深入理解netty---从偶现宕机看netty流量控制
一、业务背景
目前移动端的使用场景中会用到大量的消息推送,push消息可以帮助运营人员更高效地实现运营目标(比如给用户推送营销活动或者提醒APP新功能)。
对于推送系统来说需要具备以下两个特性:
消息秒级送到用户,无延时,支持每秒百万推送,单机百万长连接。
支持通知、文本、自定义消息透传等展现形式。正是由于以上原因,对于系统的开发和维护带来了挑战。下图是推送系统的简单描述(API->推送模块->手机)。
二、问题背景
推送系统中长连接集群在稳定性测试、压力测试阶运行一段时间后随机会出现一个进程挂掉的情况,概率较小(频率为一个月左右发生一次),这会影响部分客户端消息送到的时效。
推送系统中的长连接节点(Broker系统)是基于Netty开发,此节点维护了服务端和手机终端的长连接,线上问题出现后,添加Netty内存泄露监控参数进行问题排查,观察多天但并未排查出问题。
由于长连接节点是Netty开发,为便于读者理解,下面简单介绍一下Netty。
三、 Netty介绍
Netty是一个高性能、异步事件驱动的NIO框架,基于Java NIO提供的API实现。它提供了对TCP、UDP和文件传输的支持,作为当前最流行的NIO框架,Netty在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,HBase,Hadoop,Bees,Dubbo等开源组件也基于Netty的NIO框架构建。
四、问题分析
4.1 猜想
最初猜想是长连接数导致的,但经过排查日志、分析代码,发现并不是此原因造成。
长连接数:39万,如下图:

每个channel字节大小1456, 按40万长连接计算,不致于产生内存过大现象。
4.2 查看GC日志
查看GC日志,发现进程挂掉之前频繁full GC(频率5分钟一次),但内存并未降低,怀疑堆外内存泄露。
4.3 分析heap内存情况
ChannelOutboundBuffer对象占将近5G内存,泄露原因基本可以确定:ChannelOutboundBuffer的entry数过多导致,查看ChannelOutboundBuffer的源码可以分析出,是ChannelOutboundBuffer中的数据。
没有写出去,导致一直积压;ChannelOutboundBuffer内部是一个链表结构。
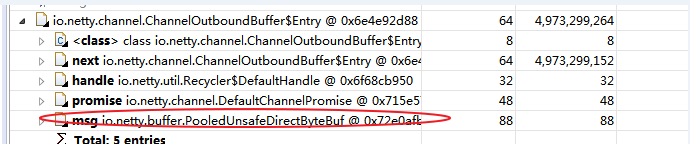
4.4 从上图分析数据未写出去,为什么会出现这种情况?
代码中实际有判断连接是否可用的情况(Channel.isActive),并且会对超时的连接进行关闭。从历史经验来看,这种情况发生在连接半打开(客户端异常关闭)的情况比较多---双方不进行数据通信无问题。
按上述猜想,测试环境进行重现和测试。
1)模拟客户端集群,并与长连接服务器建立连接,设置客户端节点的防火墙,模拟服务器与客户端网络异常的场景(即要模拟Channel.isActive调用成功,但数据实际发送不出去的情况)。
2)调小堆外内存,持续发送测试消息给之前的客户端。消息大小(1K左右)。
3)按照128M内存来计算,实际上调用9W多次就会出现。

五、问题解决
5.1 启用autoRead机制
当channel不可写时,关闭autoRead;
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {if (!ctx.channel().isWritable()) {Channel channel = ctx.channel();ChannelInfo channelInfo = ChannelManager.CHANNEL_CHANNELINFO.get(channel);String clientId = "";if (channelInfo != null) {clientId = channelInfo.getClientId();}LOGGER.info("channel is unwritable, turn off autoread, clientId:{}", clientId);channel.config().setAutoRead(false);}}
当数据可写时开启autoRead;
@Overridepublic void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception{Channel channel = ctx.channel();ChannelInfo channelInfo = ChannelManager.CHANNEL_CHANNELINFO.get(channel);String clientId = "";if (channelInfo != null) {clientId = channelInfo.getClientId();}if (channel.isWritable()) {LOGGER.info("channel is writable again, turn on autoread, clientId:{}", clientId);channel.config().setAutoRead(true);}}
说明:
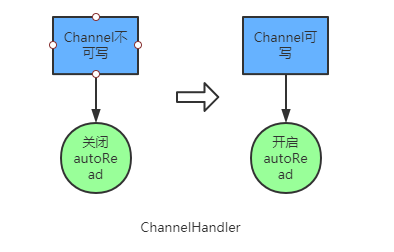
autoRead的作用是更精确的速率控制,如果打开的时候Netty就会帮我们注册读事件。当注册了读事件后,如果网络可读,则Netty就会从channel读取数据。那如果autoread关掉后,则Netty会不注册读事件。
这样即使是对端发送数据过来了也不会触发读事件,从而也不会从channel读取到数据。当recv_buffer满时,也就不会再接收数据。
5.2 设置高低水位
serverBootstrap.option(ChannelOption.WRITE_BUFFER_WATER_MARK, new WriteBufferWaterMark(1024 * 1024, 8 * 1024 * 1024));
注:高低水位配合后面的isWritable使用
5.3 增加channel.isWritable()的判断
channel是否可用除了校验channel.isActive()还需要加上channel.isWrite()的判断,isActive只是保证连接是否激活,而是否可写由isWrite来决定。
private void writeBackMessage(ChannelHandlerContext ctx, MqttMessage message) {Channel channel = ctx.channel();//增加channel.isWritable()的判断if (channel.isActive() && channel.isWritable()) {ChannelFuture cf = channel.writeAndFlush(message);if (cf.isDone() && cf.cause() != null) {LOGGER.error("channelWrite error!", cf.cause());ctx.close();}}}
注:isWritable可以来控制ChannelOutboundBuffer,不让其无限制膨胀。其机制就是利用设置好的channel高低水位来进行判断。
5.4 问题验证
修改后再进行测试,发送到27W次也并不报错;

六、解决思路分析
一般Netty数据处理流程如下:将读取的数据交由业务线程处理,处理完成再发送出去(整个过程是异步的),Netty为了提高网络的吞吐量,在业务层与socket之间增加了一个ChannelOutboundBuffer。
在调用channel.write的时候,所有写出的数据其实并没有写到socket,而是先写到ChannelOutboundBuffer。当调用channel.flush的时候才真正的向socket写出。因为这中间有一个buffer,就存在速率匹配了,而且这个buffer还是无界的(链表),也就是你如果没有控制channel.write的速度,会有大量的数据在这个buffer里堆积,如果又碰到socket写不出数据的时候(isActive此时判断无效)或者写得慢的情况。
很有可能的结果就是资源耗尽,而且如果ChannelOutboundBuffer存放的是DirectByteBuffer,这会让问题更加难排查。
流程可抽象如下:
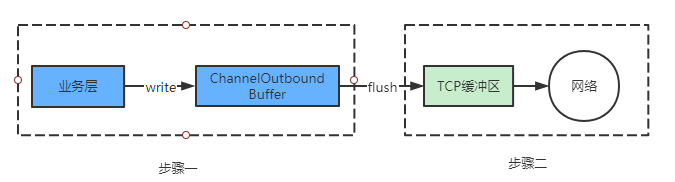
从上面的分析可以看出,步骤一写太快(快到处理不过来)或者下游发送不出数据都会造成问题,这实际是一个速率匹配问题。
七、Netty源码说明
超过高水位
当ChannelOutboundBuffer的容量超过高水位设定阈值后,isWritable()返回false,设置channel不可写(setUnwritable),并且触发fireChannelWritabilityChanged()。
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {if (size == 0) {return;}long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {setUnwritable(invokeLater);}}private void setUnwritable(boolean invokeLater) {for (;;) {final int oldValue = unwritable;final int newValue = oldValue | 1;if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) {if (oldValue == 0 && newValue != 0) {fireChannelWritabilityChanged(invokeLater);}break;}}}
低于低水位
当ChannelOutboundBuffer的容量低于低水位设定阈值后,isWritable()返回true,设置channel可写,并且触发fireChannelWritabilityChanged()。
private void decrementPendingOutboundBytes(long size, boolean invokeLater, boolean notifyWritability) {if (size == 0) {return;}long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, -size);if (notifyWritability && newWriteBufferSize < channel.config().getWriteBufferLowWaterMark()) {setWritable(invokeLater);}}private void setWritable(boolean invokeLater) {for (;;) {final int oldValue = unwritable;final int newValue = oldValue & ~1;if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) {if (oldValue != 0 && newValue == 0) {fireChannelWritabilityChanged(invokeLater);}break;}}}
八、总结
当ChannelOutboundBuffer的容量超过高水位设定阈值后,isWritable()返回false,表明消息产生堆积,需要降低写入速度。
当ChannelOutboundBuffer的容量低于低水位设定阈值后,isWritable()返回true,表明消息过少,需要提高写入速度。通过以上三个步骤修改后,部署线上观察半年未发生问题出现。
作者:vivo互联网服务器团队-Zhang Lin
深入理解netty---从偶现宕机看netty流量控制的更多相关文章
- Solr4.8.0源码分析(26)之Recovery失败造成的宕机原因分析
最近在公司做SolrCloud的容灾测试,刚好碰到了一个比较蛋疼的问题,跟SolrCloud的Recovery和leader选举有关,正好拿出来分析下. 现象是这样的:比如我有一台3个shard的So ...
- mongodb副本集中其中一个节点宕机无法重启的问题
2-8日我还在家中的时候,被告知mongodb副本集中其中一个从节点因未知原因宕机,然后暂时负责代管的同事无论如何就是启动不起来. 当时mongodb的日志信息是这样的: 实际上这里这么长一串最重要的 ...
- Redis的KEYS命令引起宕机事件
摘要: 使用 Redis 的开发者必看,吸取教训啊! 原文:Redis 的 KEYS 命令引起 RDS 数据库雪崩,RDS 发生两次宕机,造成几百万的资金损失 作者:陈浩翔 Fundebug经授权转载 ...
- 祸害阿里云宕机 3 小时的 IO HANG 究竟是个什么鬼?!
2019年3月3日凌晨,微博炸锅,有网友反映说阿里云疑似出现宕机,华北很多互联网公司受到暴击伤害,APP.网站全部瘫痪,我自己的朋友圈和微信群里也有好友反馈,刚刚从被窝被叫起来去修Bug,结果发现服务 ...
- Cloud Native Weekly |面对云平台宕机,企业如何止损
KubeEdge v0.2发布 KubeEdge在18年11月24日的上海KubeCon上宣布开源的一个开源项目,旨在依托K8S的容器编排和调度能力,实现云边协同.计算下沉.海量设备的平滑接入. Ku ...
- HBaseRegionServer宕机数据恢复
本文由 网易云 发布 作者:范欣欣 本篇文章仅限内部分享,如需转载,请联系网易获取授权. 众所周知,HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松地 ...
- HBase–RegionServer宕机恢复原理
Region Server宕机总述 HBase一个很大的特色是扩展性极其友好,可以通过简单地加机器实现集群规模的线性扩展,而且机器的配置并不需要太好,通过大量廉价机器代替价格昂贵的高性能机器.但也正因 ...
- 服务应用突然宕机了?别怕,Dubbo 帮你自动搞定服务隔离!
某日中午,午睡正香的时候,接到系统的报警电话,提示生产某物理机异常宕机了,目前该物理机已恢复,需要重启上面部署的应用. 这时瞬间没有了睡意,登上堡垒机,快速重启了应用,系统恢复正常.本想着继续午睡,但 ...
- 解Bug之路-记一次对端机器宕机后的tcp行为
解Bug之路-记一次对端机器宕机后的tcp行为 前言 机器一般过质保之后,就会因为各种各样的问题而宕机.而这一次的宕机,让笔者观察到了平常观察不到的tcp在对端宕机情况下的行为.经过详细跟踪分析原因之 ...
随机推荐
- springboot 和spring cloud 博客分享
spring boot 知识点总结 天狼星 https://www.cnblogs.com/wjqhuaxia/p/9820902.html spring cloud 知识点总结 姿势帝 https: ...
- C#多线程---ReaderWriterLock实现线程同步
一.简介 当我们需要对一个共享资源多次读取的时候,用前面Monitor的同步锁就没有必要了.因为同步锁每次只允许一个线程访问共享资源,其他线程都会阻塞. 此时,通过ReaderWriterLock类可 ...
- 刷题-力扣-剑指 Offer 15. 二进制中1的个数
剑指 Offer 15. 二进制中1的个数 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/er-jin-zhi-zhong-1de- ...
- go逃逸分析
目录 1. 前言 2. 逃逸策略 3. 逃逸场景 3.1 指针逃逸 3.2 栈空间不足逃逸 3.3 动态类型逃逸 3.4 闭包引用对象逃逸 4 逃逸总结 5. 注意事项 1. 前言 所谓的逃逸分析(E ...
- vue3.0入门(二)
前言 最近在b站上学习了飞哥的vue教程 学习案例已上传,下载地址 指令 #id2{ // css部分 font-size: 24px; color: green; } v-bind:href=&qu ...
- Google Chrome浏览器必备的20个插件
Google Chrome浏览器虽然与火狐浏览器有所区别,不过他们都是很开放的浏览器产品,所以也有许多有用的插件,这些插件对于日常生活与网络冲浪都很有用,比如网银,炒股等. Google Chrome ...
- Robot Framework(14)- Variables 表的详细使用和具体例子
如果你还想从头学起Robot Framework,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1770899.html Variable ...
- Sentry 后端监控 - 最佳实践(官方教程)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- clion结合vcpkg以及GTest的使用
目录 一.vcpkg简介.下载和使用 1. vcpkg是什么 2. vcpkg下载 3. 使用vcpkg下载第三方库 二.clion结合vcpkg 1. 方法一:使用环境变量 2. 方法二:添加cma ...
- awk的执行方式
https://blog.csdn.net/fengyuanye/article/details/82858863 awk执行有三种形式: 1.直接以命令行来执行, 语法形式为:awk ...