强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)
强化学习策略梯度方法之: REINFORCE 算法 (从原理到代码实现)
2018-04-01 15:15:42
最近在看policy gradient algorithm, 其中一种比较经典的算法当属:REINFORCE 算法,已经广泛的应用于各种计算机视觉任务当中。
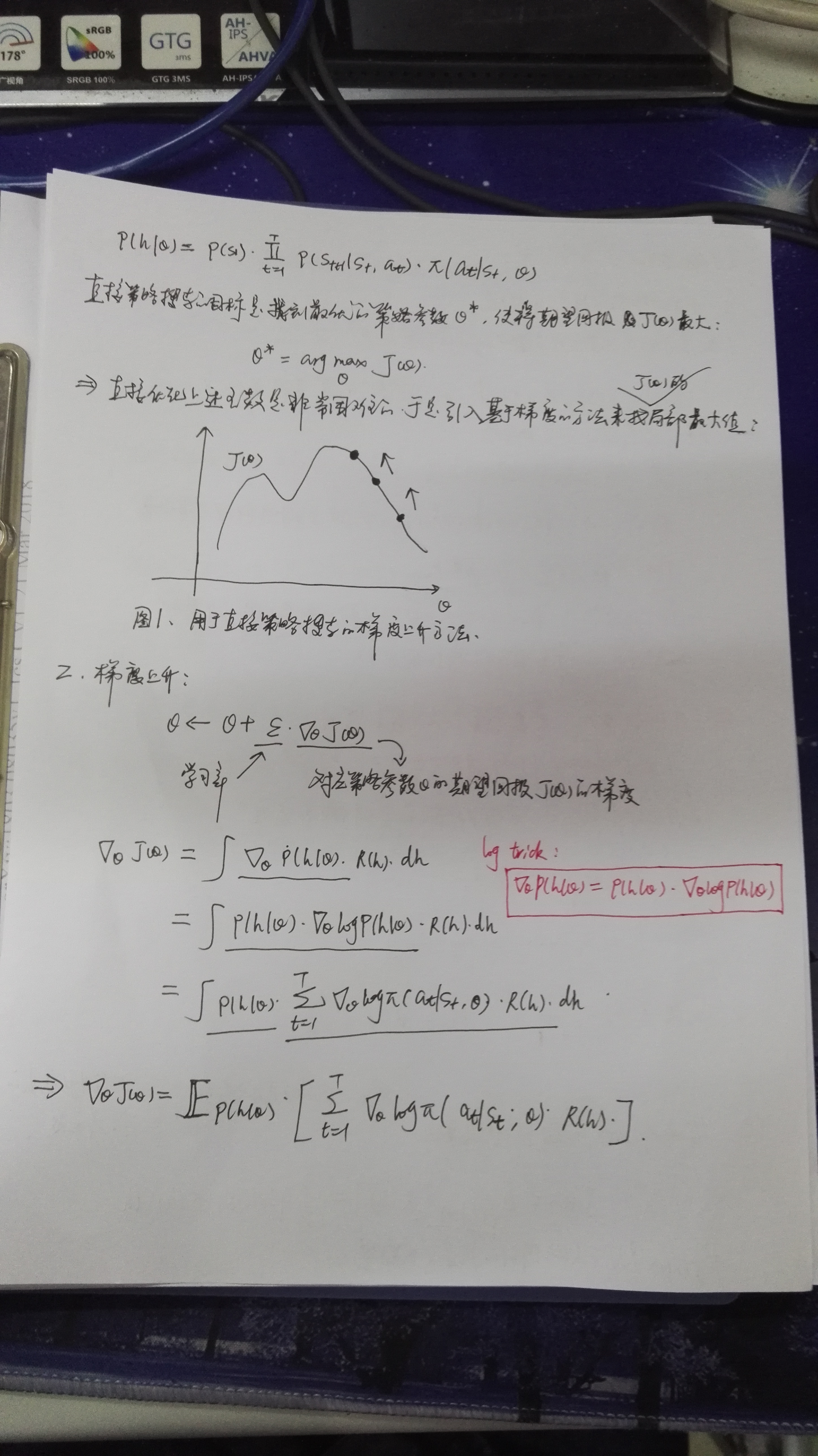
【REINFORCE 算法原理推导】



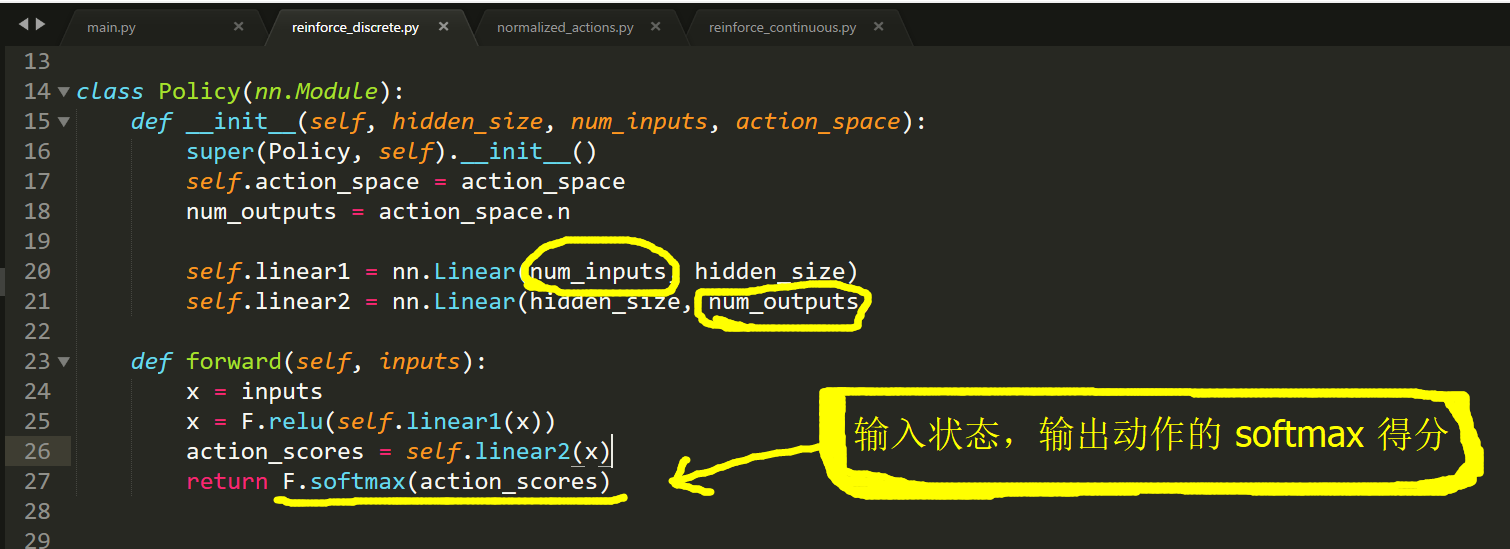
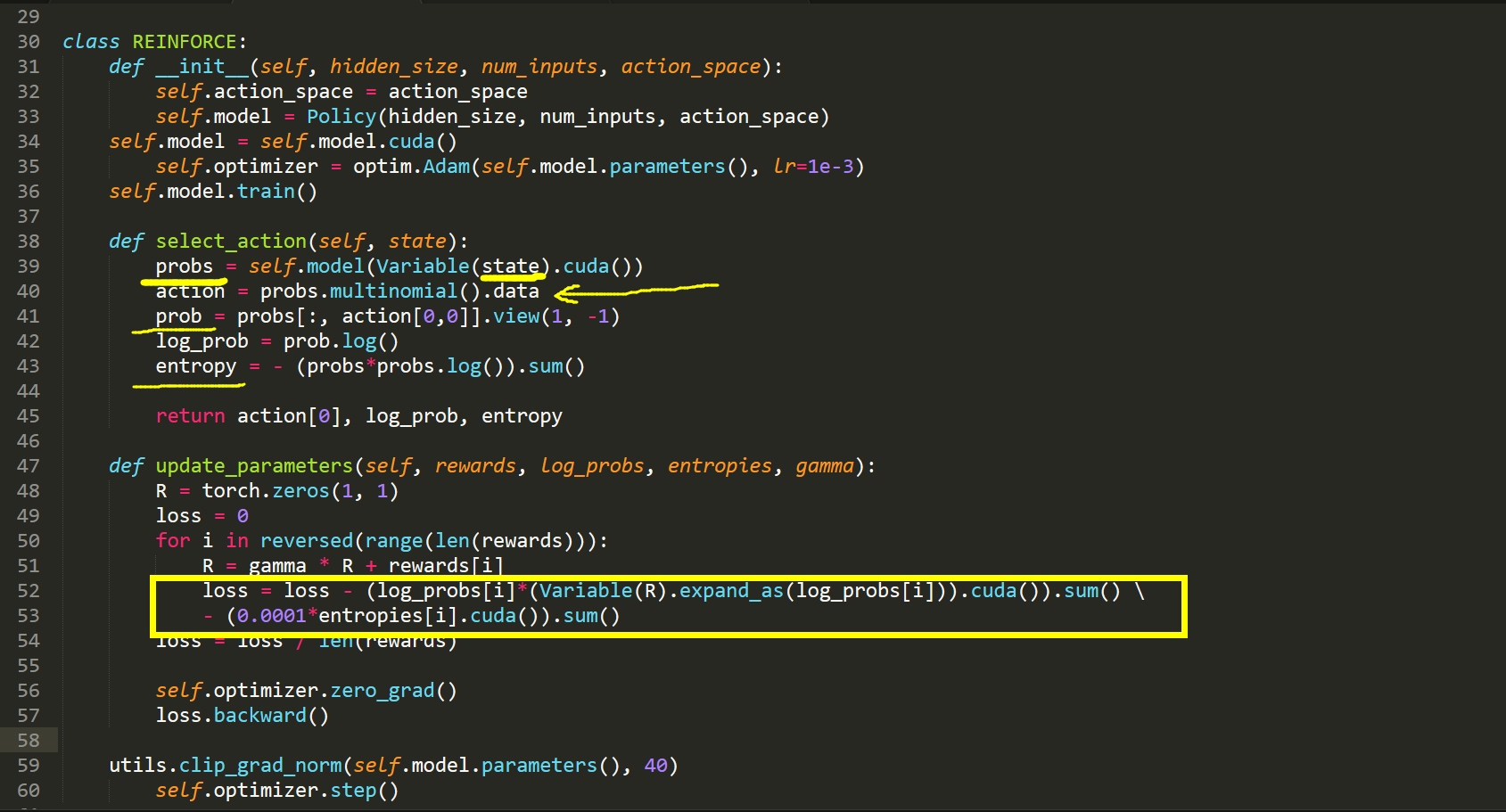
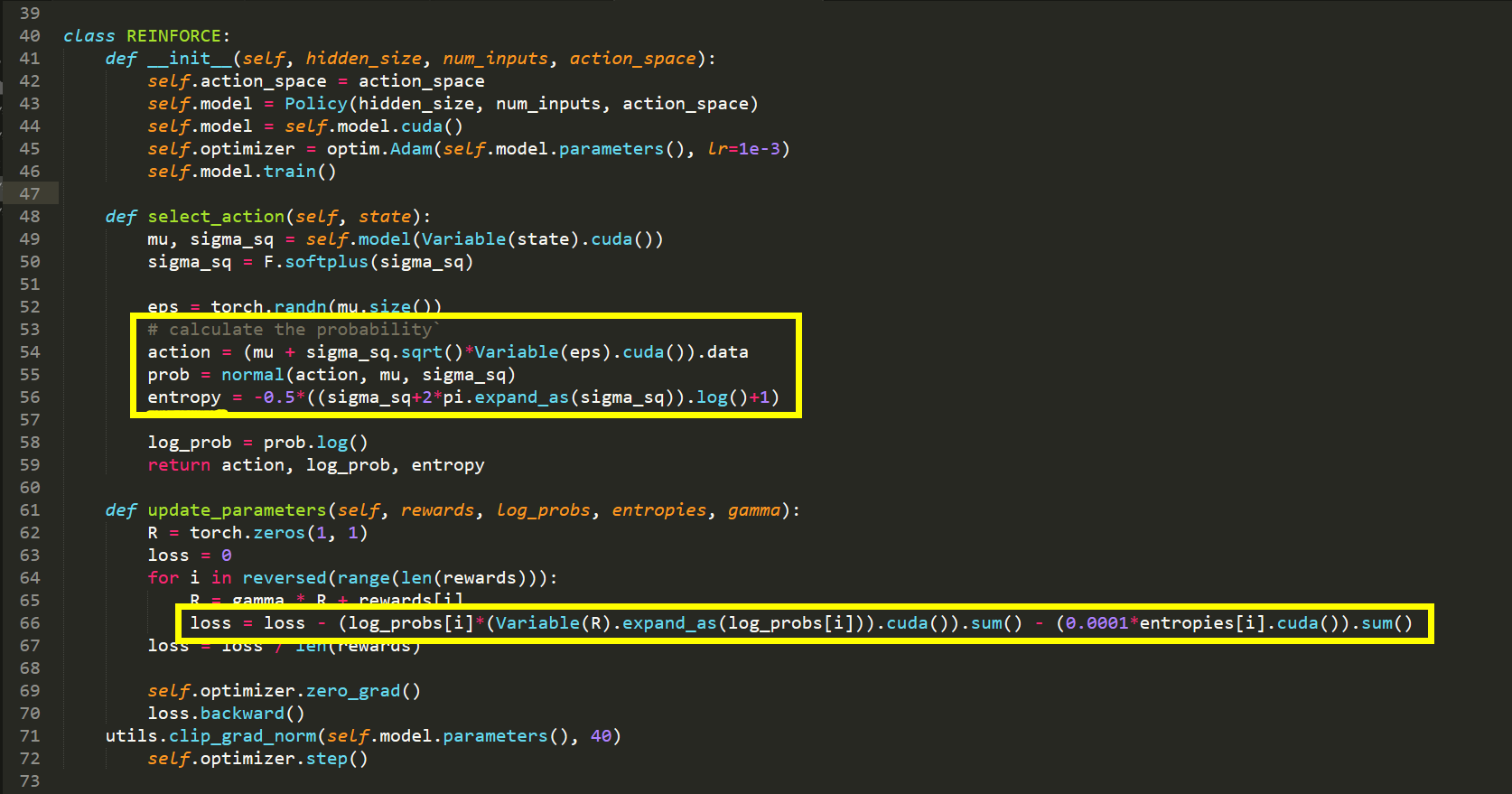
【Pytorch 代码实现】

该图像来自于:https://github.com/JamesChuanggg/pytorch-REINFORCE/blob/master/assets/algo.png
{kind=link}

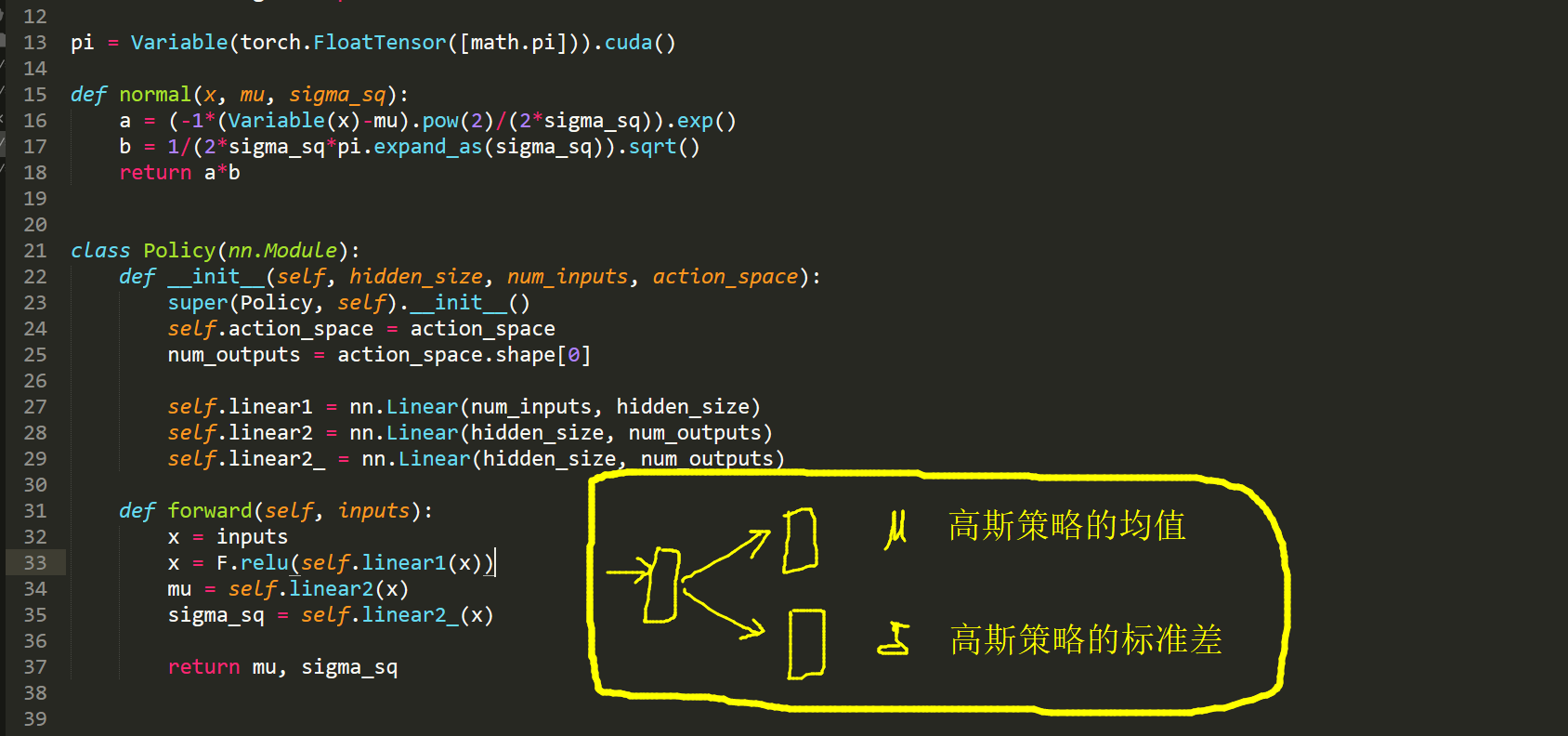
上面函数是 离散情况下的,那么,连续领域是什么情况呢?
-------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------
Reference:
1. 参考博文:http://www.tuananhle.co.uk/notes/reinforce.html
2. 参考博文:http://www.scholarpedia.org/article/Policy_gradient_methods
3. 代码实现(Pytorch version)https://github.com/JamesChuanggg/pytorch-REINFORCE
4. REINFORCE 文章链接:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.129.8871&rep=rep1&type=pdf
5. 书籍:Statistical_Reinforcement_Learning
强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)的更多相关文章
- js学习笔记之排序算法的原理及代码
冒泡排序 比较任何两个相邻的项,如果第一个比第二个大,则交换它们 重复这样的操作,直到排序完成,具体代码如下: let arr = [67,23,11,89,45,76,56,99] function ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods) 前面介绍了很多关于 state or state-action pairs 方面的知识,为了 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- 蜂窝网络TDOA定位方法的Fang算法研究及仿真纠错
科学论文为我们提供科学方法,在解决实际问题中,能极大提高生产效率.但论文中一些失误则可能让使用者浪费大量时间.自己全部再推导那真不容易,怀疑的成本特别高,通常不会选择这条路.而如果真是它的问题,其它所 ...
随机推荐
- multiprocessing 源码解析 更新中......
一.参考链接 1.源码包下载·链接: https://pypi.org/search/?q=multiprocessing+ 2.源码包 链接:https://pan.baidu.com/s/1j ...
- js中的children实时获取子元素
先看下面一个小例子的结果 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&q ...
- linux 下 tomcat 运行报错 Broken pipe
linux 下 tomcat 运行报错 Broken pipe 感谢:http://hi.baidu.com/liupenglover/blog/item/4048c23ff19f1cd67d1e71 ...
- Django 创建项目流程
django 项目创建流程 1 创建项目 cmd django-admin startproject 项目名称 pycharm file -- new project -- Django -- 项目名 ...
- 74.Java异常处理机制
package testDate; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IO ...
- [转载]ASP.NET页面之间传递值的几种方式
页面传值是学习asp.net初期都会面临的一个问题,总的来说有页面传值.存储对象传值.ajax.类.model.表单等.但是一般来说,常用的较简单有QueryString,Session,Cookie ...
- 费马小定理与GCD&LCM
若 t = 1 , a ^ ( p - 2 ) 为 a 在取模 p 意义下的乘法逆元 通常用 inv 表示 证明: b * a =(三等)1(mod p) a ^ ( p - 2 ) * a =(三 ...
- js 简易时钟
html部分 <div id="clock"> </div> css部分 #clock{ width:600px ; text-align: center; ...
- The Little Prince-12/06
The Little Prince-12/06 “That doesn't matter. Draw me a sheep.” When the prince ask the planet to dr ...
- 【视频】使用fiddler开发工具进行新架构页面本地调试
[视频]使用fiddler开发工具进行新架构页面本地调试,视频没录制好,有些部分比较模糊...