中文多分类 BERT
直接把自己的工作文档导入的,由于是在外企工作,所以都是英文写的
Steps:
- git clone https://github.com/google-research/bert
- prepare data, download pre-trained models
- modify code in run_classifier.py
- add a new processor

- add the processor in main function

Train and predict
- train
python run_classifier.py \
--task_name=multiclass \
--do_train=true \
--do_eval=true \
--data_dir=/home/wxl/bertProject/bertTextClassification/data\
--vocab_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=/home/wxl/bertProject/chinese_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=16 \
--learning_rate=2e-5 \
--num_train_epochs=100.0 \
--output_dir=/home/wxl/bertProject/bertTextClassification/outputThree/
you would get the following result if success:
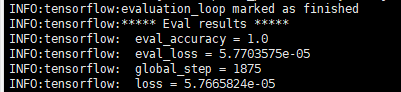
- predict
python run_classifier.py \
--task_name=multiclass \
--do_predict=true \
--data_dir=/home/wxl/bertProject/bertTextClassification/data\
--vocab_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=/home/wxl/bertProject/bertTextClassification/outputThreeV1 \
--max_seq_length=128 \
--output_dir=/home/wxl/bertProject/bertTextClassification/mulitiPredictThreeV1/
中文多分类 BERT的更多相关文章
- colab上基于tensorflow2.0的BERT中文多分类
bert模型在tensorflow1.x版本时,也是先发布的命令行版本,随后又发布了bert-tensorflow包,本质上就是把相关bert实现封装起来了. tensorflow2.0刚刚在2019 ...
- 利用CNN进行中文文本分类(数据集是复旦中文语料)
利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) 利用RNN进行中文文本分类(数据集是复旦中文语料) 上一节我们利用了RNN(GRU)对中文文本进行了分类,本节我们将继续使用 ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 利用RNN进行中文文本分类(数据集是复旦中文语料)
利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) 1.训练词向量 数据预处理参考利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) ,现在我们有了分词 ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- CNN在中文文本分类的应用
深度学习近一段时间以来在图像处理和NLP任务上都取得了不俗的成绩.通常,图像处理的任务是借助CNN来完成的,其特有的卷积.池化结构能够提取图像中各种不同程度的纹理.结构,并最终结合全连接网络实现信息的 ...
- hugging face-基于pytorch-bert的中文文本分类
1.安装hugging face的transformers pip install transformers 2.下载相关文件 字表: wget http://52.216.242.246/model ...
随机推荐
- 跟我一起使用electron搭建一个文件浏览器应用吧(三)
第二篇博客中我们可以看到我们构建的桌面应用会显示我们的文件及文件夹. In the second blog, we can see that the desktop application we bu ...
- UML简单熟悉
+ :代表public - :代表private # :代表protected 实现,继承关系:implements,extends 关联关系:使一个类知道另一个类的属性和方法 每一个Driver类 ...
- centos7 修改 PATH环境变量(注意,不是添加!!!TMD)
起因都是,参照阿里云的Java环境配置,MMP~ 现在我们分析一下这几句话.JAVA_HOME和JRE_HOME都是没问题的 CLASSPATH:注意 [ lib$:JRE ]这部分,Linux环 ...
- ruby pluck用法,可以快速从数据库获取 对象的 指定字段的集合数组
可以快速从数据库获取 对象的 指定字段的集合数组 比如有一个users表,要等到user的id数组: select id from users where age > 20; 要实现在如上sql ...
- POJ - 1836 Alignment (动态规划)
https://vjudge.net/problem/POJ-1836 题意 求最少删除的数,使序列中任意一个位置的数的某一边都是递减的. 分析 任意一个位置的数的某一边都是递减的,就是说对于数h[i ...
- hashmap和hashtable异同
(一)继承的历史不同 Hashtable是继承自Dictionary类的,而HashMap则是Java 1.2引进的Map接口的一个实现. public class Hashtable extends ...
- js_倒计时去执行函数或则跳转页面
js_倒计时去执行函数或则跳转页面: var wait = 5; $(document).ready(function () { returnPage(); }); function returnPa ...
- JavaScript中的number跟string
遇到问题困扰很久,因为这看起来木有问题,都是对的啊,殊不知是因为参数需要一个数字类型,但是数据却悄悄变成了字符类型.在群里求救无果最后自己找到了原因. 为什么我箭头里放数字可以正常显示,放temp[i ...
- 〖C语言学习笔记 〗(一) HelloWorld
前言 本文为c基础入门学习笔记 正文 HelloWorld #include <stdio.h> //标准输出流 int main() //每种语言都有一个执行入口,main方法就是其一 ...
- 表格重新加载 where 携带上次值问题
表格重载两种方式: 方式一: tableIns.reload(options) 注意这种方式的重载是不会携带上次数据加载时的where值 //使用 第一次渲染返回的对象 var table ...