注意,你所做的 A/B 实验,可能是错的!
对于 A/B 实验原理认知的缺失,致使许多企业在业务增长的道路上始终在操作一批“错误的 A/B 实验”。这些实验并不能指导产品的优化和迭代,甚至有可能与我们的初衷背道而驰,导致“负增长”。
在 A/B 实验不断走红的今天,越来越多的企业开始意识到 A/B 实验的重要意义,并试图通过 A/B 实验,前置性地量化决策收益,从而实现增长。然而,当你和其他业务伙伴谈及 A/B 实验时,你总能听到这样的论调:
“这事儿很简单,做个实验就行了。准备两个版本,在不同渠道里发版,然后看看数据。”
“把用户按照 did(device_id)尾号奇偶分流进实验组和对照组,然后看看数据表现。”
不可否认,这部分企业的确走在前沿,初步拥有了 A/B 实验的思维。然而令人遗憾的是,他们操作的所谓“A/B 实验”,其实并不具备 A/B 实验应有的功效。
更令人遗憾的是,他们似乎对此并不知晓。
对于 A/B 实验原理认知的缺失,致使许多企业在业务增长的道路上始终在操作一批“错误的 A/B 实验”。这些实验并不能指导产品的优化和迭代,甚至有可能与我们的初衷背道而驰,导致“负增长”。
因此,为了能够更好地明白什么是 A/B 实验,我们不妨先来了解几种错误的 A/B 实验。
No1:用户抽样不科学
典型表现
“用户抽样不科学”是错误 A/B 实验的第一宗罪。操作这种错误 A/B 实验的企业常采取以下做法:
实验中,在不同的渠道/应用市场中,发布不同版本的 APP/页面,并把用户数据进行对比;
简单地从总体流量中抽取 n%用于实验,不考虑流量分布,不做分流处理(例如:简单地从总体流量中任意取出 n%,按照 ID 尾号单双号把用户分成两组)。
错在哪儿
不同应用市场/渠道的用户常常带有自己的典型特征,用户分布具有明显区别。对总流量进行“简单粗暴”地抽样也有着同样的问题——分流到实验组和对照组的流量可能存在很大的分布差异。
实际上,A/B 实验要求我们,尽可能地保持实验组和对照组流量分布一致(与总体流量也需保持分布一致),否则得出的实验数据并不具有可信性。
为什么要保持分布一致呢?我们不妨来看一个问题:
某大学由两个学院组成。
1 号学院的男生录取率是 75%,女生录取率 49%,男生录取率高于女生;
2 号学院男生录取率 10%,女生录取率 5%,男生录取率同样高于女生。问:综合两个学院来看,这所大学的总体录取率是否男生高于女生?
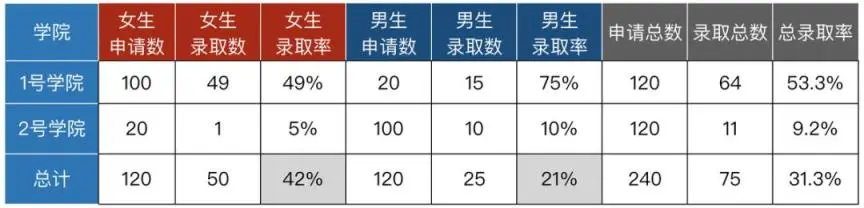
直觉上来说,许多人会觉得,男生录取率总体上会高于女生。然而事实并不是这样,让我们来看看实际数字:
从上表可以看出,尽管两个学院男生录取率都高于女生,但综合考虑两个学院的情况时,男生的总体录取率却要低于女生。这种现象在统计学中被称为辛普森悖论。
辛普森悖论由英国统计学家 E.H 辛普森于 1951 年提出。其主要内容是:几组不同的数据中均存在一种趋势,但当这些数据组合在一起后,这种趋势消失或反转。其产生的原因主要是数据中存在多个变量。这些变量通常难以识别,被称为“潜伏变量”。潜伏变量可能是由于采样错误造成的。
在 A/B 实验中,如果实验组和对照组的样本流量分布不一致,就可能产生辛普森悖论,得到不可靠的实验结果。
分流是 A/B 实验成功与否的关键点,在早期企业还不具备过硬研发能力情况下,想要真正做对 A/B 实验,最佳方法是借助第三方实验工具中成熟的分流服务。
火山引擎 A/B 测试长期服务于抖音、今日头条等头部互联网产品,分流服务科学可靠,并且能够支撑亿级 DAU 产品进行 Push 实验,在高并发场景下保持稳定,帮助我们从总体流量中更加均匀地分流样本,使实验更科学。
No2:互斥层选择错误
典型表现
接入了实验工具,A/B 实验就能做对了吗?也不尽然。许多实验者在进行实验操作时,将有关联性的实验放置在不同的实验互斥层上,导致实验结果不可信。
何谓“互斥层”?在火山引擎 A/B 测试中,“互斥层”技术是为了让多个实验能够并行,不相互干扰,且都获得足够的流量而研发的流量分层技术。
假设我现在有 4 个实验要进行,每一个实验要取用 30%的流量才能够得出可信的实验结果。此时为了同时运行这 4 个实验就需要 4*30%=120%的流量,这意味着 100%的流量不够同时分配给这 4 个实验。那么此时我只能选择给实验排序,让几个实验先后完成。但这会造成实验效率低下。试想一下,抖音每天有上千个实验要进行,如果只能排队挨号,抖音的实验 schedule 恐怕要排个 10 年。
那么有没有办法可以解决这个问题呢?
有,就是使用互斥层技术,把总体流量“复制”无数遍,形成无数个互斥层,让总体流量可以被无数次复用,从而提高实验效率。
各互斥层之间的流量是正交的,你可以简单理解为:在互斥层选择正确的前提下,流量经过科学的分配,可保证各实验的结果不会受到其他互斥层的干扰。
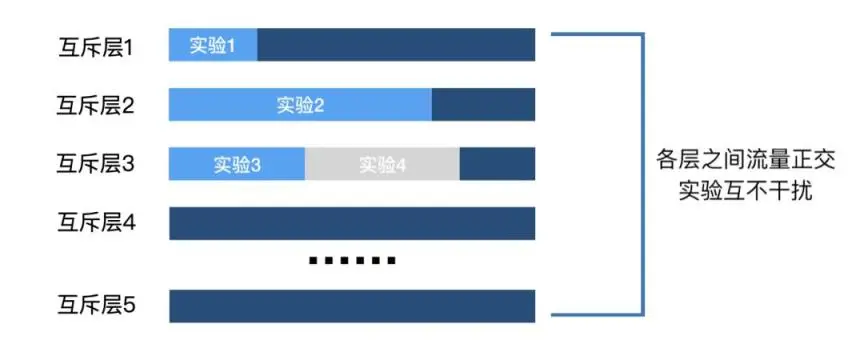
在选择互斥层的时候,实验者应当要遵循的规则是:假如实验之间有相关性,那么实验必须置于同一互斥层;假如实验之间没有相关性,那么实验可以置于不同互斥层。如果不遵循这一原则,那么 A/B 实验就会出问题。
错在哪儿
那么,问题究竟是出在了哪儿呢?
对于实验需求旺盛的企业来说,互斥层技术完美解决了多个实验并行时流量不够用的问题。然而,乱选互斥层会导致实验结果不可信。为什么?举个例子,现在我们想对购买页面的购买按钮进行实验。
我们作出两个假设:
假设 1:将购买按钮的颜色从蓝色改为红色,用户购买率可以提高 3%;
假设 2:将购买按钮的形状从方形改为圆形,用户购买率可以提高 1.5%。
针对上述两个假设,我们需要开设两个实验:一个针对按钮颜色,一个针对按钮形状。两个实验均与购买按钮有关系,具有明显的关联性。这两组实验是否可以放在不同互斥层上呢?
**情况 1:相关实验置于不同层 **
如下图,我们把两个实验分别放置在两层上,同时开启两个实验。此时用户 A 打开了我们的购买页面,进入到总体流量之中。在互斥层 1 里,用户被测试按钮颜色的实验命中,进入实验组 Red;在互斥层 2 里,用户被测试按钮形状的实验命中,进入实验组 Round。
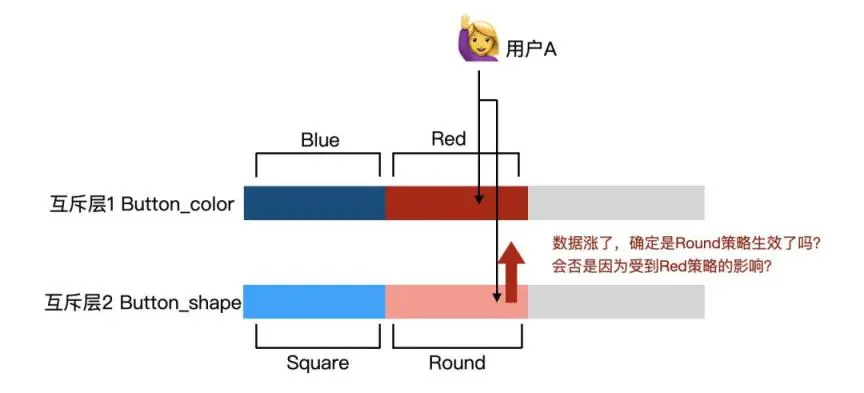
由图可知,用户 A 将受到“按钮颜色 Red”以及“按钮形状 Round”两个策略影响,我们无法判断究竟是哪个策略影响了该用户的行为。换句话说,由于两个实验存在关联,用户重复被实验命中,实验结果实际受到了多个策略的影响。这种情况下,两个实验的结果便不再可信了。
**情况 2:相关实验置于同一层 **
换个思路,如果将上面的两个实验放置在同一层上,那么用户在进入实验后便只会被一个实验命中。两个实验组均只受到一个策略影响,实验结果可信。

企业在进行 A/B 实验时,工具是基础设施,在实际业务,我们还需要结合具体的实验场景,进行正确的实验设计。
No3:不考虑是否显著
典型表现
实验结束后,只简单地观测实验数据的涨跌,不考虑实验结果是否显著。
错在哪儿
“显著”是一个统计学用词,为什么我们需要在评估实验结果时引入统计学呢?
我们已经知道,A/B 实验是一种小流量实验,我们需要从总体流量中抽取一定量的样本来验证新策略是否有效。然而抽样过程中,样本并不能完全代表整体,虽然我们竭尽全力地进行随机抽样,但最终仍无法避免样本和总体之间的差异。
了解了这一前提我们就能明白,在 A/B 实验中,如果只对数据进行简单的计算,我们对于实验结果的判断很可能会“出错”(毕竟我们通过实验观测得到的是样本数据,而不是整体数据)。
那么,有什么办法去量化样本与总体之间的差异对数据指标造成的影响呢?这就需要结合统计学的方法,在评估实验结果时加入相应的统计学指标,如置信度、置信区间、统计功效等。
原则上,如果实验结果不显著(或说不置信),我们便不能判断数据的涨/跌,是否是由实验中采取的策略造成的(可能由抽样误差造成),我们也不能盲目地全量发布新策略/否定新策略。
A/B 实验中的统计学原理是一个较为庞大复杂的课题,介于篇幅,我们在此暂不做展开解释。对这部分内容感兴趣的读者也可持续关注「字节跳动数据平台」,我们在后期会推出相应内容来为大家进行讲解。需要明确的一点是:评估 A/B 实验,绝不仅仅是比较下实验组和对照组的数据高低这么简单。
在实验结果评估方面,好的实验平台需要具备两个特点:第一是可靠的统计策略,第二是清晰、完善的实验报告。相较于市面上其他实验工具,这两个特点正是火山引擎 A/B 测试的优势所在。
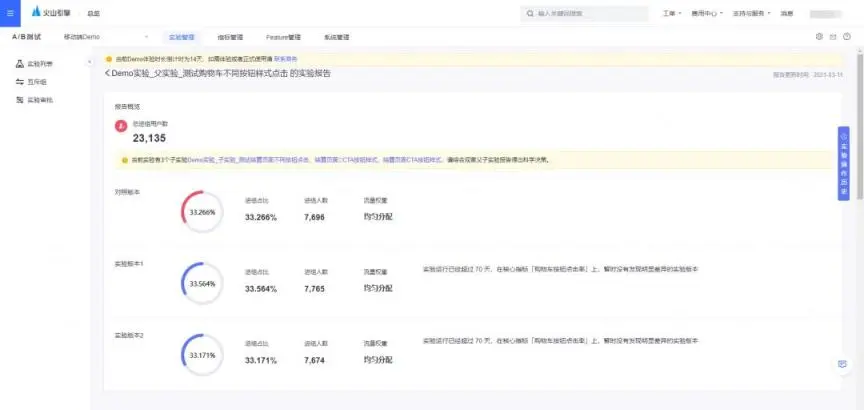
在统计策略方面,火山引擎 A/B 测试的统计策略长期服务于抖音、今日头条等产品,历经打磨,科学可靠;在实验报告方面,从概览至指标详情,火山引擎 A/B 测试依托于经典统计学的假设检验方法,结合置信度、置信区间,帮助实验者全方位的判断实验策略收益。
作为互联网公司的新宠,A/B 实验确有其独到之处,但浅显的实验认知、错误的实验方法,可能会致使企业在增长的道路上“反向前行”。此处让我们借用一句经典的影视台词吧:“发生这种事,大家都不想的。”
事实上,本文中所提及的“错误的 A/B 实验”,只是最浅显的 3 种,在产品增长的道路上,潜伏在一旁埋伏着实验者的“大坑”还有很多,我们也会陆续教给大家如何“避坑”。
关联产品
火山引擎 a/b 测试
摆脱猜测,用科学的实验衡量决策收益打造更好的产品,让业务的每一步都通往增长。
欢迎关注字节跳动数据平台同名公众号
注意,你所做的 A/B 实验,可能是错的!的更多相关文章
- ubuntu下做柯老师lab19-lab20实验问题总结
前两篇文章告诉了大家如何将无线封包传输遗失模型和myevalvid添加到ns2.35中,已经成功验证了,这个没有问题.但是本人在做lab19和lab20实验时又发现了一些关于myevalvid工具集的 ...
- 你要相信你所做的一切对一个更美好的世界 Do have faith in what you are doing All for a better world
http://www.nowamagic.net/librarys/veda/detail/2502 Do have faith in what you are doing. 先不要往下看,试试品尝上 ...
- SAP 对HU做转库操作,系统报错 - 系统状态HUAS是活动的 - 分析
SAP 对HU做转库操作,系统报错 - 系统状态HUAS是活动的 - 分析 近日收到业务团队报的问题,说是对某个HU做转库时候,系统报错.如下图示: HU里有是三个序列号, 1191111034011 ...
- trove命令翻译(上)(只做翻译,未实验效果)
The trove client is the command-line interface (CLI) for the Database service API and its extensions ...
- 系统可能不会保存你所做的修改 onbeforeunload
网上找了好多实现这个的方法,说的还是不明白.害得我(我自己的原因)以为是需要在服务器环境下才能跑通 window.onbeforeunload; 后来猜想是不是函数返回值发生变化就会触发. <! ...
- 在做nios ii uart232 实验时出现undefined reference to `fclose'等错误。
程序如下 #include<stdio.h> #include<string.h> #include "system.h" int main () { ...
- docker的安装,自己写了一个安装docker的脚本,辅助做docker安装的实验(ubuntu)
#!/bin/bash #获取用户名 [ pwd == '/root' ] && hn="root@$(hostname):~#" || hn="root ...
- Vue 给axios做个靠谱的封装(报错,鉴权,跳转,拦截,提示)
需求及实现 统一捕获接口报错 弹窗提示 报错重定向 基础鉴权 表单序列化 用法及封装 用法 // 服务层 , import默认会找该目录下index.js的文件,这个可能有小伙伴不知道可以去了解npm ...
- 新安装个Myeclipse,导入以前做的程序后程序里好多错,提示The import java.util cannot be resolved
原因:这是由于你的项目buildpath不对原来的项目,比如采用了原先的MyEclipse自带的jdk (D:\myeclipse\XXXXXX)结果,你现在换了一个,原来的没了就导致了现在这种错误, ...
随机推荐
- Linux实体服务器添加网卡
目录 一.简介 二.配置 三.添加网卡 四.总结 一.简介 服务器如果搭配了网口,在插入网线或者光纤后会亮灯.如果发现不亮,可以关闭机器查看亮不亮,因为有的时候系统会把网口禁用,进入到系统反而不亮了, ...
- python函数概念
函数介绍 函数就类似与一个工具,作用就是在有需求时可以直接使用. 函数作用 1.精简代码,不需要重复写代码. 2.提高代码兼容性 3.提供返回值 函数语法结构 def 函数名(参数1, 参数2): & ...
- linux小应用 —— 日志过滤
先说问题,统计一个日志文件中去重之后的ip地址的个数.其实这是一个非常常见也比较简单的问题,其中我个人认为最主要的应该是匹配ip地址是这个问题的核心.剩下的就是对linux命令的熟练程度的问题了.首先 ...
- CF616B Dinner with Emma 题解
Content 翻译很明白,或者你也可以看我的简化版题意: 求一个 \(n\times m\) 的矩阵中每行的最小值的最大值. 数据范围:\(1\leqslant n,m\leqslant 100\) ...
- WebApi的前端调用
WebApi前端调用 HTML代码: <!DOCTYPE html><html> <head> <meta charset="utf-8" ...
- href超级链接里加上javascript代码的,还有target问题
href超级链接里加上javascript代码的,还有target问题 得把target="_blank"去掉才好用,在google浏览器有这个也没事,但是在Ie里有这个就不行了
- 遇到奇葩的现象,给input的id为10的value属性赋值为6,但是怎么显示的时候值还是原先的9的
遇到奇葩的现象,给input的id为10的value属性赋值为6,但是怎么显示的时候值还是原先的9的 后来发现原来是id标签重复了,所有以后得注意了. 人员信息input的id属性与隐藏input属性 ...
- Linux(centos)系统导出数据库文件命令
mysqldump -uroot -p test > /test.sql -uroot 其中的root是数据库的用户名 test是要导出的数据库名字 test.sql 是要导出的数据库文件名字, ...
- 【九度OJ】题目1185:特殊排序 解题报告
[九度OJ]题目1185:特殊排序 解题报告 标签(空格分隔): 九度OJ [LeetCode] http://ac.jobdu.com/problem.php?pid=1185 题目描述: 输入一系 ...
- 【LeetCode】229. Majority Element II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 hashmap统计次数 摩尔投票法 Moore Vo ...