第07讲:Flink 常见核心概念分析
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
在 Flink 这个框架中,有很多独有的概念,比如分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解的,这一课时我将会从原理和应用场景分别介绍这些概念。
分布式缓存
熟悉 Hadoop 的你应该知道,分布式缓存最初的思想诞生于 Hadoop 框架,Hadoop 会将一些数据或者文件缓存在 HDFS 上,在分布式环境中让所有的计算节点调用同一个配置文件。在 Flink 中,Flink 框架开发者们同样将这个特性进行了实现。
Flink 提供的分布式缓存类型 Hadoop,目的是为了在分布式环境中让每一个 TaskManager 节点保存一份相同的数据或者文件,当前计算节点的 task 就像读取本地文件一样拉取这些配置。
分布式缓存在我们实际生产环境中最广泛的一个应用,就是在进行表与表 Join 操作时,如果一个表很大,另一个表很小,那么我们就可以把较小的表进行缓存,在每个 TaskManager 都保存一份,然后进行 Join 操作。
那么我们应该怎样使用 Flink 的分布式缓存呢?举例如下:
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.registerCachedFile("/Users/wangzhiwu/WorkSpace/quickstart/distributedcache.txt", "distributedCache");
//1:注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
DataSource<String> data = env.fromElements("Linea", "Lineb", "Linec", "Lined");
DataSet<String> result = data.map(new RichMapFunction<String, String>() {
private ArrayList<String> dataList = new ArrayList<String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//2:使用该缓存文件
File myFile = getRuntimeContext().getDistributedCache().getFile("distributedCache");
List<String> lines = FileUtils.readLines(myFile);
for (String line : lines) {
this.dataList.add(line);
System.err.println("分布式缓存为:" + line);
}
}
@Override
public String map(String value) throws Exception {
//在这里就可以使用dataList
System.err.println("使用datalist:" + dataList + "-------" +value);
//业务逻辑
return dataList +":" + value;
}
});
result.printToErr();
}
从上面的例子中可以看出,使用分布式缓存有两个步骤。
- 第一步:首先需要在 env 环境中注册一个文件,该文件可以来源于本地,也可以来源于 HDFS ,并且为该文件取一个名字。
- 第二步:在使用分布式缓存时,可根据注册的名字直接获取。
可以看到,在上述案例中,我们把一个本地的 distributedcache.txt 文件注册为 distributedCache,在下面的 map 算子中直接通过这个名字将缓存文件进行读取并且进行了处理。
我们直接运行该程序,在控制台可以看到如下输出:


在使用分布式缓存时也需要注意一些问题,需要我们缓存的文件在任务运行期间最好是只读状态,否则会造成数据的一致性问题。另外,缓存的文件和数据不宜过大,否则会影响 Task 的执行速度,在极端情况下会造成 OOM。
故障恢复和重启策略
自动故障恢复是 Flink 提供的一个强大的功能,在实际运行环境中,我们会遇到各种各样的问题从而导致应用挂掉,比如我们经常遇到的非法数据、网络抖动等。
Flink 提供了强大的可配置故障恢复和重启策略来进行自动恢复。
故障恢复
我们在上一课时中介绍过 Flink 的配置文件,其中有一个参数 jobmanager.execution.failover-strategy: region。
Flink 支持了不同级别的故障恢复策略,jobmanager.execution.failover-strategy 的可配置项有两种:full 和 region。
当我们配置的故障恢复策略为 full 时,集群中的 Task 发生故障,那么该任务的所有 Task 都会发生重启。而在实际生产环境中,我们的大作业可能有几百个 Task,出现一次异常如果进行整个任务重启,那么经常会导致长时间任务不能正常工作,导致数据延迟。
但是事实上,我们可能只是集群中某一个或几个 Task 发生了故障,只需要重启有问题的一部分即可,这就是 Flink 基于 Region 的局部重启策略。在这个策略下,Flink 会把我们的任务分成不同的 Region,当某一个 Task 发生故障时,Flink 会计算需要故障恢复的最小 Region。
Flink 在判断需要重启的 Region 时,采用了以下的判断逻辑:
- 发生错误的 Task 所在的 Region 需要重启;
- 如果当前 Region 的依赖数据出现损坏或者部分丢失,那么生产数据的 Region 也需要重启;
- 为了保证数据一致性,当前 Region 的下游 Region 也需要重启。
重启策略
Flink 提供了多种类型和级别的重启策略,常用的重启策略包括:
- 固定延迟重启策略模式
- 失败率重启策略模式
- 无重启策略模式
Flink 在判断使用的哪种重启策略时做了默认约定,如果用户配置了 checkpoint,但没有设置重启策略,那么会按照固定延迟重启策略模式进行重启;如果用户没有配置 checkpoint,那么默认不会重启。
下面我们分别对这三种模式进行详细讲解。
无重启策略模式
在这种情况下,如果我们的作业发生错误,任务会直接退出。
我们可以在 flink-conf.yaml 中配置:
复制代码
restart-strategy: none
也可以在程序中使用代码指定:
复制代码
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
固定延迟重启策略模式
固定延迟重启策略会通过在 flink-conf.yaml 中设置如下配置参数,来启用此策略:
复制代码
restart-strategy: fixed-delay
固定延迟重启策略模式需要指定两个参数,首先 Flink 会根据用户配置的重试次数进行重试,每次重试之间根据配置的时间间隔进行重试,如下表所示:
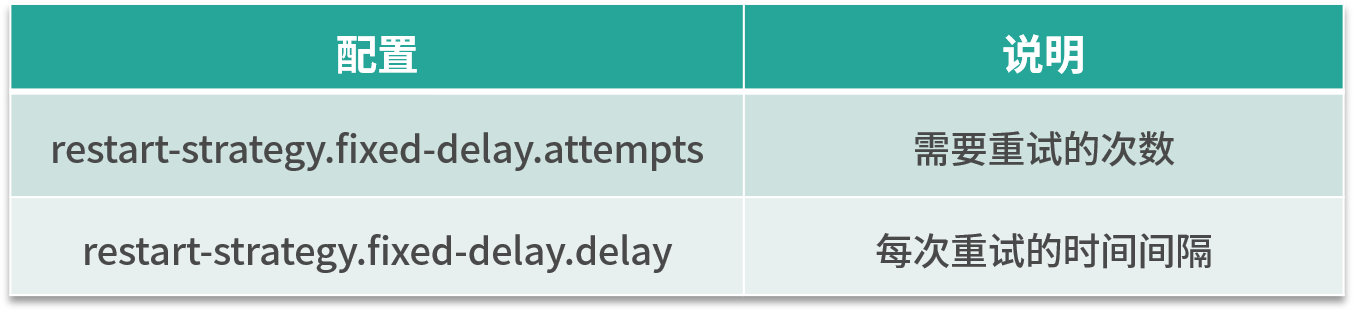
举个例子,假如我们需要任务重试 3 次,每次重试间隔 5 秒,那么需要进行一下配置:
复制代码
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 5 s
当前我们也可以在代码中进行设置:
复制代码
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(5, TimeUnit.SECONDS) // 时间间隔
));
失败率重启策略模式
首先我们在 flink-conf.yaml 中指定如下配置:
复制代码
restart-strategy: failure-rate
这种重启模式需要指定三个参数,如下表所示。失败率重启策略在 Job 失败后会重启,但是超过失败率后,Job 会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
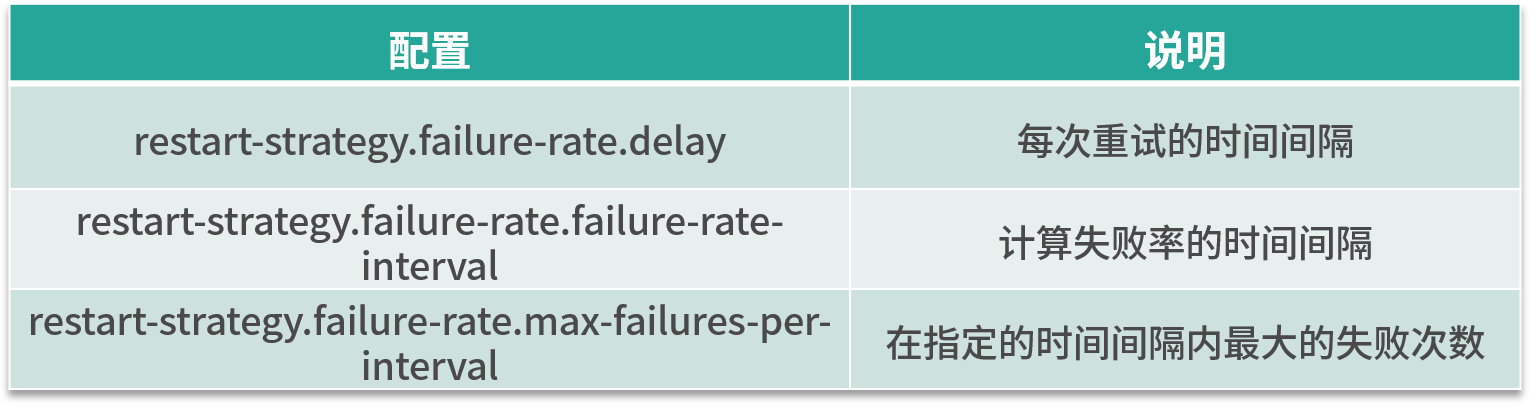
这种策略的配置理解较为困难,我们举个例子,假如 5 分钟内若失败了 3 次,则认为该任务失败,每次失败的重试间隔为 5 秒。
那么我们的配置应该是:
复制代码
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 5 s
当然,也可以在代码中直接指定:
复制代码
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔
Time.of(5, TimeUnit.SECONDS) // 每次任务失败时间间隔
));
最后,需要注意的是,在实际生产环境中由于每个任务的负载和资源消耗不一样,我们推荐在代码中指定每个任务的重试机制和重启策略。
并行度
并行度是 Flink 执行任务的核心概念之一,它被定义为在分布式运行环境中我们的一个算子任务被切分成了多少个子任务并行执行。我们提高任务的并行度(Parallelism)在很大程度上可以大大提高任务运行速度。
一般情况下,我们可以通过四种级别来设置任务的并行度。
- 算子级别
在代码中可以调用 setParallelism 方法来设置每一个算子的并行度。例如:
复制代码
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1).setParallelism(1);
事实上,Flink 的每个算子都可以单独设置并行度。这也是我们最推荐的一种方式,可以针对每个算子进行任务的调优。
- 执行环境级别
我们在创建 Flink 的上下文时可以显示的调用 env.setParallelism() 方法,来设置当前执行环境的并行度,这个配置会对当前任务的所有算子、Source、Sink 生效。当然你还可以在算子级别设置并行度来覆盖这个设置。
复制代码
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(5);
- 提交任务级别
用户在提交任务时,可以显示的指定 -p 参数来设置任务的并行度,例如:
复制代码
./bin/flink run -p 10 WordCount.jar
- 系统配置级别
我们在上一课时中提到了 flink-conf.yaml 中的一个配置:parallelism.default,该配置即是在系统层面设置所有执行环境的并行度配置。
整体上讲,这四种级别的配置生效优先级如下:算子级别 > 执行环境级别 > 提交任务级别 > 系统配置级别。
在这里,要特别提一下 Flink 中的 Slot 概念。我们知道,Flink 中的 TaskManager 是执行任务的节点,那么在每一个 TaskManager 里,还会有“槽位”,也就是 Slot。Slot 个数代表的是每一个 TaskManager 的并发执行能力。
假如我们指定 taskmanager.numberOfTaskSlots:3,即每个 taskManager 有 3 个 Slot ,那么整个集群就有 3 * taskManager 的个数多的槽位。这些槽位就是我们整个集群所拥有的所有执行任务的资源。
总结
这一课时我们讲解了 Flink 中常见的分布式缓存、重启策略、并行度几个核心的概念和实际配置,这些概念的正确理解和合理配置是后面我们进行资源调优和任务优化的基础。在下一课时中我们会对 Flink 中最难以理解的“窗口和水印”进行讲解。
关注公众号:
大数据技术派,回复资料,领取1024G资料。
第07讲:Flink 常见核心概念分析的更多相关文章
- 小马哥讲Spring栈核心编程思想 Spring IoC+Bean+Framework
小马哥出手的Spring栈核心编程思想课程,可以说是非常专业和权威的Spring课程.课程主要的方向与核心是Spring Framework总览,带领同学们重新认识重新认识IoC,Spring IoC ...
- 第07讲- Android项目的打包apk
第07讲Android项目的打包apk 方法一:在工作目录bin文件夹下有一个与项目同名的apk文件 (最懒惰的方式,不推荐,不安全,不利于版本更新,只有在开发模式时使用) 方法二:使用key方式 签 ...
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
- nginx中的模块分类及常见核心模块有哪些
1.模块分类 核心模块:是 Nginx 服务器正常运行必不可少的模块,提供错误日志记录 .配置文件解析 .事件驱动机制 .进程管理等核心功能 标准HTTP模块:提供 HTTP 协议解析相关的功能,比如 ...
- Flink SQL 核心概念剖析与编程案例实战
本次,我们从 0 开始逐步剖析 Flink SQL 的来龙去脉以及核心概念,并附带完整的示例程序,希望对大家有帮助! 本文大纲 一.快速体验 Flink SQL 为了快速搭建环境体验 Flink SQ ...
- Flink Runtime核心机制剖析(转)
本文主要介绍 Flink Runtime 的作业执行的核心机制.本文将首先介绍 Flink Runtime 的整体架构以及 Job 的基本执行流程,然后介绍在这个过程,Flink 是怎么进行资源管理. ...
- Apache Flink - 常见数据流类型
DataStream: DataStream 是 Flink 流处理 API 中最核心的数据结构.它代表了一个运行在多个分区上的并行流.一个 DataStream 可以从 StreamExecutio ...
- PHP学习之[第07讲]PHP5.4 文件操作函数 之 图片计数器的实例
1.filetype():输出文件类型: 2.stat():获取文件的基本属性的数组: 3.clearstatcache().is_executable().isDir().idFile().scan ...
- kubernetes入门(07)kubernetes的核心概念(4)
一.pod 二.Volume volume可以为容器提供持久化存储,比如 三.私有镜像 在使用私有镜像时,需要创建一个docker registry secret,并在容器中引用.创建docker r ...
随机推荐
- 1135 - Count the Multiples of 3
1135 - Count the Multiples of 3 PDF (English) Statistics Forum Time Limit: 3 second(s) Memory Limi ...
- 洛谷1052——过河(DP+状态压缩)
题目描述 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧.在桥上有一些石子,青蛙很讨厌踩在这些石子上.由于桥的长度和青蛙一次跳过的距离都是正整数,我们可以把独木桥上青蛙可能到达的点看成数 ...
- Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks
目录 概 主要内容 算法 一些有趣的指标 鲁棒性定义 合格的抗干扰机制 Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, Ananthram ...
- matplotlib 进阶之Legend guide
目录 matplotlib.pyplot.legend 方法1自动检测 方法2为现有的Artist添加 方3显示添加图例 控制图例的输入 为一类Artist设置图例 Legend 的位置 loc, b ...
- Java初学者作业——定义英雄类(Hero),英雄类中的属性包括:姓名、攻击力、防御力、生命值和魔法值;方法包括:攻击、介绍。
返回本章节 返回作业目录 需求说明: 定义英雄类(Hero),英雄类中的属性包括:姓名.攻击力.防御力.生命值和魔法值:方法包括:攻击.介绍. 实现思路: 分析类的属性及其变量类型. 分析类的方法及其 ...
- 使用.NET 6开发TodoList应用(17)——实现数据塑形
系列导航及源代码 使用.NET 6开发TodoList应用文章索引 需求 在查询的场景中,还有一类需求不是很常见,就是在前端请求中指定返回的字段,所以关于搜索的最后一个主题我们就来演示一下关于数据塑形 ...
- 2021 编程语言排行榜出炉!C#年度语言奖
IEEE Spectrum 发布了 2021 年度编程语言排行榜,其中 Python 在总榜单以及其他几个分榜单中依然牢牢占据第一名的位置.另外值得关注的是微软 C# 语言,它的排行从 2020 年的 ...
- Pytest_Hook函数pytest_addoption(parser):定义自己的命令行参数(14-1)
考虑场景: 我们的自动化用例需要支持在不同测试环境运行,有时候在dev环境运行,有时候在test环境运行: 有时候需要根据某个参数不同的参数值,执行不同的业务逻辑: 上面的场景我们都可以通过" ...
- CentOS 7 连接不到网络解决方法(设置静态ip)
使用VM12创建虚拟机并安装CentOS 7,但是安装完成后发现连接不到网络. ping jd.com发现不通 因为在创建虚拟机的时候 我们选择的是NAT模式 这里给出NAT模式下对应的的解决方法: ...
- CentOS 7 使用unzip解压zip文件提示未找到命令的解决方法
故障现象: 解决方法: 如果你使用unzip命令解压.zip文件,提示未找到命令,可能是你没有安装unzip软件,下面是安装方法 [root@localhost www]# yum install - ...