SCRDet——对小物体和旋转物体更具鲁棒性的模型
引言
明确提出了三个航拍图像领域内面对的挑战:
- 小物体:航拍图像经常包含很多复杂场景下的小物体。
- 密集:如交通工具和轮船类,在航拍图像中会很密集。这个DOTA数据集的发明者也提到在交通工具和轮船类的检测中,模型的检测效果很差
- 任意方向角:航拍图像中的物体通常有多种多样的朝向。遥感中普遍存在的大宽高比问题进一步对其提出了挑战。
Faster R-CNN是在此领域内大家常用的两阶段目标检测模型,但是它更加适用于水平bbox的目标检测。而作为后处理模块的NMS也抑制了密集分布的任意朝向的物体的检测。
paper中提出的SCRDet模型,包含以下三个主要改进部分:
- 对于小物体检测的问题,提出了SF-Net进行特征融合和anchor采样
- 对于背景噪声多的问题,提出了MDA-Net去抑制噪声和加强前景
- 对于任意方向角的密集检测问题,通过增加一个与角度有关的参数来建立一个角度敏感的网络模块
模型介绍
SCRDet模型的基本结构如下图所示,paper中将其称为一个两阶段的方法,其中第一阶段使用SF-Net和MDA-Net提取出包含更多特征信息和更少噪声的特征图,但这个阶段回归的还是水平框。在第二阶段使用R-NMS方法回归出斜框,最终完成斜框预测的任务。

采样和特征融合网络(SF-Net)
作者认为在小物体检测中的两大障碍为:物体的特征信息不充分以及anchor的采样不够充分。由于小物体在深层网络中更容易丢失自己的特征信息,所以在池化层中会将小物体的特征信息丢失掉很多。且采样步长过大也会导致在采样时跳过很多小物体,导致不充分的采样。
首先是特征融合,由于低层次的特征图能够保留更多小物体的特征,所以基于以上特点有FPN、TDM、RON等特征融合的方法可以使用。
其次是anchor采样,当使用更小采样步长的时候,经过实验证明可以取得更好的EMO score(expected max overlapping score)。如下图所示,使用\(S_A = 8\)的步长能够更好的检测出小物体。
基于以上两个分析,提出SF-Net的模型结构如下图所示。

其中,通过三个尺寸的采样得到三个不同的特征图,SF-Net仅仅使用C3和C4的特征图信息,将两者合并以平衡语义信息和位置信息的比例,其中C4特征图还经过一个Inception模块来扩大它的接受范围和增加它的语义信息。最终得到一个F3特征图,其\(S_A\)是期望的anchor步长
根据步长的变化,模型在DOTA数据集上的表现如下所示。可以看出最终特征图的步长越小,mAP的值越高,训练时长也越长。

多维注意力网络(MDA-Net)
由于真实世界的数据的复杂性,使用原本的方法选出来的候选区域可能包含了很多的噪声信息。如下图所示,这种噪声信息很大程度上模糊了候选区域的边界。
处理噪声问题的传统方法都是采用非监督的算法进行的,这种算法的效率不高。在SCRDet模型中,作者设计了一个多维注意力网络MDA-Net。结构如下图所示:
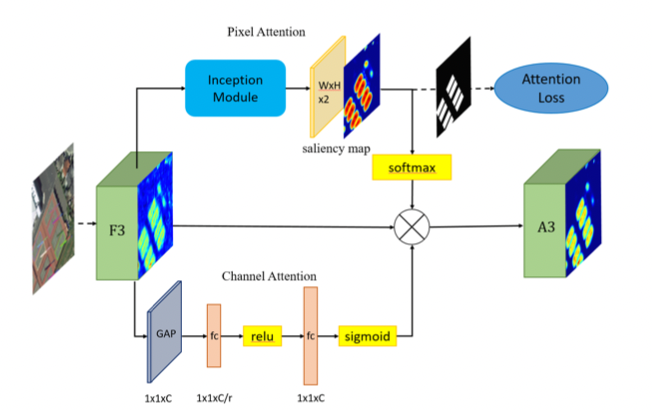
在基于像素的注意网络中,特征图F3通过具有不同大小卷积核进行卷积运算,学习得到双通道的显著图。这个显著图显示了前景和背景的分数。选择显著图中的一个通道与F3相乘,得到新的信息特征图A3。需要注意的是,Softmax函数之后的显着图的值在[0,1]之间。换句话说,它可以降低噪声并相对的增强对象信息。由于显著图是连续的,因此不会完全消除背景信息,这有利于保留某些上下文信息并提高鲁棒性。
表示方法
论文中采用了另一种五元组表示斜框的方法\((x, y, w, h, \theta)\)。其中\((x,y)\)表示斜框中心点的坐标。\(w\)和\(h\)表示斜框矩形的长宽,\(\theta\)表示斜框的倾斜角度。
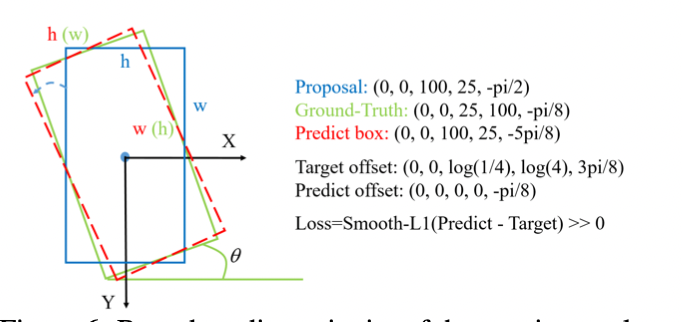
则回归的计算方式如下:
\[t_x = (x-x_a)/w_a, t_y = (y-y_a)/h_a \\
t_w = log(w/w_a), t_h = log(h/h_a), t_{\theta} = \theta - \theta_{a}
\]其中最终的预测结果是由R-NMS过程的proposal得到的,将proposal的结果进行顺时针旋转后,再进行长宽调整,得到最终的predict box。我们通过上述式子得到预测框和真实框的两个回归结果,下一步将它们的结果放入损失函数中计算损失。
损失函数
如上图所示,如果我们要将proposal,即蓝色框回归到预测的位置(红色框)上,最简单的方法就是将其逆时针旋转。但是这种方法的回归损失非常大(由于我们设定的是顺时针旋转,此时按照单一旋转的方法回归到红色框就会使角度变化很大)。此时我们可以采用另一种思路,即将蓝色框回归到下图灰色框的位置,然后调整灰色框的长和宽。
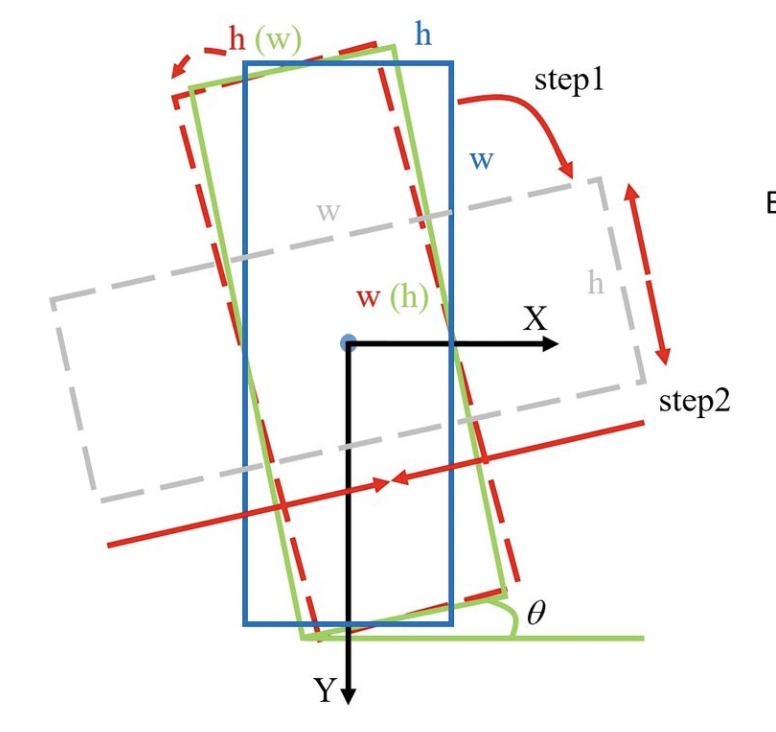
这种损失会使得计算更加麻烦,为了更好地解决这个问题,作者在传统的smooth L1 损失函数中引入了IoU常数因子。整体的损失函数表达如下所示:
\[Loss = \frac{\lambda_1}{N}\sum_{n=1}^{N}t^{'}_n\sum_{j\in (x,y,w,h,\theta) }\frac{L_{reg}(v^{'}_{nj}, v_{nj})}{|L_{reg}(v^{'}_{nj}, v_{nj})|} * |- log(IoU)| \\
+\frac{\lambda_2}{h \times w}\sum_i^h\sum_j^wL_{att}(u^{'}_{ij}, u_{ij}) + \frac{\lambda_3}{N}\sum_{n=1}^NL_{cls}(p_n,t_n)
\]其中,\(\lambda\)参数使用来调整各部分损失比例大小的。\(N\)代表了proposal的数量,\(t^{'}_n\)是一个二进制值(当其为1是表示前景,为0是表示背景)。v向量表示了斜框用\((x,y,w,h,\theta)\)五元组表示方法表示出来的向量,u向量表示了预测结果和真实结果之间的像素相关性。IoU表示了预测框和真实框之间的重合。
三个回归函数分别为:\(L_{reg}\)为位置损失,使用smooth L1损失、\(L_{att}\)为注意力损失,使用交叉熵损失、\(L_{cls}\)为分类损失,使用softmax损失。
关于IoU的进一步解释:由于IoU表示了预测框和真实框之间的相近程度,那么它自然满足一个属性:当预测框和真实框之间越相近时,它的值越接近于1。这样就可以用一个恒为正的值\(\log(IoU)\)来控制当前的梯度大小问题。我们可以将\(\frac{L_{reg}}{|L_{reg}|}\)看做一部分,它代表了当前梯度下降最快的方向向量,而把\(-log(IoU)\)看做控制梯度大小的一个变量,这样使得损失函数更加连续。
下面是使用两种loss函数的结果对比。可以看出使用IoU-smooth L1 loss的模型预测的结果更加好。

导致(a)这种结果的根本原因是角度的预测超出了所定义范围。其实解决这种问题的方法并不唯一,RRPN和R_DFPN在论文的loss公式中就判断了是不是在定义范围内,通过加减\(k\pi\)来缓解这个问题,但这种做法明显不优美而且仍然存在问题,主要是较难判断超出预测范围几个角度周期。当然可以通过对角度部分的loss加一个周期性函数,比如\(tan\)、\(cos\)等三角函数来做,但实际使用过程中常常出现不收敛的情况。
总结
- MDA-Net:作用体现在对去噪的效果以及特征的提取上
- SF-Net:作用体现在对小物体的检测上
- IoU-smooth L1 loss:作用体现在回归时消除边界影响
- image pyramid:作者在论文中并没有详细说明这一方法,其实就是将图像似金字塔般resize成多种形状传入模型中进行学习,这样也是一个提高性能的好方式。
SCRDet——对小物体和旋转物体更具鲁棒性的模型的更多相关文章
- 【three.js第三课】鼠标事件,移动、旋转物体
1.下载three.js的源码包后,文件夹结构如下: 2.在[three.js第一课]的代码基础上,引入OrbitControls.js文件,此文件主要用于 对鼠标的操作. 该文件位置:在文件结构中 ...
- Threejs【坐标转换】如何让annotation跟随物体一起旋转
现在根据鼠标点击的屏幕位置能够得到屏幕的坐标event.clientX和event.clientY,然后我的annotation就初始化在这个屏幕坐标的位置,那么如何绑定annotation和三维物体 ...
- (转)使用Python和OpenCV检测图像中的物体并将物体裁剪下来
原文链接:https://blog.csdn.net/liqiancao/article/details/55670749 介绍 硕士阶段的毕设是关于昆虫图像分类的,代码写到一半,上周五导师又给我新的 ...
- Unity查找物体的子物体、孙物体
Unity查找物体下的所有物体 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分 ...
- 微信小程序(7)--微信小程序连续旋转动画
微信小程序连续旋转动画 https://mp.weixin.qq.com/debug/wxadoc/dev/api/api-animation.html <view animation=&quo ...
- javascript学习-原生javascript的小特效(多物体运动效果)
前些日子看了个视频所以就模仿它的技术来为大家做出几个简单的JS小特效 今天为大家做的是多个物体的运动效果, 1:HTML <body> <ul> <li> ...
- AR Engine光照估计能力,让虚拟物体在现实世界更具真实感
AR是一项现实增强技术,即在视觉层面上实现虚拟物体和现实世界的深度融合,打造沉浸式AR交互体验.而想要增强虚拟物体与现实世界的融合效果,光照估计则是关键能力之一. 人们所看到的世界外观,都是由光和物质 ...
- UGUI_创建旋转物体,使用Slider控制小球旋转速度
using System.Collections; using System.Collections.Generic; using UnityEngine; public class Player : ...
- 【three.js练习程序】旋转物体自身
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
随机推荐
- Linux多线程编程之详细分析
线程?为什么有了进程还需要线程呢,他们有什么区别?使用线程有什么优势呢?还有多线程编程的一些细节问题,如线程之间怎样同步.互斥,这些东西将在本文中介绍.我见到这样一道面试题: 是否熟悉POSIX多线程 ...
- Django(71)图片处理器django-imagekit
介绍 ImageKit是用于处理图像的Django应用程序.如果需要从原图上生成一个长宽为50x50的图像,则需要ImageKit. ImageKit附带了一系列图像处理器,用于调整大小和裁剪等常见任 ...
- Springboot第一次访问慢,自身缺陷问题?
一.现象: 1.访问controller,第一次速度在300-400ms,第二次访问就很快了大概在20ms,相差几十倍,是哪里出了问题,尝试了网上很多教程都没有作用 如启动参数设置 -Djava.se ...
- Python 检查当前运行的python版本 python2 python3
检查当前运行的python版本,可以帮助程序选择运行python2还是python3的代码 import sys if sys.version > '3': PY3 = True else: P ...
- 电路维修(双端队列 & 最短路)
达达是来自异世界的魔女,她在漫无目的地四处漂流的时候,遇到了善良的少女翰翰,从而被收留在地球上. 翰翰的家里有一辆飞行车. 有一天飞行车的电路板突然出现了故障,导致无法启动. 电路板的整体结构是一个$ ...
- win10各版本激活码
win + x进入Power shell(管理员),依次输入 Win10专业版 slmgr.vbs /upk slmgr /ipk W269N-WFGWX-YVC9B-4J6C9-T83GX slmg ...
- win10 vscode安装babel
第一步:安装 babel-cli cd进入项目根目录,执行命令: npm install --global babel-cli 第二步:检测第一步是否成功,输入命令 babel --version,若 ...
- PTA 7-7 六度空间 (30分)
PTA 7-7 六度空间 (30分) "六度空间"理论又称作"六度分隔(Six Degrees of Separation)"理论.这个理论可以通俗地阐述为:& ...
- CentOS8安装VNC-Server,并使用VNC Viewer连接
1.查看系统信息 # 查看red-hat版本信息 cat /etc/redhat-release CentOS Linux release 8.0.1905 (Core) 2.安装VNC Server ...
- 史上最全的Excel导入导出之easyexcel
喝水不忘挖井人,感谢阿里巴巴项目组提供了easyexcel工具类,github地址:https://github.com/alibaba/easyexcel 文章目录 环境搭建 读取excel文件 小 ...