了。这个方法虽然土一些,但至少是可用的。
文章转载自 a_step_further 的博客(有小幅改遍)
MapReduce实现与自定义词典文件基于hanLP的中文分词详解的更多相关文章
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- HanLP 关键词提取算法分析详解
HanLP 关键词提取算法分析详解 l 参考论文:<TextRank: Bringing Order into Texts> l TextRank算法提取关键词的Java实现 l Text ...
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- 把java文件打包成.jar (jar命令详解)
把java文件打包成.jar (jar命令详解) 先打开命令提示符(win2000或在运行框里执行cmd命令,win98为DOS提示符),输入jar Chelp,然后回车(如果你盘上已经有了jdk1. ...
- 基于STM32的uCOS-II移植详解
百度:基于STM32的uCOS-II移植详解 源:基于STM32的uCOS-II移植详解
- 分词工具Hanlp基于感知机的中文分词框架
结构化感知机标注框架是一套利用感知机做序列标注任务,并且应用到中文分词.词性标注与命名实体识别这三个问题的完整在线学习框架,该框架利用1个算法解决3个问题,时自治同意的系统,同时三个任务顺序渐进,构 ...
- 基于hanlp的es分词插件
摘要:elasticsearch是使用比较广泛的分布式搜索引擎,es提供了一个的单字分词工具,还有一个分词插件ik使用比较广泛,hanlp是一个自然语言处理包,能更好的根据上下文的语义,人名,地名,组 ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- 基于CRF的中文分词
http://biancheng.dnbcw.info/java/341268.html CRF简介 Conditional Random Field:条件随机场,一种机器学习技术(模型) CRF由J ...
随机推荐
- kbmMW SmartService控制返回类型
- POJ 1287 Networking(最小生成树裸题有重边)
Description You are assigned to design network connections between certain points in a wide area. Yo ...
- 【Python】requests.post请求注册实例
#encoding=utf-8 import requests import json import time import random import multiprocessing from mu ...
- tomcat 配置成服务
1.下载Zip版Tomcat;选择:32-bit Windows zip(pgp,md5)下载解压文件到指定目录,如:D:/ProgramFiles/Tomcat6 进入D:/ProgramFiles ...
- React-Native子组件修改父组件的几种方式,兄弟组件状态修改(转载)
子组件修改父组件的状态,在开发中非常常见,下面列举了几种方式.DeviceEventEmitter可以跨组件,跨页面进行数据传递,还有一些状态的修改.http://www.jianshu.com/p/ ...
- insserv: warning: script 'busybox-httpd' missing LSB tags and overrides
/********************************************************************************* * insserv: warnin ...
- vim 删除
shift + $ :光标往后 shift + ^ :光标往前 shift + D 删除当前光标直到末尾
- sticky footer 和 flex布局的原理
Sticky footers设计是最古老和最常见的效果之一,大多数人都曾经经历过.它可以概括如下:如果页面内容不够长的时候,页脚块粘贴在视窗底部:如果内容足够长时,页脚块会被内容向下推送. 一.使用f ...
- BZOJ-5244 最大真因数(min25筛)
题意:一个数的真因数指不包括其本身的所有因数,给定L,R,求这个区间的所有数的最大真因数之和. 思路:min25筛可以求出所有最小因子为p的数的个数,有可以求出最小因子为p的所有数之和. 那么此题就是 ...
- 牛客国庆集训派对Day4 I-连通块计数(思维,组合数学)
链接:https://www.nowcoder.com/acm/contest/204/I 来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 1048576K,其他语言20 ...