POJ 1330 Nearest Common Ancestors(Targin求LCA)
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 26612 | Accepted: 13734 |
Description
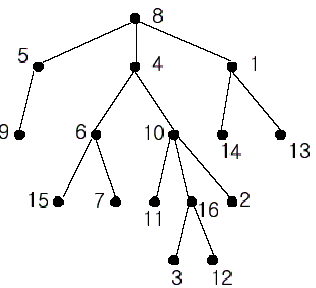
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
Output
Sample Input
2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 11 6 7 10 2 16 3 8 1 16 12 16 7 5 2 3 3 4 3 1 1 5 3 5
Sample Output
4 3
思路
最近公共祖先模板题
#include<iostream>
#include<cstdio>
#include<cstring>
#include<vector>
using namespace std;
const int maxn = 10005;
struct Edge{
int to,next;
}edge[maxn];
vector<int>qry[maxn];
int N,tot,fa[maxn],head[maxn],indegree[maxn],ancestor[maxn];
bool vis[maxn];
void init()
{
tot = 0;
for (int i = 1;i <= N;i++) fa[i] = i,head[i] = -1,indegree[i] = 0,vis[i] = false,qry[i].clear();
}
void addedge(int u,int to)
{
edge[tot] = (Edge){to,head[u]};
head[u] = tot++;
}
int find(int x)
{
int r = x;
while (r != fa[r]) r = fa[r];
int i = x,j;
while (i != r)
{
j = fa[i];
fa[i] = r;
i = j;
}
return r;
}
void Union(int x,int y)
{
x = find(x),y = find(y);
if (x == y) return;
fa[y] = x; //不能写成fa[x] = y,与集合合并的祖先有关系
}
void targin_LCA(int u)
{
ancestor[u] = u;
for (int i = head[u];i != -1;i = edge[i].next)
{
int v = edge[i].to;
targin_LCA(v);
Union(u,v);
ancestor[find(u)] = u;
}
vis[u] = true;
int size = qry[u].size();
for (int i = 0;i < size;i++)
{
if (vis[qry[u][i]]) printf("%d\n",ancestor[find(qry[u][i])]);
return;
}
}
int main()
{
int T;
scanf("%d",&T);
while (T--)
{
int u,v;
scanf("%d",&N);
init();
for (int i = 1;i < N;i++)
{
scanf("%d%d",&u,&v);
addedge(u,v);
indegree[v]++;
}
scanf("%d%d",&u,&v);
qry[u].push_back(v),qry[v].push_back(u);
for (int i = 1;i <= N;i++)
{
if (!indegree[i])
{
targin_LCA(i);
break;
}
}
}
return 0;
}
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<algorithm>
#include<math.h>
#include<vector>
using namespace std;
const int MAXN=10010;
int F[MAXN];//并查集
int r[MAXN];//并查集中集合的个数
bool vis[MAXN];//访问标记
int ancestor[MAXN];//祖先
struct Node
{
int to,next;
}edge[MAXN*2];
int head[MAXN];
int tol;
void addedge(int a,int b)
{
edge[tol].to=b;
edge[tol].next=head[a];
head[a]=tol++;
edge[tol].to=a;
edge[tol].next=head[b];
head[b]=tol++;
}
struct Query
{
int q,next;
int index;//查询编号
}query[MAXN*2];//查询数
int answer[MAXN*2];//查询结果
int cnt;
int h[MAXN];
int tt;
int Q;//查询个数
void add_query(int a,int b,int i)
{
query[tt].q=b;
query[tt].next=h[a];
query[tt].index=i;
h[a]=tt++;
query[tt].q=a;
query[tt].next=h[b];
query[tt].index=i;
h[b]=tt++;
}
void init(int n)
{
for(int i=1;i<=n;i++)
{
F[i]=-1;
r[i]=1;
vis[i]=false;
ancestor[i]=0;
tol=0;
tt=0;
cnt=0;//已经查询到的个数
}
memset(head,-1,sizeof(head));
memset(h,-1,sizeof(h));
}
int find(int x)
{
if(F[x]==-1)return x;
return F[x]=find(F[x]);
}
void Union(int x,int y)//合并
{
int t1=find(x);
int t2=find(y);
if(t1!=t2)
{
if(r[t1]<=r[t2])
{
F[t1]=t2;
r[t2]+=r[t1];
}
else
{
F[t2]=t1;
r[t1]+=r[t2];
}
}
}
void LCA(int u)
{
//if(cnt>=Q)return;//不要加这个
ancestor[u]=u;
vis[u]=true;//这个一定要放在前面
for(int i=head[u];i!=-1;i=edge[i].next)
{
int v=edge[i].to;
if(vis[v])continue;
LCA(v);
Union(u,v);
ancestor[find(u)]=u;
}
for(int i=h[u];i!=-1;i=query[i].next)
{
int v=query[i].q;
if(vis[v])
{
answer[query[i].index]=ancestor[find(v)];
cnt++;//已经找到的答案数
}
}
}
bool flag[MAXN];
int main()
{
//freopen("in.txt","r",stdin);
//freopen("out.txt","w",stdout);
int T;
int N;
int u,v;
scanf("%d",&T);
while(T--)
{
scanf("%d",&N);
init(N);
memset(flag,false,sizeof(flag));
for(int i=1;i<N;i++)
{
scanf("%d%d",&u,&v);
flag[v]=true;
addedge(u,v);
}
Q=1;//查询只有一组
scanf("%d%d",&u,&v);
add_query(u,v,0);//增加一组查询
int root;
for(int i=1;i<=N;i++)
if(!flag[i])
{
root=i;
break;
}
LCA(root);
for(int i=0;i<Q;i++)//输出所有答案
printf("%d\n",answer[i]);
}
return 0;
}
POJ 1330 Nearest Common Ancestors(Targin求LCA)的更多相关文章
- POJ - 1330 Nearest Common Ancestors(基础LCA)
POJ - 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000KB 64bit IO Format: %l ...
- poj 1330 Nearest Common Ancestors 单次LCA/DFS
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19919 Accept ...
- POJ 1330 Nearest Common Ancestors(裸LCA)
Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 39596 Accept ...
- POJ 1330 Nearest Common Ancestors(Tarjan离线LCA)
Description A rooted tree is a well-known data structure in computer science and engineering. An exa ...
- poj 1330 Nearest Common Ancestors 裸的LCA
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> #i ...
- POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA)
POJ 1330 Nearest Common Ancestors / UVALive 2525 Nearest Common Ancestors (最近公共祖先LCA) Description A ...
- POJ.1330 Nearest Common Ancestors (LCA 倍增)
POJ.1330 Nearest Common Ancestors (LCA 倍增) 题意分析 给出一棵树,树上有n个点(n-1)条边,n-1个父子的边的关系a-b.接下来给出xy,求出xy的lca节 ...
- POJ 1330 Nearest Common Ancestors(lca)
POJ 1330 Nearest Common Ancestors A rooted tree is a well-known data structure in computer science a ...
- POJ 1330 Nearest Common Ancestors 倍增算法的LCA
POJ 1330 Nearest Common Ancestors 题意:最近公共祖先的裸题 思路:LCA和ST我们已经很熟悉了,但是这里的f[i][j]却有相似却又不同的含义.f[i][j]表示i节 ...
- LCA POJ 1330 Nearest Common Ancestors
POJ 1330 Nearest Common Ancestors Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 24209 ...
随机推荐
- 生成 PDF 全攻略【1】初体验
经历过多少踩坑,翻看过多少类似博客,下载过多少版本的Jar,才能摸索出正确的代码书写方式,才能实现项目经理需求分析书中的功能点. 本文借一次 JavaEE 生成PDF的颠簸的实现过程,描述中小公司程序 ...
- SQL Server output子句用法 output inserted.id 获取刚插入数据的id
--插入数据,并返回刚刚插入的数据id INSERT INTO [soloreztest] ([name]) output inserted.id VALUES ('solorez') --执行结果: ...
- Eclipse自动补全功能管理
#这种方法只适用于Eclipse Classic版本(这个版本带有插件的源码) 在使用Eclispe的过程,感觉自动补全做的不好,没有VS的强大.下面说两个增强自动补全的方法: 1.增加Eclipse ...
- ubuntu eclipse 不能新建javaweb项目解决方案
ubuntu下,通过sudo apt-get install eclipse 成功安装了eclipse,可它简洁的都让我不知如何新建web project.网上查了众多资料,终于找到了一系列简洁的方法 ...
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- 【转】HTTP协议详解
原文地址:http://www.cnblogs.com/EricaMIN1987_IT/p/3837436.html 一.概念 协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则 ...
- mysql-异常
1.Subquery returns more than 1 row 返回的集合应该是一条才能用,但你返回了多条.
- eclipse-插件安装的三种方式
(前两种安装方式以多国语言包的安装为例) 1. 普通安装:用直接解压的安装方式来实现 解压插件到某个文件夹 将下载的插件文件解压到 Eclipse 的安装目录下 如插件文件为多国语言包: NLpac ...
- java.lang.Exception: No runnable methods
java.lang.Exception: No runnable methods at org.junit.runners.BlockJUnit4ClassRunner.validateInstanc ...
- 【USACO 1.4】Mother's Milk
/* TASK: milk3 LANG: C++ SOLVE: 倒水,dfs,枚举每一种倒法,ca[i][j]记录a和c桶的状态,因为总体积不变,故b的状态不需要记录. */ #include< ...