Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面的操作,我们就把数据准备好了。
一、训练一个model
右击右边Models模块的” Images" 按钮 ,选择“classification"
在打开页面右下角可以看到,系统提供了一个caffe model,分别为LeNet, AlexNet, GoogLeNet, 如果使用这三个模型,则所有参数都已经设置好了,就不用再设置了。
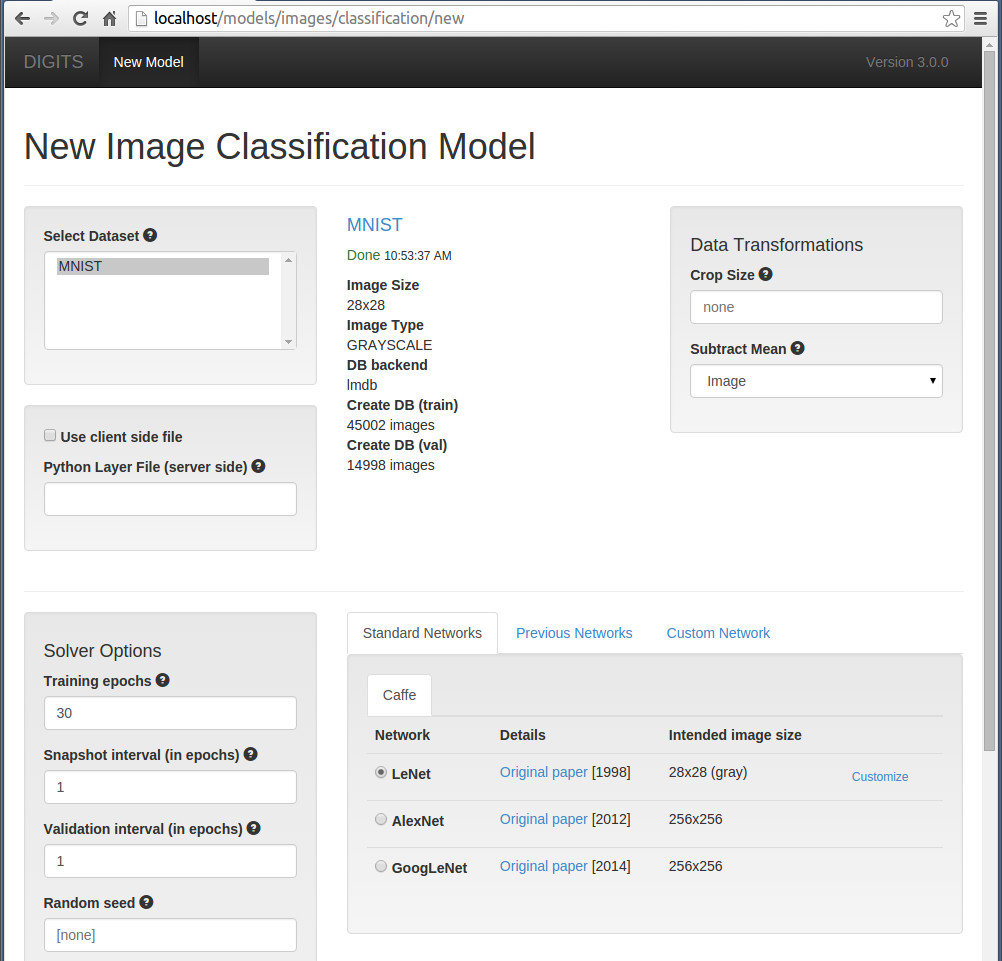
在下面,系统为我们列举出了本机所带的显卡,我们可以选择其中一块进行运行。
在最下面,输入一个model name, 就可以点击create 按钮了。如果有些选项不对,会有错误提示,很人性化。

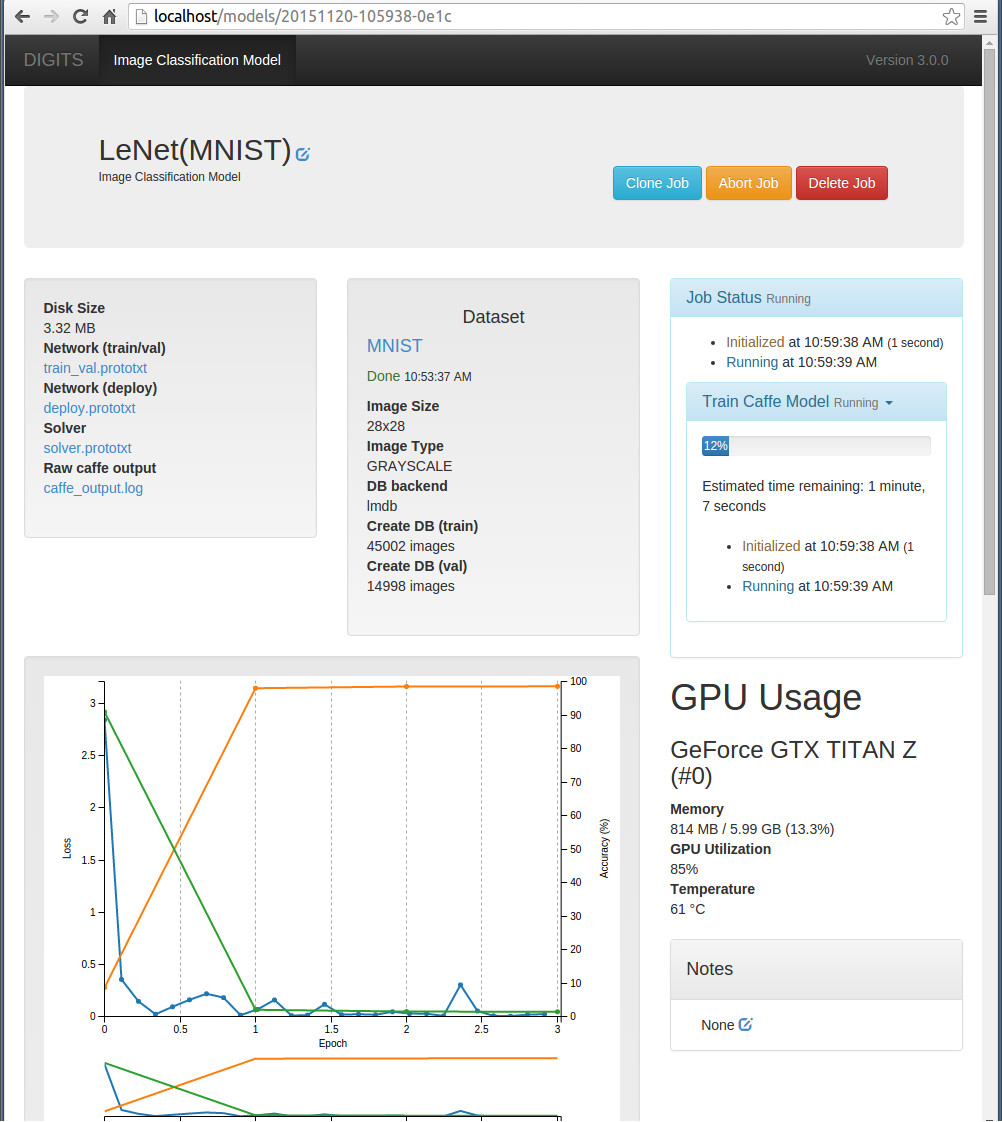
在训练过程页面,左上角显示了生成的配置文件名称 (放在job目录文件下,默认路径为:/usr/share/digits/digits/jobs/),运行过程中保存的caffemodel快照也保存在这个目录下面。
页面中间显示了训练和测试的数据信息,右面显示了训练所用的时间和gpu使用情况,下面就是一些实时化图表,可以看到训练阶段的loss, 测试阶段的loss和accuracy,相当方便,甚至还可以看到学习率的变化情况,吃惊吧!
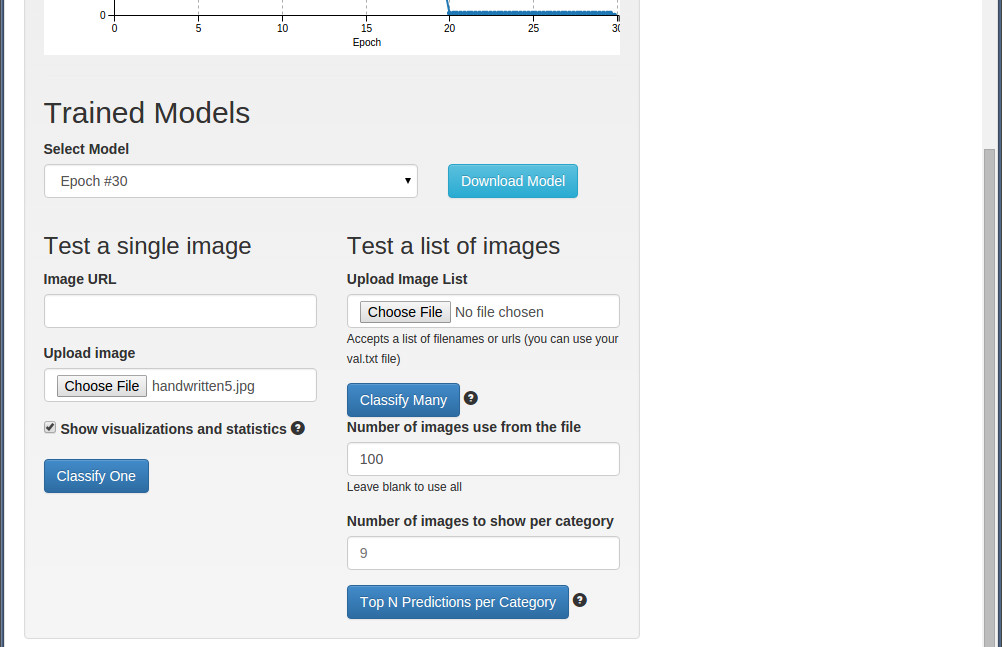
模型训练好后,直接就可以在下面进行测试了。
二、测试新来的图片
将页面拖到最下面,选择Upload imager按钮,加载一幅测试图片。在 /home/username/mnist/test/ 下面有大量的测试图片,随便选一张就可以了。
也可以通过在Image URL方框里,输入一张网上的图片地址来进行测试。
加载好测试图片,在 Show visualizations and statistics 选择模式框上点上勾。
点击”Classify One" 按钮就可以开始测试了。
如果你不是对一张图片进行测试,而是一个测试集,则是在" Upload Image List"这个地方,选择测试图片的列表清单文件(如 val.txt)
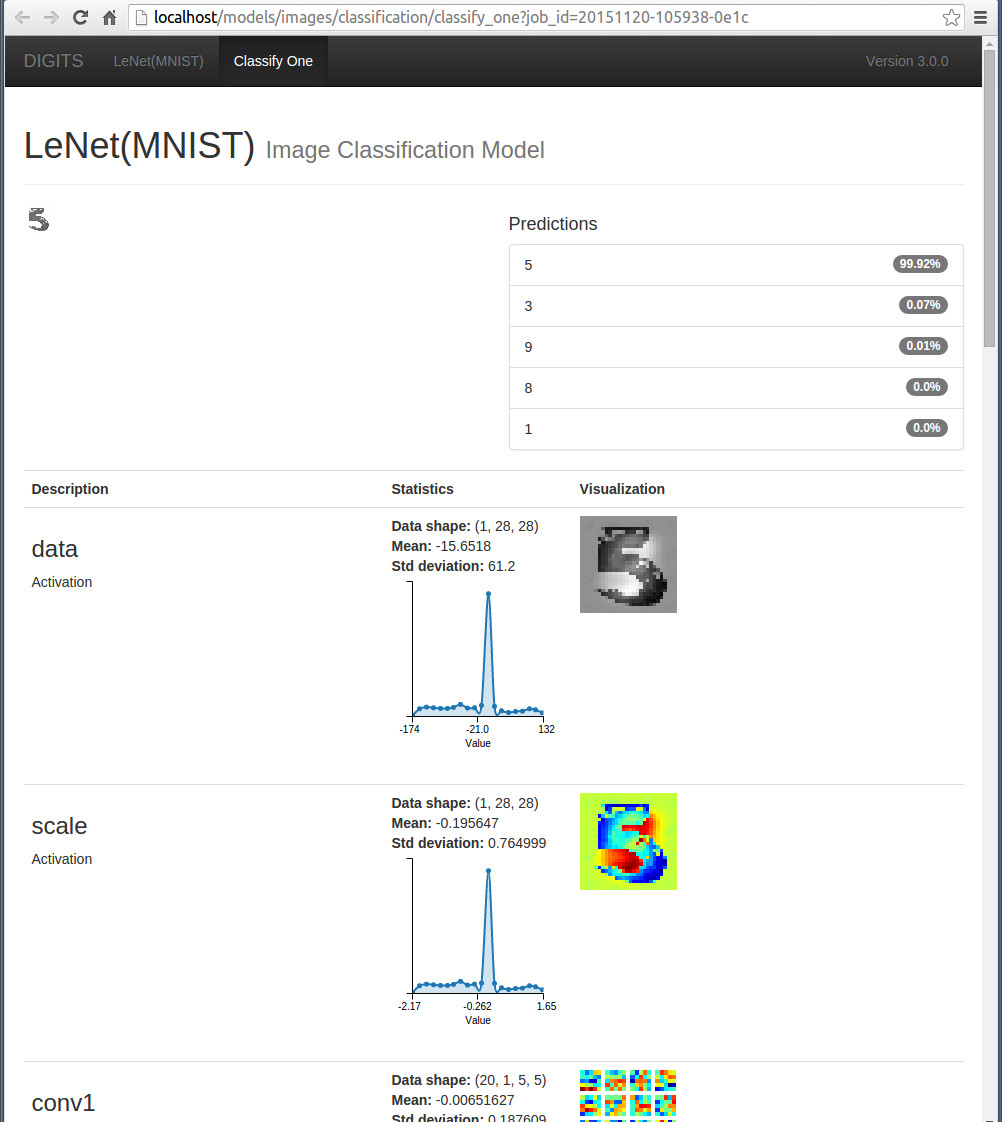
系统会弹出一个新的页面,显示top-5的分类情况 ,同时digits还提供了测试数据与权值的可视化和统计信息。
最后一句话总结,nvidia digits, 谁用谁知道!
Caffe学习系列(22):caffe图形化操作工具digits运行实例的更多相关文章
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化. 如果还没有学会的,请自行细细阅读: caffe学习系列:http:/ ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
随机推荐
- CYQ.Data 数据框架 使用篇一 入门指南
快速使用帮助 | 回贴(13) | 浏览(11303) | 发表日期 :2010-12-20 20:12:29 #楼主 本文针对V5版本进行修改于(2016-07-04) 下面是使用步骤: 一 ...
- EMC Documentum DQL整理(一)
1.Get user SELECT * FROM dm_user WHERE r_is_group = 0 2.Get Group SELECT * FROM dm_group WHERE gro ...
- Javascript之旅——第十站:为什么都说闭包难理解呢?
研究过js的朋友大多会说,理解了js的原型和闭包就可以了,然后又说这些都是js的高级内容,然后就又扯到了各种神马的作用域...然后不少 人就会被忽悠的云里雾里...下面我也试着来说说闭包,看我说的这个 ...
- 【转载】Linux NFS服务器的安装与配置
一.NFS服务简介 NFS 是Network File System的缩写,即网络文件系统.一种使用于分散式文件系统的协定,由Sun公司开发,于1984年向外公布.功能是通过网络让不同的机器.不同的操 ...
- Java NIO 同步非阻塞
同步非阻塞IO (NIO) NIO是基于事件驱动思想的,实现上通常采用Reactor(http://en.wikipedia.org/wiki/Reactor_pattern)模式,从程序角度而言,当 ...
- mysql截取longblob类型字段内一小块数据的方法
由于longblob类型的字段内容一般都好大,最大限制是4G,所以在数据查询中读取一整块数据的方式是不现实的,这需要要截取的方法来获取需要的数据. 方法如下: hex(substring(A, ind ...
- JavaScript学习笔记–(new关键字)
作用 是创建一个对象实例.这个对象可以是用户自定义的,也可以是一些系统自带的带构造函数的对象. 描述 创建一个对象类型需要创建一个指定了名称和属性的函数:其中这些属性可以指向它本身,也可以指向其他对象 ...
- Unknown class in Interface Builder file 解决方案
在用swift项目打包Framework时,在项目中使用包时,报错: Unknown class in Interface Builder file... 网上很多解决方案,都不适合我的场景 最终解决 ...
- day 2 系统分区 扩展.md
1.分区类型 主分区: 最多只能有四个. 扩展分区: 最多只能有一个. 主分区加扩展分区最多有4个. 不能写入数据,只能包含逻辑分区. 逻辑分区 2.格式化 格式化(高级格式化)又称逻辑格式化,它是指 ...
- Android adb push 和 pull操作
由于安卓真机本地调试时,每次启动并生成apk然后安装到设备比较费时,而很多情况是仅仅修改了hot 脚本文件(cocos2dx + lua). 所以,使用热更机制把修改后的lua文件push到热更目录( ...