自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下!
TextRank是在Google的PageRank算法启发下,针对文本里的句子设计的权重算法,目标是自动摘要。它利用投票的原理,让每一个单词给它的邻居(术语称窗口)投赞成票,票的权重取决于自己的票数。这是一个“先有鸡还是先有蛋”的悖论,PageRank采用矩阵迭代收敛的方式解决了这个悖论。本博文通过hanlp关键词提取的一个Demo,并通过图解的方式来讲解TextRank的算法。
1//长句子
2 String content = "程序员(英文Programmer)是从事程序开发、维护的专业人员。" +
3 "一般将程序员分为程序设计人员和程序编码人员," +
4 "但两者的界限并不非常清楚,特别是在中国。" +
5 "软件从业人员分为初级程序员、高级程序员、系统" +
6 "分析员和项目经理四大类。";
最后提取的关键词是:[程序员, 程序, 分为, 人员, 软件]
下面来分析为什么会提取出这5个关键词
第一步:分词
把content 通过一个的分词算法进行分词,这里采用的是Viterbi算法也就是HMM算法。分词后(当然首先应把停用词、标点、副词之类的去除)的结果是:
[程序员, 英文, Programmer, 从事, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 并不, 非常, 清楚, 特别是在, 中国, 软件, 从业人员, 分为, 程序员, 高级, 程序员, 系统分析员, 项目经理, 四大]
第二步:构造窗口
hanlp的实现代码如下:
Map<String, Set<String>> words = new TreeMap<String, Set<String>>();
Queue<String> que = new LinkedList<String>();
for (String w : wordList)
{
if (!words.containsKey(w))
{
words.put(w, new TreeSet<String>());
}
// 复杂度O(n-1)
if (que.size() >= 5)
{
que.poll();
}
for (String qWord : que)
{
if (w.equals(qWord))
{
continue;
}
//既然是邻居,那么关系是相互的,遍历一遍即可
words.get(w).add(qWord);
words.get(qWord).add(w);
}
que.offer(w);
}
这个代码的功能是为分个词构造窗口,这个词前后各四个词就是这个词的窗口,如词分词后一个词出现了多次,像[程序员],那就是把每次出现取一次窗口,然后把各次结果合并去重,最后结果是:程序员=[Programmer, 专业, 中国, 人员, 从业人员, 从事, 分为, 四大, 开发, 程序, 系统分析员, 维护, 英文, 设计, 软件, 项目经理, 高级]。最后形成的窗口:
1 Map<String, Set<String>> words =
2
3 {Programmer=[从事, 开发, 程序, 程序员, 维护, 英文], 专业=[人员, 从事, 分为, 开发, 程序, 程序员, 维护], 中国=[从业人员, 分为, 并不, 清楚, 特别是在, 程序员, 软件, 非常], 人员=[专业, 分为, 并不, 开发, 清楚, 界限, 程序, 程序员, 维护, 编码, 设计, 非常], 从业人员=[中国, 分为, 清楚, 特别是在, 程序员, 软件, 高级], 从事=[Programmer, 专业, 开发, 程序, 程序员, 维护, 英文], 分为=[专业, 中国, 人员, 从业人员, 特别是在, 程序, 程序员, 系统分析员, 维护, 设计, 软件, 高级], 四大=[程序员, 系统分析员, 项目经理, 高级], 并不=[中国, 人员, 清楚, 特别是在, 界限, 程序, 编码, 非常], 开发=[Programmer, 专业, 人员, 从事, 程序, 程序员, 维护, 英文], 清楚=[中国, 人员, 从业人员, 并不, 特别是在, 界限, 软件, 非常], 特别是在=[中国, 从业人员, 分为, 并不, 清楚, 界限, 软件, 非常], 界限=[人员, 并不, 清楚, 特别是在, 程序, 编码, 非常], 程序=[Programmer, 专业, 人员, 从事, 分为, 并不, 开发, 界限, 程序员, 维护, 编码, 英文, 设计], 程序员=[Programmer, 专业, 中国, 人员, 从业人员, 从事, 分为, 四大, 开发, 程序, 系统分析员, 维护, 英文, 设计, 软件, 项目经理, 高级], 系统分析员=[分为, 四大, 程序员, 项目经理, 高级], 维护=[Programmer, 专业, 人员, 从事, 分为, 开发, 程序, 程序员], 编码=[人员, 并不, 界限, 程序, 设计, 非常], 英文=[Programmer, 从事, 开发, 程序, 程序员], 设计=[人员, 分为, 程序, 程序员, 编码], 软件=[中国, 从业人员, 分为, 清楚, 特别是在, 程序员, 非常, 高级], 非常=[中国, 人员, 并不, 清楚, 特别是在, 界限, 编码, 软件], 项目经理=[四大, 程序员, 系统分析员, 高级], 高级=[从业人员, 分为, 四大, 程序员, 系统分析员, 软件, 项目经理]}
第三步:迭代投票
每个词最后的投票得分由这个词的窗口进行多次迭代投票决定,迭代的结束条件就是大于最大迭代次数这里是200次,或者两轮之前某个词的权重小于某一值这里是0.001f。看下代码:
Map<String, Float> score = new HashMap<String, Float>();
//依据TF来设置初值
for (Map.Entry<String, Set<String>> entry : words.entrySet()){
score.put(entry.getKey(),sigMoid(entry.getValue().size()));
}
System.out.println(score);
for (int i = 0; i < max_iter; ++i)
{
Map<String, Float> m = new HashMap<String, Float>();
float max_diff = 0;
for (Map.Entry<String, Set<String>> entry : words.entrySet())
{
String key = entry.getKey();
Set<String> value = entry.getValue();
m.put(key, 1 - d);
for (String element : value)
{
int size = words.get(element).size();
if (key.equals(element) || size == 0) continue;
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)));
}
max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));
}
score = m;
if (max_diff <= min_diff) break;
}
System.out.println(score);
return score;
}
投票的原理拿Programmer=[从事, 开发, 程序, 程序员, 维护, 英文],这个词来说明,Programmer最后的得分是由[从事, 开发, 程序, 程序员, 维护, 英文],这6个词依次投票决定的,每个词投出去的分数是和他本身的权重相关的。
1、投票开始前每个词初始化了一个权重,score.put(entry.getKey(),sigMoid(entry.getValue().size())),这个权重是0到1之间,公式是
1 //value是每个词窗口的大小
2 public static float sigMoid(float value) {
3 return (float)(1d/(1d+Math.exp(-value)));
4 }
这个函数的公式和图像如下,因为value一定是大于0的,所以sigMod值属于(0,1)
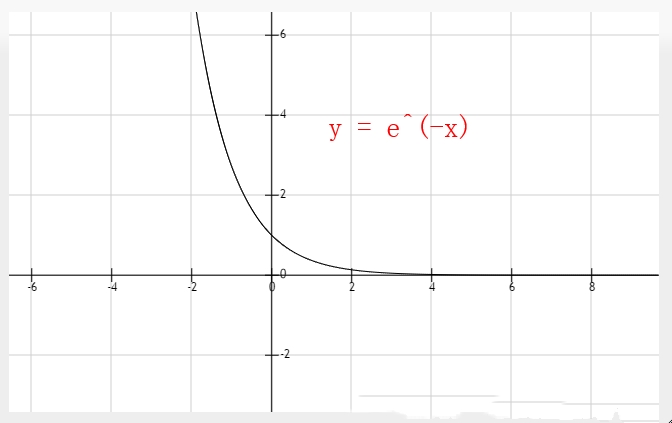
初始化后的分词是:{特别是在=0.99966466, 程序员=0.99999994, 编码=0.99752736, 四大=0.98201376, 英文=0.9933072, 非常=0.99966466, 界限=0.99908894, 系统分析员=0.9933072, 从业人员=0.99908894, 程序=0.99999774, 专业=0.99908894, 项目经理=0.98201376, 设计=0.9933072, 从事=0.99908894, Programmer=0.99752736, 软件=0.99966466, 人员=0.99999386, 清楚=0.99966466, 中国=0.99966466, 开发=0.99966466, 并不=0.99966466, 高级=0.99908894, 分为=0.99999386, 维护=0.99966466}
进行迭代投票,第一轮投票,[Programmer, 专业, 中国, 人员, 从业人员, 从事, 分为, 四大, 开发, 程序, 系统分析员, 维护, 英文, 设计, 软件, 项目经理, 高级]依给次*程序员*投票,得分如下:
[Programmer]给[程序员]投票后,[]程序员]的得分:
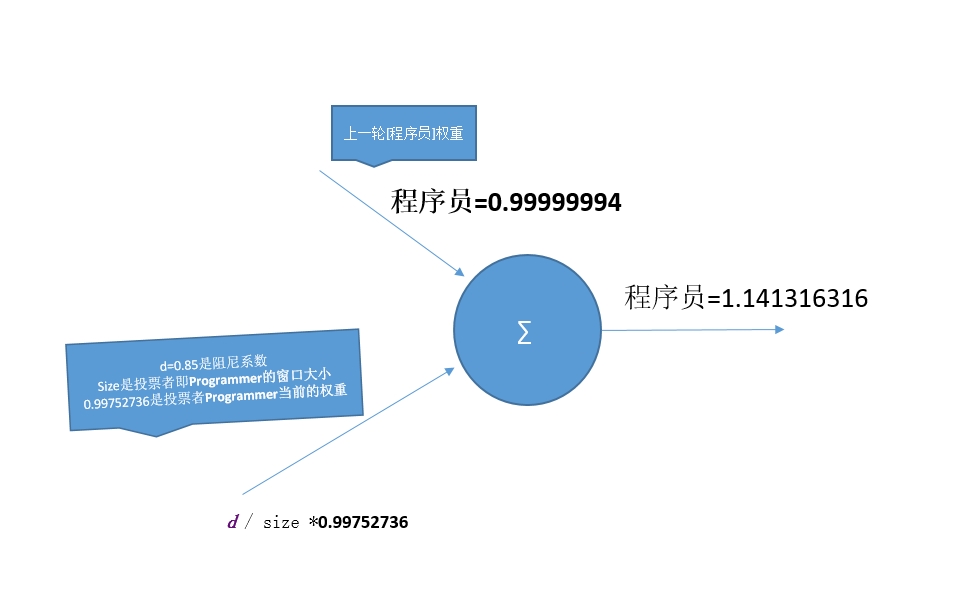
[专业]给[程序员]投票
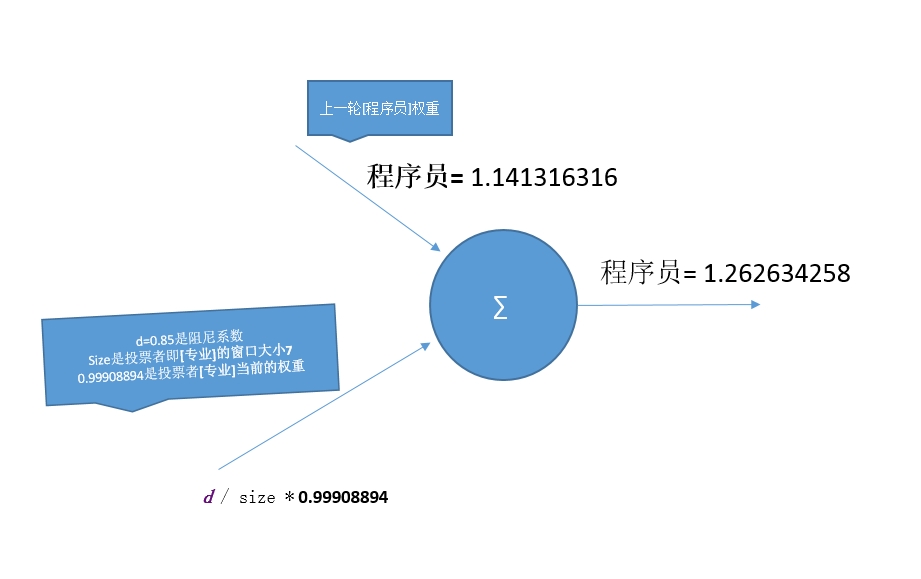
这样[Programmer, 专业, 中国, 人员, 从业人员, 从事, 分为, 四大, 开发, 程序, 系统分析员, 维护, 英文, 设计, 软件, 项目经理, 高级]依次给[程序员]投票,投完票后,再给其它的词进行投票,本轮结束后,判断是否达到最大迭代次数200或两轮之间分数差值小于0.001,如果满足则结束,否则继续进行迭代。
最后的投票得分是:{特别是在=1.0015739, 程序员=2.0620303, 编码=0.78676623, 四大=0.6312981, 英文=0.6835063, 非常=1.0018439, 界限=0.88890904, 系统分析员=0.74232763, 从业人员=0.8993066, 程序=1.554001, 专业=0.88107216, 项目经理=0.6312981, 设计=0.6702926, 从事=0.9027207, Programmer=0.7930236, 软件=1.0078223, 人员=1.4288887, 清楚=0.9998723, 中国=0.99726284, 开发=1.0065585, 并不=0.9968608, 高级=0.9673803, 分为=1.4548829, 维护=0.9946941},分数最高的关键词就是要提取的关键词
自然语言处理工具hanlp关键词提取图解TextRank算法的更多相关文章
- Python中调用自然语言处理工具HanLP手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- HanLP 关键词提取算法分析
HanLP 关键词提取算法分析 参考论文:<TextRank: Bringing Order into Texts> TextRank算法提取关键词的Java实现 TextRank算法自动 ...
- HanLP 关键词提取算法分析详解
HanLP 关键词提取算法分析详解 l 参考论文:<TextRank: Bringing Order into Texts> l TextRank算法提取关键词的Java实现 l Text ...
- 中文自然语言处理工具HanLP源码包的下载使用记录
中文自然语言处理工具HanLP源码包的下载使用记录 这篇文章主要分享的是hanlp自然语言处理源码的下载,数据集的下载,以及将让源代码中的demo能够跑通.Hanlp安装包的下载以及安装其实之前就已经 ...
- 自然语言处理工具hanlp自定义词汇添加图解
过程分析 1.添加新词需要确定无缓存文件,否则无法使用成功,因为词典会优先加载缓存文件 2.再确认缓存文件不在时,打开本地词典按照格式添加自定义词汇. 3.调用分词函数重新生成缓存文件,这时会报一个找 ...
- 自然语言处理工具hanlp 1.7.3版本更新内容一览
HanLP 1.7.3 发布了.HanLP 是由一系列模型与算法组成的 Java 工具包,目标是普及自然语言处理在生产环境中的应用.HanLP 具备功能完善.性能高效.架构清晰.语料时新.可自定义的特 ...
- 中文自然语言处理工具hanlp隐马角色标注详解
本文旨在介绍如何利用HanLP训练分词模型,包括语料格式.语料预处理.训练接口.输出格式等. 目前HanLP内置的训练接口是针对一阶HMM-NGram设计的,另外附带了通用的语料加载工具,可以通过少量 ...
- 自然语言处理工具HanLP被收录中国大数据产业发展的创新技术新书《数据之翼》
在12月20日由中国电子信息产业发展研究院主办的2018中国软件大会上,大快搜索获评“2018中国大数据基础软件领域领军企业”,并成功入选中国数字化转型TOP100服务商. 图:大快搜索获评“2018 ...
- 自然语言分析工具Hanlp依存文法分析python使用总结(附带依存关系英文简写的中文解释)
最近在做一个应用依存文法分析来提取文本中各种关系的词语的任务.例如:text=‘新中国在马克思的思想和恩格斯的理论阔步向前’: 我需要提取这个text中的并列的两个关系,从文中分析可知,“马克思的思想 ...
随机推荐
- springmvc跳转到自定义404页面的三种方法
有时候我们并不想跳转到系统自定义的错误页面中,那么我们需要自定义页面并且实现它的跳转 有三种方法可以实现 方法一:最简单的实现,也是最快的 在<web-app>节点下配置 代码如下: &l ...
- GIL 相关 和进程池
#GIL (global interpreter Lock) #全局解释器锁 :锁是为了避免资源竞争造成数据错乱 #当一个py启动后 会先执行主线程中的代码#在以上代码中有启动了子线程 子线程的任务还 ...
- 【转载】 强化学习(二)马尔科夫决策过程(MDP)
原文地址: https://www.cnblogs.com/pinard/p/9426283.html ------------------------------------------------ ...
- MMON进程手工启动
手工启动MMON进程 1. 故障现象 #某帅哥接到业务人员反映系统缓慢,RAC环境 #生成AWR报告发现节点1没有数据 #查询快照视图,发现只有节点1没有快照记录,节点2正常存在快照记录 SYS &g ...
- 螺旋图 comet3 (comet) 不同轴的圆周运动图
matlab 绘图 螺旋图小实例 动态显示comet3函数(comet显示平面) t=[:]; x=*t*sin(pi/).*cos(*t); y=*t*sin(pi/).*sin(*t); z=* ...
- 算法训练 K好数 解析
算法训练 K好数 时间限制:1.0s 内存限制:256.0MB 提交此题 锦囊1 锦囊2 问题描述 如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数.求L位K ...
- C与C++中实现 gotoxy()函数
#include <stdio.h> #include <windows.h> void gotoxy(int x, int y) { COORD pos = {x,y}; H ...
- Autofac解耦事件总线
事件总线之Autofac解耦 事件总线是通过一个中间服务,剥离了常规事件的发布与订阅(消费)强依赖关系的一种技术实现.事件总线的基础知识可参考圣杰的博客[事件总线知多少] 本片博客不再详细概述事件总线 ...
- EasyUI datagrid 查询、设置、提交 三
查询 $(“#grid”).datagrid(“load”,{ a: $('#id').val(),b :$('#text').val() }); {} 里面可以 是序列化参数 $(“#grid ...
- Python基础练习及答案
1.请用代码实现:利用下划线将列表的每一个元素拼接成字符串,li=['alex', 'eric', 'rain'] 该题目主要是考的字符串的拼接,join方法, s = "" li ...