019 mapreduce的核心--shuffle理解,以及在shuffle中的优化
关于shuffle的过程图。

一:概述shuffle
Shuffle是mapreduce的核心,链接map与reduce的中间过程。
Mapp负责过滤分发,而reduce则是归并整理,从mapp输出到reduce的输入的这个过程称为shuffle过程。
二:map端的shuffle
1.map结果的输出
map的处理结果首先存放在一个环形的缓冲区。
这个缓冲区的内存是100M,是map存放结果的地方。如果数据量较大,超过了一定的量(默认80M),将会发生溢写过程。
在mapred-site.xml中设置内存的大小
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
在mapred-site.xml中设置内存溢写的阈值
<property>
<name>mapreduce.task.io.sort.spill.percent</name>
<value>0.8</value>
</property>

2.溢写过程(这个过程是一个阶段,不是一个简单的写的过程)
溢写是系统在后台单独开一个线程去操办。
溢写过程包括:分区partitioner,排序sort,溢写spill to disk,合并merge。
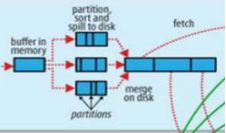
3.分区
分区分的是80%的内存。
因为reduce可能有不同的任务,所以会对80M的内存进行分区,将map的输出结果放入的对应的reduce分区中。
4.排序
默认是按照key排序。
当分区完成之后,对每一个分区的数据进行排序。
排序发生在数据到达80M的时候。(2017.12.24,刚刚想了一下,应该是这个时候)
5.溢写
排序之后,将内存的数据写入硬盘。留出内存方便map的新的输出结果。
6.合并
如果是第一次写入硬盘则不需要考虑合并问题,但是在大数据的情况下,前面已经存在大量的spill文件的时候,这时候需要将它们进行合并。
将各个分区合并之后,对每一个分区的数据再进行一次排序。(2017.12.24,这个比较重要,注意点是各个分区合并)
使用归并的方式进行合并,归并算法。
实现comparator比较器,进行比较。
形成一个文件。
三:reduce端的shuffle
1.步骤
对于reduce端的shuffle,和map端的shuffle步骤相同。但是有一个特别的步骤,分组。
2.复制
当reduce开启任务后,不断的在各个节点复制需要的数据。
3.合并(内含排序)
复制数据的时候,把可以存放进内存的就把数据存放在内存中,当达到一定的时候,启动merge,将数据写进硬盘。
如果map数据大于内存需要存放的限制,直接写入硬盘,当达到一定的数量后将其合并为一个文件。
这时候,reduce开启任务需要的数据在内存中和在硬盘中,最终形成一个全局文件。
4.分组
《hadoop,1》
《hadoop,1》
《yarn,1》
《hadoop,1》
《hdfs,1》
《yarn,1》
将相同的key放在一起,使用comparable完成比较。
结果为:
《hadoop,list(1,1,1)》
《yarn,list(1,1)》
《hdfs,list(1)》
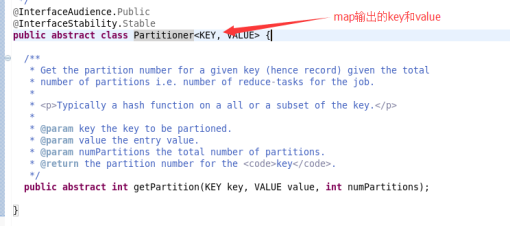
四:关于Comparator的理解
不管是排序还是分组,都需要自定义排序器comparable
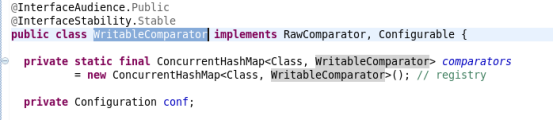
Comparator类继承WritableComparator

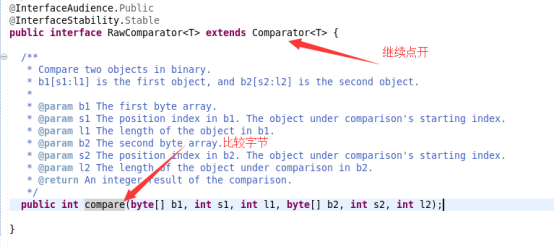
而WritableComparator完成接口RawComparator
在RawComparator中:

五:shuffle处的优化
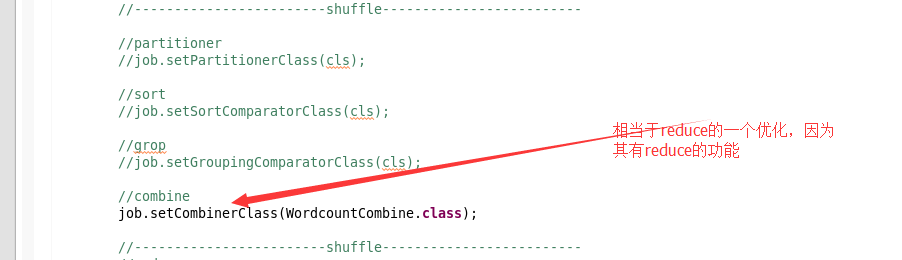
1.combine的优化
这是map段的reduce。
好处就是提前进行一次reduce,注意点是每个map进行一次reduce之后,数据量合并变小。
问题:是否还需要reduce?
回答:这个是map段的reduce,正真的reduce是许多map的一个汇总,所以是需要的。(2017.12.24,想法不知道对不对,希望以后进行仔细研究)
2.下面列举需要修改的程序

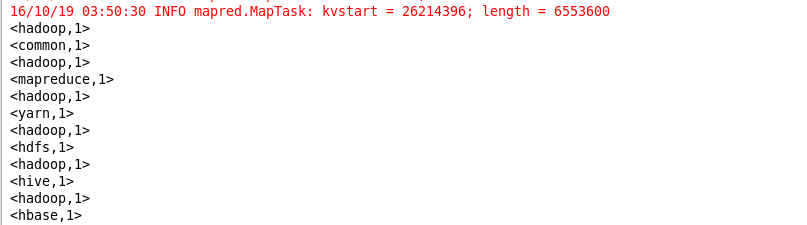
3.输出结果
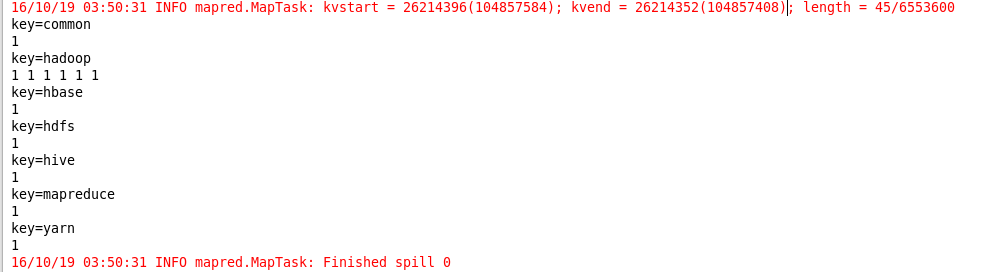
4.关于压缩方面的优化
这个优化也属于map段的一个优化部分。
但是优化的方式是修改配置项。
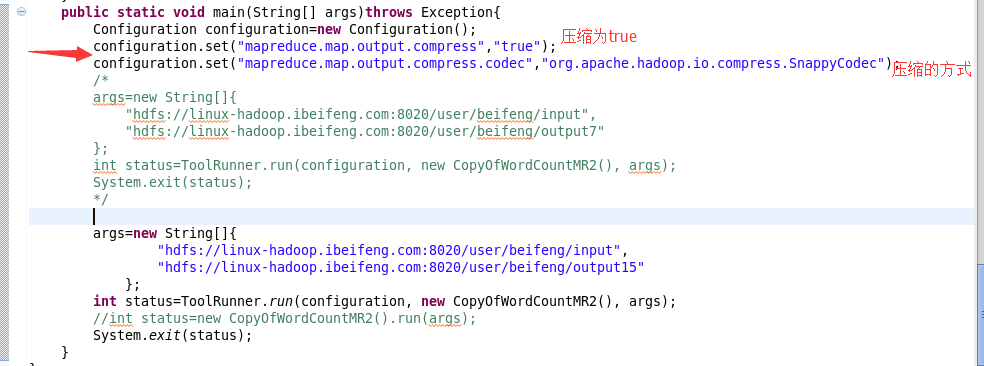
注意点:
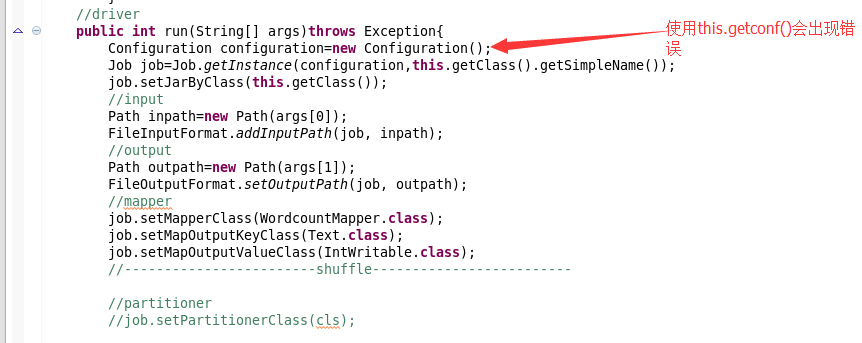
会出现的问题:

六:属于分区的一个思路
shuffle中程序:

说明:
这个根据reduce实际需求决定。
根据测试决定合理的reduce数目。
七:shuffle最终总结、
包括优化部分,可以将shuffle分为五个部分。
map端:分区
排序
合并combine
压缩
reduce端:分组
八:完整的程序
package com.senior.bigdata; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class OptimizeOfWordCountMR extends Configured implements Tool{
//Mapper
public static class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
private Text mapoutputkey=new Text();
private static final IntWritable mapoutputvalue=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
String lineValue=value.toString();
String[] strs=lineValue.split(" ");
for(String str:strs){
mapoutputkey.set(str);
context.write(mapoutputkey, mapoutputvalue);
// System.out.println(mapoutputkey+"<---->"+mapoutputvalue);
}
} } //combiner
public static class WordCountCombiner extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable outputvalue=new IntWritable();
@Override
protected void reduce(Text text, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {
int sum=0;
// System.out.println("key="+text);
for(IntWritable value:values){
sum+=value.get();
// System.out.print(value.get());
}
// System.out.println();
outputvalue.set(sum);
context.write(text, outputvalue);
} } //Reducer
public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable outputvalue=new IntWritable();
@Override
protected void reduce(Text text, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {
int sum=0;
// System.out.println("key==="+text);
for(IntWritable value:values){
// System.out.print(value.get());
sum+=value.get();
}
// System.out.println();
outputvalue.set(sum);
context.write(text, outputvalue);
} } //Driver
public int run(String[] args)throws Exception{
Configuration conf=this.getConf();
Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(OptimizeOfWordCountMR.class);
//input
Path inpath=new Path(args[0]);
FileInputFormat.addInputPath(job, inpath); //output
Path outpath=new Path(args[1]);
FileOutputFormat.setOutputPath(job, outpath); //map
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //shuffle
job.setCombinerClass(WordCountCombiner.class); //combiner //reduce
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //submit
boolean isSucess=job.waitForCompletion(true);
return isSucess?0:1;
} //main
public static void main(String[] args)throws Exception{
Configuration conf=new Configuration();
//compress
conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
args=new String[]{
"hdfs://linux-hadoop01.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/input",
"hdfs://linux-hadoop01.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/output5"
};
int status=ToolRunner.run(new OptimizeOfWordCountMR(), args);
System.exit(status);
} }
019 mapreduce的核心--shuffle理解,以及在shuffle中的优化的更多相关文章
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- MapReduce的核心编程思想
1.MapReduce的核心编程思想 2.yarn集群工作机制 3.maptask并行度与决定机制 4.maptask工作机制 5.MapReduce整体流程 6.shuffle机制 7.yarn架构
- MapReduce的核心运行机制
MapReduce的核心运行机制概述: 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 ...
- MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- Node.js面试题:侧重后端应用与对Node核心的理解
Node是搞后端的,不应该被被归为前端,更不应该用前端的观点去理解,去面试node开发人员.所以这份面试题大全,更侧重后端应用与对Node核心的理解. node开发技能图解 node 事件循环机制 起 ...
- node.js面试题大全-侧重后端应用与对Node核心的理解
Node是搞后端的,不应该被被归为前端,更不应该用前端的观点去理解,去面试node开发人员.所以这份面试题大全,更侧重后端应用与对Node核心的理解. github地址: https://github ...
- MR的shuffle和Spark的shuffle之间的区别
mr的shuffle mapShuffle 数据存到hdfs中是以块进行存储的,每一个块对应一个分片,maptask就是从分片中获取数据的 在某个节点上启动了map Task,map Task读取是通 ...
- 理解与应用css中的display属性
理解与应用css中的display属性 display属性是我们在前端开发中常常使用的一个属性,其中,最常见的有: none block inline inline-block inherit 下面, ...
- 理解和使用 JavaScript 中的回调函数
理解和使用 JavaScript 中的回调函数 标签: 回调函数指针js 2014-11-25 01:20 11506人阅读 评论(4) 收藏 举报 分类: JavaScript(4) 目录( ...
随机推荐
- POJ3635 Full Tank?【Dijkstra+DP】
题意: n个城市之间有m条双向路.每条路要耗费一定的油量.每个城市的油价是固定并且已经给出的.有q个询问,表示从城市s走到e,油箱的容量为c,求最便宜的方案. 思路: 用Dijkstra+Heap即可 ...
- CSS font-family 各名称一览表
参考链接:https://blog.csdn.net/cddcj/article/details/70739481
- 消息队列介绍和SpringBoot2.x整合RockketMQ、ActiveMQ 9节课
1.JMS介绍和使用场景及基础编程模型 简介:讲解什么是小写队列,JMS的基础知识和使用场景 1.什么是JMS: Java消息服务(Java Message Service),Java ...
- android 面试题(一)
1.Android中真实宽高,getWidth和getMeasuredWidth的区别:哪个计算的是真实的宽? getWidth():得到的是View在父Layout中布局好后的宽度值,如果没有父布局 ...
- k64 datasheet学习笔记3---Chip Configuration之System modules
1.前言 本文主要介绍芯片配置的系统模块的内容 2.SIM配置 TODO 3.SMC配置 TODO 4.PMC配置 TODO 5.LOW-LEAKAGE WAKEUP单元配置 TODO 6.MCM配置 ...
- C语言函数调用栈(二)
5 函数调用约定 创建一个栈帧的最重要步骤是主调函数如何向栈中传递函数参数.主调函数必须精确存储这些参数,以便被调函数能够访问到它们.函数通过选择特定的调用约定,来表明其希望以特定方式接收参数.此外, ...
- ES系列二、CentOS7安装ES head6.3.1
1.Head插件简介 ElasticSearch-head是一个H5编写的ElasticSearch集群操作和管理工具,可以对集群进行傻瓜式操作. 显示集群的拓扑,并且能够执行索引和节点级别操作 搜索 ...
- kafka系列九、kafka事务原理、事务API和使用场景
一.事务场景 最简单的需求是producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见 . producer可能会给多个topic,多个partition发消息,这些 ...
- 【转】snprintf()函数使用方法
众所周知,sprintf不能检查目标字符串的长度,可能造成众多安全问题,所以都会推荐使用snprintf. 注:sprintf()函数:int sprintf( char *buffer, const ...
- eclipse自定义工具栏
设置:1.Window2.Customize Perspective说明:Tool Bar Visibility定义菜单栏,Shortcuts定义右键new菜单