MySQL优化之路
一、Mysql的存储原理
索引相关
本质
索引是帮助MySQL高效获取数据的排好序的数据结构
建索引,提高数据检索的效率,降低数据库的IO成本; 通过索引列对数据进行排序,降低数据排序的成本,降低了 CPU的消耗。
索引分类
- 主键索引:主键自带索引效果,性能很好
- 普通索引:为普通列创建的索引
-- 格式
create index 索引名称 on 表名(列名);
-- 示例
create index idx_name on user(name);
- 唯一索引 : 索引列的值必须唯一,但允许有空值。比普通索引的性能要好
-- 格式
create unique index 索引名称 on 表名(列名);
-- 示例
create unique index uniq_name on user(name);
联合索引 ( 开发常用 ) :一次性的为表中的多个列创建索引 (建议一个联合索引不超过5个字段)
(最左前缀法则:如何命中联合索引中的索引列)
-- 格式
create index 索引名称 on 表名(列名1,列名2);
-- 示例
create index idx_name_age_password on user(name,age,password);
全文索引:进行查询时,数据源可能来自不同的字段或者表
MyISAM存储引擎支持全文索引,在实际开发中并不会去使用而是使用搜索引擎中间件
总结
-- 创建索引
create [unique] index 索引名称 on 表名(列名)
-- 删除索引
drop index [索引名称] on 表名
-- 查看索引
show index from 表名\G
为数据表添加索引

索引的数据结构
- 二叉树 (链表情况)
- 红黑树 (层次太多)
- Hash表
- 对索引的key进行一次hash计算就可以定位出数据存储的位置
- 很多时候Hash索引要比B+树索引更高效
- 仅能满足“=”,“IN”,不支持范围查询
- hash冲突问题
- B Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
- B+Tree (底层)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能

推荐一个外国的数据结构在线演示网站: Data Structure Visualization
INNODB与 MYISAM类型的区别
1、INNODB引擎----聚集索引
把索引和数据存放在一个文件中,通过找到索引后就能直接在索引树上的叶子结点中获得完整的数据。可以实现行锁/表锁
2、MYISAM----非聚集索引
把索引和数据存放在两个文件中,查找到索引后还要去另一个文件中找数据,性能会慢一些。除此之外,MylSAM天然支持表锁,而且支持全文索引。
创建索引的情况
- 需要创建索引的情况:
1、主键自动建立唯一索引
2、频繁作为查询条件的字段应该创建索引
3、查询中与其他表关联的字段,外键关系建立索引
4、单键/组合索引的选择问题 ?( 在高并发下倾向创建组合索引 )
5、查询中排序的字段,排序字段通过索引去访问将大大提高排序速度
6、查询中统计或分组字段
- 不需要创建索引的情况:
1、频繁更新的字段不适合创建索引
2、经常增删改的表
3、where条件里用不到的字段不创建索引
4、表记录太少
5、如果某个数据列包含许多重复的内容,为他建立索引没有太大的效果
Tip: 一个索引的选择性越接近1,这个索引的效率就越高!
联合索引
使用一个索引来实现多个表中字段的索引效果。
存储方式:

索引最左前缀原理
最左前缀法则是表示一条sql语句在联合索引中有没有走索引(命中索引/不会全表扫描)
联合索引的底层存储结构长什么样?

慢sql原因
- 查询语句写的不好
- 索引失效
- 关联过多的 join (设计缺陷或不得已的需求)
- 服务器调优以及参数设置
二、Mysql性能查询

SQL优化的目的是为了SQL语句能够具备优秀的查询性能,实现这样的目的有很多的途径:
- 工程优化如何实现︰数据库标准、表的结构标准、字段的标准、创建索引 阿里:MySQL数据库规范
- SQL语句的优化:当前SQL语句有没有命中索引。
explain
简介
使用EXPLAIN关键字可以模拟优化器执行sQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
详解
作用
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
使用格式:explain + sql语句
信息
详解
id列 :id越大越先被执行,如果id相同,上面的先执行
select_type列
| 类型 | 描述 |
|---|---|
| simple | 简单查询 |
| primary | 外部的主查询 |
| devived | 在from后面的子查询, 产生衍生表 |
| subquery | 在from的前面的子查询 |
| union | 进行的联合查询 |
关闭对mysql对衍生表的合并优化(演示)
set session optimizer_switch = 'derived_merge=off';
table列 :表示这一列表示该sql正在访问哪一张表。也可以看出正在访问的衍生表
type列
type列可以直观的判断出当前的sql语句的性能。type里的取值和性能的优劣顺序如下:
null > system > const > eq_ref > range > index > all
-- null
性能最好的,一般在使用了聚合函数操作索引列,结果直接从索引树获取即可
-- system
很少见 直接和一条记录进行匹配
-- const
使用主键索引或者唯一索引和常量进行比较,性能也很好
-- eq_ref
在进行连接查询时,连接查询的条件中使用了本表的主键进行关联
-- ref
-- 简单查询
使用普通列作为查询条件
-- 复杂查询
在进行连接查询时,连接查询的条件中使用了本表的普通索引列
-- range
在索引列上使用了范围查找,性能是ok的
-- index
在查询表中的所有的记录,但是所有的记录可以直接从索引树上获取,(表中字段均加索引)
-- ALL
全表扫描。就是要从头到尾对表中的数据扫描一遍。这种查询性能是一定要做优化的。
possible_keys列
显示这一次查询可能会用到的索引。mysql优化器查询时会进行判断,那么内部优化器就会让此次查询进行全表扫描————我们可以通过trace工具进行查看
key列 :实际该sql语句使用的索引
rows列 : 该sql语句可能要查询的数据条数
key_len列
通过查看这一列的数值,推断出本sql命中了联合索引中的哪几列。 key_len的计算规则

extra列
extra列提供了额外的信息,是能够帮助我们判断当前sql的是否使用了覆盖索引、文件排序、使用了索引进行查询条件等等的信息。
-- unsing index
使用了覆盖索引 (指的是当前查询的所有数据字段都是索引列,这就意味着可以直接从索引列中获取数据,而不需要进行查表。使用覆盖索引进行性能优化这种手段是之后sql优化经常要用到的。)
-- using where
where的条件没有使用索引列。这种性能是不ok的,我们如果条件允许可以给列设置索引,也同样尽可能的使用覆盖索引。
-- using index condition
查询的列没有完全被索引覆盖,并且where条件中使用普通索引
-- using temporary
会创建临时表来执行,比如在没有索引的列上执行去重操作,就需要临时表来实现。(这种情况可以通过给列加索引进行优化。)
-- using filesort
MySQL对数据进行排序,都会使用磁盘骧完成,可能会借助内存,涉及到两个概念︰单路排序、双路排序
-- Select tables optimized away
当直接在索引列上使用聚合函数,意味着不需要操作表
三、mysql优化细节
索引优化建议
命中索引建议:
对于SQL优化来说,要尽量保证type列的值是属于range及以上级别。
不能在索引列上做计算、函数、类型转换,会导致索引失效
对于日期时间的处理 转换成范围查找
尽量使用覆盖索引
使用不等于(!=或者<>)会导致全表扫描
使用is null、 is not null会导致全表扫描
使用like以通配符开头('%xxx...")会导致全表扫描 (使用覆盖索引或者搜索引擎中间件)
字符串不加单引号会导致全表扫描
少用or或in,MySQL内部优化器可能不使用索引 (使用多线程或者搜索引擎中间件)
范围查询优化 (范围大的拆分查找)
Trace工具
在执行计划中我们发现有的sql会走索引,有的sql即使明确使用了索引也不会走索引。mysql依据Trace工具的结论
-- 开启trace 设置格式为JSON,设置trace的缓存大小,避免因为容量大小而不能显示完整的跟踪过程。
set optimier_trace="enabled=on",end_markers_in_JSON=on;
-- 执行sql语句
-- 获得trace分析结果
select *from information_schema.optimizer_trace \G
Order by优化
在Order by中,如果排序会造成文件排序(在磁盘中完成排序,这样的性能会比较差),那么就说明sql没有命中索引,怎么解决? 可以使用最左前缀法则,让排序遵循最左前缀法则,避免文件排序。
优化手段:
- 如果排序的字段创建了联合索引,那么尽量在业务不冲突的情况下,遵循最左前缀法则来写排序语句。
- 如果文件排序没办法避免,那么尽量想办法使用覆盖索引。all->index
对于Group by而言 :本质上是先排序后分组,所以排序优化参考order by优化。
分页查询优化
-- 原始
Explain select * from employees limit 10000,10
-- 对于主键连续的情况下进行优化:(少见)
Explain select * from employees where id>10000 limit 10
-- 通过先进行覆盖索引的查找,然后在使用join做连接查询获取所有数据。这样比全表扫描要快
EXPLAIN select * from employees a inner join (select id from employees order by name limit 1000000,10) b on a.id = b.id;
join查询优化

in、exstis优化
在sql中如果A表是大表,B表是小表,那么使用in会更加合适。反之应该使用exists。
count优化
对于count的优化应该是架构层面的优化,因为count的统计是在一个产品会经常出现,而且每个用户访问,所以对于访问频率过高的数据建议维护在缓存中。
四、mysql的锁机制
锁的定义与分类
定义
锁是用来解决多个任务(线程、进程)在并发访问同一共享资源时带来的数据安全问题。虽然使用锁解决了数据安全问题,但是会带来性能的影响,频繁使用锁的程序的性能是必然很差的。
对于数据管理软件MySQL来说,必然会到任务的并发访问。那么MySQL是怎么样在数据安全和性能上做权衡的呢?——MVCC设计思想。
分类
从性能上划分:
- 悲观锁:悲观的认为当前并发非常严重,任何操作都是互斥,保证了线程的安全性,但降低了性能
- 乐观锁:乐观的认为当前并发并不严重,读的时候可以,对于写的情况,在进行上锁;以CAS自旋锁为例,性能高,但频繁自旋会消耗很大的资源
从数据的操作细粒度划分:
- 行锁:对表中的某一行上锁
- 表锁:对整张表上锁(基本不用)
从数据库的操作类型划分 (悲观锁):
- 读锁:称为共享锁,对同样数据进行读来说 可以同时进行 但是不能执行写操作
- 写锁:称为排他锁,上锁之后与释放锁之前,在整个过程之中不能进行任何的并发操作(其他的任务读与写都无法进行)
MylSAM只支持表锁,但不支持行锁, InnoDB可以支持行锁 在并发事务里,每个事务的增删改的操作相当于是上了行锁。
# 表锁
-- 对表上读锁或者写锁格式
lock table 表名 read/write;
-- 释放当前锁
unlock tables
-- 查看表的上锁情况
show open tables
# 行锁
# MySQL 是默认开启事务自动提交的
SET autocommit = 0; # 关闭
SET autocommit = 1; # 开启 默认的
-- 开启事务
begin;
-- 上行锁 对id = 8 的这行数据上锁
update `user` set name='前度' where id = 8;
-- 方式2
select * from `user` where id = 8 for update;
-- 释放锁
commint;
MVCC设计思想
MVCC,即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
事务的特性
- 原子性:一个事务是一个最小的操作单位,要么都成功,要么都失败
- 隔离性:数据库为每个用户开启的事务,不能被其他事务影响
- 一致性:事务提交之前与回滚之后的数据一致
- 持久性:事务一旦提交不可逆 被持久化到数据库中
事务的隔离级别
read uncommitted(读未提交) : 一个事务读取了另一个事务还没有提交的数据 会出现脏读的情况read committed(读已提交) : 已经解决了脏读问题,在一个事务中只会读取另一个事务已提交的数据,出现不可重复读情况repeatable read(可重复读): 默认级别 在一个事务中每次读取的数据都是一致的.不会出现脏读和不可重复读的问题。但会与幻读情况Serializable: 串行化的隔离界别直接不允许事务的并发发生,不存在任何的并发性。相当于锁表,性能非常差,一般都不考虑 通过上行锁来解决幻读问题
-- 设置隔离级别
set session transaction isolation level 隔离级别;
隔离导致的一些问题
脏读: 一个事务读取了另外一个事务未提交的数据
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同
虚读,幻读:是指在一个事务内读取了别的事务插入的数据,导致前后读取不一致(一般是行影响,多了一行)
MySQL在读和写的操作中,对读的性能做了并发性的保障,让所有的读都是快照读,对于写的时候,进行版本控制,如果真实数据的版本比快照版本要新,那么写之前就要进行版本(快照〉更新,这样就可以既能够提高读的并发性,又能够保证写的数据安全。

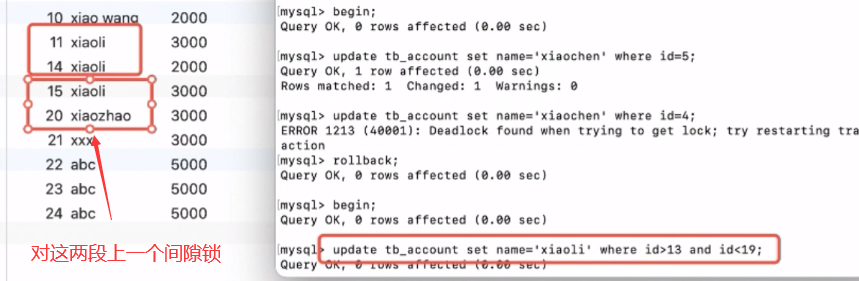
死锁与间隙锁
死锁
所谓的死锁,就是开启的锁没有办法关闭,导致资源的访问因为无法获得锁而处于阻塞状态
间隙锁
行锁只能对某一行上锁,如果相对某一个范围上锁,就可以使用间隙锁。间隙锁给的条件where id>13 and id<19,会 对13和19所处的间隙进行上锁。
五、部分面试题
为什么非主键索引的叶子节点存放的数据是主键值?
如果普通索引中不存放主键,而存放完整数据,那么就会造成:
数据冗余,虽然提升了查询性能,但是需要更多的空间来存放冗余的数据
维护麻烦:一个地方修改数据,需要在多棵索引树上修改。
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
mysql 为什么建议 innodb 表要建一个主键?
如果有一个主键,可以直接使用主键建索引
如果没有主键,会从第一列开始选择一列所有值都不相同的,作为索引列
如果没有选到唯一值的索引列,mysql 会建立一个隐藏列,维护一个唯一id,以此来组织索引
为什么推荐使用整形作为主键?
在索引中查找数据时,减少比较的性能。
使用整形作为主键相比字符型可以节省数据页的空间。
构建索引 b+ 树时,为了保证索引的有序性,使用整形可以避免页分裂。
主键为什么要自增?
索引结构 b+ 树,具有有序的特性。
-如果主键不是自增的,在进行增删数据的时候,会判断数据应该存放的位置,进行插入和删除,为了保持平衡,会对数据页进行分裂等操作移动数据,严重影响性能,所以主键需要是自增的,插入时,插入在索引数据页最后。
The End~~
MySQL优化之路的更多相关文章
- 微博MySQL优化之路--dockone微信群分享
微博MySQL优化之路 数据库是所有架构中不可缺少的一环,一旦数据库出现性能问题,那对整个系统都回来带灾难性的后果.并且数据库一旦出现问题,由于数据库天生有状态(分主从)带数据(一般还不小),所以出问 ...
- 微博MySQL优化之路
数据库是所有架构中不可缺少的一环,一旦数据库出现性能问题,那对整个系统都回来带灾难性的后果.并且数据库一旦出现问题,由于数据库天生有状态(分主从)带数据(一般还不小),所以出问题之后的恢复时间一般不太 ...
- 【转】单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
此文是根据杨尚刚在[QCON高可用架构群]中,针对MySQL在单表海量记录等场景下,业界广泛关注的MySQL问题的经验分享整理而成,转发请注明出处. 杨尚刚,美图公司数据库高级DBA,负责美图后端数据 ...
- [转载] 单表60亿记录等大数据场景的MySQL优化和运维之道 | 高可用架构
原文: http://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=209406532&idx=1&sn=2e9b0cc02bdd ...
- mysql优化案例
MySQL优化案例 Mysql5.1大表分区效率测试 Mysql5.1大表分区效率测试MySQL | add at 2009-03-27 12:29:31 by PConline | view:60, ...
- 巧用这19条MySQL优化,效率至少提高3倍
阅读本文大概需要 3.8 分钟. 作者丨喜欢拿铁的人 https://zhuanlan.zhihu.com/p/49888088 本文我们来谈谈项目中常用的MySQL优化方法,共19条,具体如下: 1 ...
- MySQL(3)---MySQL优化
MySQL优化 一.单表.双表.三表优化 1.单表 首先结论就是,range类型查询字段后面的索引全都无效 (1)建表 create table if not exists article( i ...
- 6.MySQL优化---高级进阶之表的设计及优化
转自互联网整理. 优化之路高级进阶——表的设计及优化 优化①:创建规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规 ...
- Mysql优化之优化工具profiling
程序员的成长之路 2016-11-23 22:42 Mysql优化之优化工具profiling 前言 mysql优化技术: mysql优化不是做一个操作就可以的优化,它包含很多的细节,需要一点一点的优 ...
随机推荐
- Qt简单的解析Json数据例子(一)
要解析的json的格式为: { "rootpath": "001", "usernum": 111, "childdep" ...
- 2014 12 27 bestcoder 第一题
水的不行不行的一道题 也是自己做的第一道题 纪念下 1 #include<stdio.h> 2 #include<string.h> 3 #include<math.h ...
- React事件处理、收集表单数据、高阶函数
3.React事件处理.收集表单数据.高阶函数 3.1事件处理 class Demo extends React.Component { /* 1. 通过onXxx属性指定事件处理函数(注意大小写) ...
- Python命名空间——locals()函数和globals()函数及局部赋值规则
Python使用叫做命名空间的东西来记录变量的轨迹.命名空间只是一个 字典,它的键字就是变量名,字典的值就是那些变量的值.实际上,命名空间可以象Python的字典一样进行访问,一会我们就会看到. 在一 ...
- 在同一台计算机中运行多个MySQL服务
目录 一.问题的来源 二.配置 1. 修改原来MySQL系统的my.ini文件 2. 修改注册表 3. 重新启动服务 4. 最终效果 一.问题的来源 这个学期里我需要修读<数据库系统>的课 ...
- 详细解读go语言中的chnanel
Channel 底层数据结构 type hchan struct { qcount uint // 当前队列中剩余元素个数 dataqsiz uint // 环形队列长度,即可以存放的元素个数 buf ...
- 2021秋 noip 模拟赛
9.9 T3 第负二题 \(f_i\) 的数学意义:中心在第 \(i\) 行的全 \(1\) 组成的最大正方形(对角线水平/竖直),对角线长 \(2f_i-1\). 显然 \(f_i\) 具有单调性( ...
- 初学AOP小结
Spring AOP理解 参考链接 AOP简介 AOP(面向切面编程),可以说时OOP的补充,使用OOP时,我们在日常编写代码的时候,一旦牵涉到大型一点的项目,项目不可或缺的事务处理,安全处理,验证处 ...
- CSS002. 字体穿透蒙层(用img设置字体的color)
之前在逛Apple Store时看到了下面的UI: 交互图标非常圆滑上手也很舒服,虽然背景底色本就是白底,但是只依赖css能不能使 "+" 穿透背景看到底色 ? 大致思路如下: ...
- word域实现动态填充信息附件下载
1.问题描述:在页面上一些下载附件功能,点击触发执行下载操作时候,有些电脑的浏览器可以,有些电脑的浏览器下载不了,电脑打开弹出的下载框下载的不是一个文件,而是一个如jspx后缀名的页面,jspx后缀是 ...