初识python 之 爬虫:爬取中国天气网数据
用到模块:
获取网页并解析:
import requests,html5lib
from bs4 import BeautifulSoup
使用pyecharts的Bar可视化工具“绘制图表”,写入HTML文件,附pyecharts官方中文API地址:https://pyecharts.org/#/
from pyecharts.charts import Bar
表格主题设置:
from pyecharts import options
from pyecharts.globals import ThemeType
获取时间
from datetime import datetime
详细代码如下: 注:代码中有使用到map函数,需要留意!
- 1 #!/user/bin env python
- 2 # author:Simple-Sir
- 3 # time:2019/7/25 21:16
- 4 # 爬取中国天气网数据
- 5
- 6 import requests,html5lib
- 7 from bs4 import BeautifulSoup
- 8 from pyecharts.charts import Bar # 官方已取消 pyecharts.Bar 方式导入
- 9 from pyecharts import options
- 10 from pyecharts.globals import ThemeType
- 11 from datetime import datetime
- 12
- 13 WEARTHER_DATE =[] # 城市天气数据列表
- 14
- 15 def urlText(url):
- 16 '''
- 17 获取网页HTML代码,并解析成文本格式
- 18 :param url: 网页url地址
- 19 :return: 解析之后的html文本
- 20 '''
- 21 headers = {
- 22 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
- 23 }
- 24 respons = requests.get(url, headers=headers) # 获取网页信息
- 25 text = respons.content.decode('utf-8') # 解析网页
- 26 return text
- 27
- 28 def getDiv(url,area):
- 29 '''
- 30 获取需要的html标签:城市、最高温度
- 31 :param url:
- 32 :param area: 区域:全国、全省(四川) 0:全国、其他任意值:全市
- 33 :return:
- 34 '''
- 35 text = urlText(url)
- 36 # soup = BeautifulSoup(text,'lxml') # 港澳台html中table标签解析错误
- 37 soup = BeautifulSoup(text, 'html5lib') # html5lib 容错性比lxml高
- 38 conMidtab = soup.find_all('div',class_="conMidtab")[1] # 获取“明天”的天气
- 39 if area == '四川':
- 40 # 获取四川所有城市天气
- 41 trs = conMidtab.find_all('tr')[2:]
- 42 for tr in trs:
- 43 tds = tr.find_all('td')
- 44 city_td = tds[0]
- 45 city = list(city_td.stripped_strings)[0] # 区县
- 46 temp_td = tds[-5] # 倒数第5个td标签
- 47 temp = list(temp_td.stripped_strings)[0] # 最高温度
- 48 print('正在获取 {} 的最高气温:{}'.format(city, temp))
- 49 WEARTHER_DATE.append({'城市': city, '最高温度': int(temp)})
- 50 else:
- 51 # 获取全国城市天气
- 52 tables = conMidtab.find_all('table')
- 53 for t in tables:
- 54 trs = t.find_all('tr')[2:]
- 55 for index, tr in enumerate(trs):
- 56 tds = tr.find_all('td')
- 57 if index == 0:
- 58 city_td = tds[1] # city_td = tds[-8] # 港澳台格式错误
- 59 else:
- 60 city_td = tds[0]
- 61 city = list(city_td.stripped_strings)[0] # 区县
- 62 temp_td = tds[-5] # 倒数第5个td标签
- 63 temp = list(temp_td.stripped_strings)[0] # 最高温度
- 64 print('正在获取 {} 的最高气温:{}'.format(city,temp))
- 65 WEARTHER_DATE.append({'城市': city, '最高温度': int(temp)})
- 66
- 67
- 68 # 可视化数据,对城市温度排名
- 69 # def getRownum(data):
- 70 # max_temp = data['最高温度'] # 把列表里的每一项当作参数传进来,再获取“最高温度”这一项的值
- 71 # return max_temp
- 72 # WEARTHER_DATE.sort(key=getRownum) # 功能和它一样:WEARTHER_DATE.sort(key=lambda data:data['最高温度'])
- 73
- 74 def main():
- 75 city_list =['hb','db','hd','hz','hn','xb','xn','gat','sichuan']
- 76 getcity = input('您要获取“全国”还是“四川”的最高温度排名?\n')
- 77 if getcity=='四川':
- 78 url = 'http://www.weather.com.cn/textFC/{}.shtml'.format(city_list[-1])
- 79 getDiv(url,getcity)
- 80 else:
- 81 for cl in city_list[:-1]:
- 82 url = 'http://www.weather.com.cn/textFC/{}.shtml'.format(cl)
- 83 getDiv(url,getcity)
- 84 print('正在对天气温度进行排序处理...')
- 85 WEARTHER_DATE.sort(key=lambda data: int(data['最高温度'])) # 对列表中的字典数据排序,温度从低到高
- 86 WEARTHER_DATE.reverse() # 把对列表反转,温度从高到低
- 87 rownum = WEARTHER_DATE[:10] # 获取最高温度排名前十的城市
- 88 print('正在绘制图表...')
- 89 # 分别获取城市、温度列表
- 90 # 原始方法:
- 91 # citys=[]
- 92 # temps=[]
- 93 # for i in rownum:
- 94 # citys.append(i['城市'])
- 95 # temps.append(i['最高温度'])
- 96
- 97 # 高端方法:
- 98 citys = list(map(lambda x: x['城市'], rownum)) # 使用map分离出城市
- 99 temps = list(map(lambda x: x['最高温度'], rownum)) # 使用map分离出最高温度
- 100 # 通过使用pyecharts的Bar可视化数据,附官方中文API地址:https://pyecharts.org/#/
- 101 bar = Bar(init_opts = options.InitOpts(theme=ThemeType.DARK)) # 对表格添加主题
- 102 bar.add_xaxis(citys)
- 103 bar.add_yaxis('',temps)
- 104 tim = datetime.now().strftime('%Y-%m-%d')
- 105 bar.set_global_opts(title_opts={'text':'中国天气网 {} 城市明日最高温度排名前十({})'.format(getcity,tim)})
- 106 bar.render('中国天气网城市最高温度排名.html')
- 107 print('图表绘制已完成,结果已写入文件,请查看。')
- 108 if __name__ == '__main__':
- 109 main()
爬取中国天气网数据
执行过程:
执行结果:
四川:
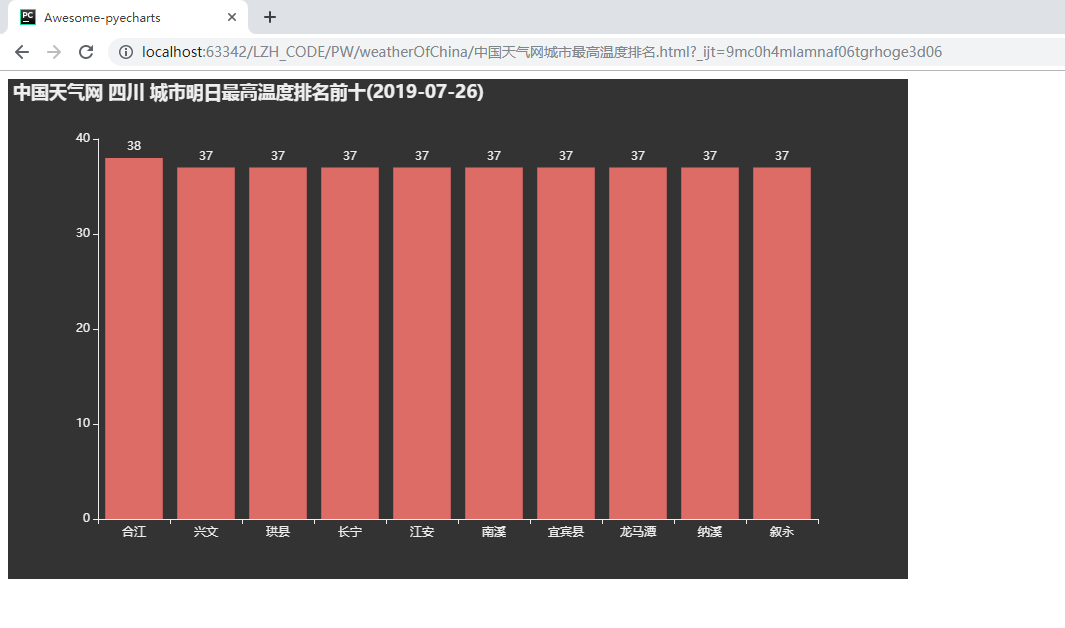
全国:

初识python 之 爬虫:爬取中国天气网数据的更多相关文章
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- scrapy实例:爬取中国天气网
1.创建项目 在你存放项目的目录下,按shift+鼠标右键打开命令行,输入命令创建项目: PS F:\ScrapyProject> scrapy startproject weather # w ...
- python爬取中国天气网站数据并对其进行数据可视化
网址:http://www.weather.com.cn/textFC/hb.shtml 解析:BeautifulSoup4 爬取所有城市的最低天气 对爬取的数据进行可视化处理 按温度对城市进行排 ...
- python实战项目 — 爬取中国票房网年度电影信息并保存在csv
import pandas as pd import requests from bs4 import BeautifulSoup import time def spider(url, header ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python3抓取中国天气网不同城市7天、15天实时数据
思路:1.根据city.txt文档来获取不同城市code2.获取中国天气网7d和15d不同城市url3.利用requests库请求url获取html内容4.利用beautifulsoup获取7d和15 ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
随机推荐
- 02_ubantu常用软件安装
软件更新-----------------------------------------------------------------进入系统后,什么也不要做,先去更新软件:如果网速慢的话,可以稍 ...
- Zookeeper客户端链接
一.zkCli.sh ./zkCli.sh -server 39.97.176.160:2182 39.97.176.160 : zookeeper服务器Ip 2182:zookeeper端口 二.Z ...
- 【Linux】【Web】【Nginx】配置nginx日志到远程syslog服务器
1. 概述: 主要是用于吧nginx的日志直接传送到远程日志收集的服务器上.远程日志服务器只要能够支持syslog协议都能够收到日志,本文的syslog服务器是IBM的日志收集系统Qradar. 2. ...
- 初步接触Linux命令
目录 虚拟机快照 1.首先将已经运行的系统关机 2.找到快照 拍摄快照 3.找到克隆 下一步 有几个快照会显示几个 4.克隆完成后 要修改一下IP 不然无法同时运行两个虚拟机系统 系统介绍 1.pin ...
- 【JavaWeb】【Eclipse】使用Eclipse创建我的第一个网页
使用Eclipse创建我的第一个网页 哔哩哔哩 萌狼蓝天 你可以直接点击Finish,也可以点击Next,到下面这个界面后,勾选生成web.xml然后Finish(你不这样做就会没有Web.xml文件 ...
- CPU的负载
目录 一.简介 二.合理的负载 一.简介 使用top或者uptime命令可以看到cpu平均负载,1,5,15分钟 平均负载包括以下几个部分: 正在运行的进程.正在使用cpu做计算的进程,ps看到R 也 ...
- shell脚本 系统状态信息查看
一.简介 源码地址 日期:2018/6/23 介绍:显示简单的系统信息 效果图: 二.使用 适用:centos6+,ubuntu12+ 语言:中文 注意:无 下载 wget https://raw.g ...
- centos源码部署lua-5.3
目录 一.介绍 二.部署 三.测试 一.介绍 Luat语言是在1993年由巴西一个大学研究小组发明,其设计目标是作为嵌入式程序移植到其他应用程序,它是由C语言实现的,虽然简单小巧但是功能强大. 二.部 ...
- Java后端高频知识点学习笔记1---Java基础
Java后端高频知识点学习笔记1---Java基础 参考地址:牛_客_网 https://www.nowcoder.com/discuss/819297 1.重载和重写的区别 重载:同一类中多个同名方 ...
- 用法总结:NSArray,NSSet,NSDictionary
用法总结:NSArray,NSSet,NSDictionary Foundation framework中用于收集cocoa对象(NSObject对象)的三种集合分别是: NSArray 用于对象有序 ...