PyCharm中目录directory与包package的区别及相关import详解
一、概念介绍
在介绍目录directory与包package的区别之前,先理解一个概念---模块
模块的定义:本质就是以.py结尾的python文件,模块的目的是为了其他程序进行引用。
目录(Directory):
Directory在pycharm中就是一个文件夹,放置资源文件,对应于在进行JavaWeb开发时用于放置css/js文件的目录,或者说在进行物体识别时,用来存储背景图像的文件夹。该文件夹其中并不包含_ _ init.py_ _文件
包(Package):
对于Python package 文件夹而言,与Dictionary不同之处在于其会自动创建__init__.py文件。
简单的说,python package就是一个目录,其中包括一组模块和一个__init__.py文件。
二、导入模块
导入模块的方法:
import module_name
import module1_name,module2_name
from module_name import * ---> 一般import * 不建议使用
from module_name import m1,m2,m3 ---> m1为module_name下面的方法或变量
from module_name import logger as logger_a ---> 为导入的变量或方法取个别名,引用时直接用别名
1.同级目录下模块的导入:

在main_day41.py中导入para_day41.py,两种方法:

#方法一: 相当于把para_day41.py中的所有代码拷贝过来赋值给变量para_day41,引用时直接用"该变量."
import para_day41
para_day41.show_para()
运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day4/main_day41.py
in the para_day41
#方法二: 只把para_day41.py中name变量和show_para方法拷贝过来,可以直接用(推荐用该方法)
from para_day41 import name,show_para
print(name)
show_para()
运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day4/main_day41.py
para_day41
in the para_day41
2.不同级目录下模块的导入:
(1)导入子目录下的模块
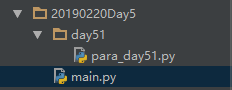
main.py中导入day51目录下面para_day51.py
import day51.para_day51
day51.para_day51.show_para()
from day51.para_day51 import *
show_para()
from day51 import para_day51
para_day51.show_para()
运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day5/main.py
in the para_day51
(2)导入上级目录下的模块
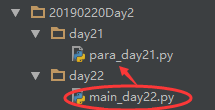
day22目录下面的main_day22.py导入day21目录下的para_day21.py
注:执行main_day22.py时,要导入day21目录下的para_day21.py,具体的搜索路径是这样的:
首先,python需要在当前目录下去找para_day21.py,发现没有,然后就到sys.path列表中的每个路径下面去找:
['D:\\Pyexample\\20190220Day2\\day22', 'D:\\Pyexample', 'D:\\Pyexample\\W3', 'D:\\Pyexample\\20181113', 'D:\\Pyexample\\CSP\\cspmonitor', 'D:\\Pyexample\\python', 'D:\\python365\\python36.zip', 'D:\\python365\\DLLs', 'D:\\python365\\lib', 'D:\\python365', 'D:\\python365\\lib\\site-packages']
结果仍没找到,所以就会报错:
Traceback (most recent call last):
File "D:/Pyexample/20190220Day2/day22/main_day22.py", line 21, in <module>
import day21.para_day21
ModuleNotFoundError: No module named 'day21'
解决办法:需要手动将para_day21.py所在的父目录或上上级目录加到sys.path列表中,让python可以搜索到即可
import sys,os
print(sys.path) p = os.path.dirname(os.path.dirname(os.path.abspath(file))) #获取要导入模块的上上级目录
print(p) sys.path.insert(0,p) #把获取到的上上级目录加到sys.path列表中 from day21 import para_day21
print(para_day21.name)
para_day21.show_para()
运行结果:
['D:\Pyexample\20190220Day2\day22', 'D:\Pyexample', 'D:\Pyexample\W3', 'D:\Pyexample\20181113', 'D:\Pyexample\CSP\cspmonitor', 'D:\Pyexample\python', 'D:\python365\python36.zip', 'D:\python365\DLLs', 'D:\python365\lib', 'D:\python365', 'D:\python365\lib\site-packages']
D:\Pyexample\20190220Day2
['D:\Pyexample\20190220Day2', 'D:\Pyexample\20190220Day2\day22', 'D:\Pyexample', 'D:\Pyexample\W3', 'D:\Pyexample\20181113', 'D:\Pyexample\CSP\cspmonitor', 'D:\Pyexample\python', 'D:\python365\python36.zip', 'D:\python365\DLLs', 'D:\python365\lib', 'D:\python365', 'D:\python365\lib\site-packages']
para_day21
in the para_day21
或者把要导入模块的父目录加到sys.path列表中
p = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) + '\\day21' #获取要导入模块的父目录
sys.path.insert(0,p)
import para_day21
print(para_day21.name)
para_day21.show_para()
三、导入包
导入包的本质就是执行这个包下面的__init__.py文件
1.同级路径下包的导入:
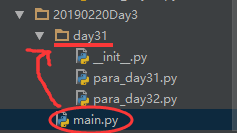
main.py中导入包day31,直接用import 包名即可
import day31
(1)__init__.py中没有内容时
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py Process finished with exit code 0
(2)__init__.py中有内容时:
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py
in the day31 __init__ Process finished with exit code 0
2.不同级路径下包的导入:
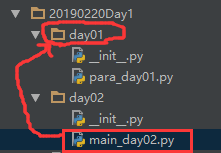
前提:需要将要导入的包所在的路径添加到sys.path列表中,方法同上,不再赘述。
3. 导入包中的模块
只是导入一个包并没有什么实际意义,包是用来从逻辑上组织模块的,所以实际项目中更多的是导入包中的模块,导入包中模块的方法:
from Package1 import Module1
from Package1 import Package2
from Package1.Module1 import m1,m2 ---> m1,m2为模块中的变量或方法
from Package1.Module1 import *
import Package1.Module1
import Package1.Package2
要导入的包及其模块结构如下:
(1)在main.py中导入包day31下面的para_day31.py或者para_day32.py模块
import day31.para_day31,day31.para_day32
day31.para_day31.show_para()
day31.para_day32.show_para() 运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py
in the day31 init
in the para_day31
in the para_day32 Process finished with exit code 0
或者:
from day31 import para_day31,para_day32
para_day31.show_para()
para_day32.show_para() 运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py
in the day31 init
in the para_day31
in the para_day32 Process finished with exit code 0
或者:
from day31.para_day31 import show_para,name
print(name)
show_para() 运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py
in the day31 init
para_day31
in the para_day31 Process finished with exit code 0
或者:
from day31.para_day31 import *
print(name)
show_para()
(2)在main.py中导入包day31下面所有的模块,即全部导入
from day31 import *
para_day31.show_para()
para_day32.show_para() 运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py
in the day31 init
Traceback (most recent call last):
File "D:/Pyexample/20190220Day3/main.py", line 35, in <module>
para_day31.show_para()
NameError: name 'para_day31' is not defined Process finished with exit code 1
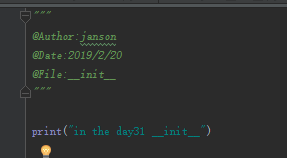
此时,需要用到__init__.py文件中的__all__变量,在day31包中的__init__.py文件中定义如下:
"""
@Author:janson
@Date:2019/2/20
@File:__init__
""" print("in the day31 init") all = ['para_day31','para_day32']
这时 from day31 import * 就会把注册在包__init__.py 文件中 __all__ 列表中的子模块和子包导入到当前作用域中来:
再次运行就不会报错了:
from day31 import *
para_day31.show_para()
para_day32.show_para() 运行结果:
D:\python365\python3.exe D:/Pyexample/20190220Day3/main.py
in the day31 init
in the para_day31
in the para_day32 Process finished with exit code 0
转载于:https://www.cnblogs.com/janson071/p/10407459.html
PyCharm中目录directory与包package的区别及相关import详解的更多相关文章
- python入门-PyCharm中目录directory与包package的区别及相关import详解
一.概念介绍 在介绍目录directory与包package的区别之前,先理解一个概念---模块 模块的定义:本质就是以.py结尾的python文件,模块的目的是为了其他程序进行引用. 目录(Dict ...
- Python入门之PyCharm中目录directory与包package的区别
对于Python而言,有一点是要认识明确的,python作为一个相对而言轻量级的,易用的脚本语言(当然其功能并不仅限于此,在此只是讨论该特点),随着程序的增长,可能想要把它分成几个文件,以便逻辑更加清 ...
- JAVA高级架构师基础功:Spring中AOP的两种代理方式:动态代理和CGLIB详解
在spring框架中使用了两种代理方式: 1.JDK自带的动态代理. 2.Spring框架自己提供的CGLIB的方式. 这两种也是Spring框架核心AOP的基础. 在详细讲解上述提到的动态代理和CG ...
- 【翻译】Anatomy of a Program in Memory—剖析内存中的一个程序(进程的虚拟存储器映像布局详解)
[翻译]Anatomy of a Program in Memory—剖析内存中的一个程序(进程的虚拟存储器映像布局详解) . . .
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- Opencv中Mat矩阵相乘——点乘、dot、mul运算详解
Opencv中Mat矩阵相乘——点乘.dot.mul运算详解 2016年09月02日 00:00:36 -牧野- 阅读数:59593 标签: Opencv矩阵相乘点乘dotmul 更多 个人分类: O ...
- MySQL中tinytext、text、mediumtext和longtext等各个类型详解
转: MySQL中tinytext.text.mediumtext和longtext等各个类型详解 2018年06月13日 08:55:24 youcijibi 阅读数 26900更多 个人分类: 每 ...
- 机器学习中的隐马尔科夫模型(HMM)详解
机器学习中的隐马尔科夫模型(HMM)详解 在之前介绍贝叶斯网络的博文中,我们已经讨论过概率图模型(PGM)的概念了.Russell等在文献[1]中指出:"在统计学中,图模型这个术语指包含贝叶 ...
随机推荐
- Sentry Web 性能监控 - Web Vitals
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- 比培训机构还详细的 Python 学习路线,你信吗 0^0
前言 这其实是将自己写的文章进行一个总结分类,并不代表最佳学习路线 会不断更新这篇文章...没链接的文章正在编写ing...会不会哪天我的这个目录就出现在培训机构的目录上了... 目前实战比较少(要是 ...
- 回收Windows 10恢复分区之后的磁盘空间
我电脑上安装了Windows 10和Linux双系统,现在将Linux删除之后,准备将其磁盘空间并入到Windows 10的C盘中,但是发现C盘跟Linux空间之间还隔了一个Windows的恢复分区, ...
- .Net性能调优-MemoryPool
简单用法 //获取MemoryPool实例,实际返回了一个ArrayMemoryPool<T> MemoryPool<char> Pool = MemoryPool<ch ...
- 三剑客之awk 逐行读取
目录: 一.awk工作原理 二.按行输出文本 三.按字段输出文本 四.通过管道,双引号调用shall命令 五.CPU使用率 六.使用awk 统计 httpd 访问日志中每个客户端IP的出现次数 一.a ...
- 3.15学习总结(Python爬取网站数据并存入数据库)
在官网上下载了Python和PyCharm,并在网上简单的学习了爬虫的相关知识. 结对开发的第一阶段要求: 网上爬取最新疫情数据,并存入到MySql数据库中 在可视化显示数据详细信息 项目代码: im ...
- Webpack的配置项
Webpack配置选项 经历了考研以后,接下来的时间里准备捡起来这些以前学的东西,并且继续向着前端的方向出发,给自己多一条路的选择.话不多说,直接开始. moudule.exports = { / ...
- Dapr实战(一) 基础概念与环境搭建
什么是Dapr Dapr 是一个可移植的.事件驱动的运行时,可运行在云平台或边缘计算中.支持多种编程语言和开发框架. 上面是官方对Dapr的介绍.有点难以理解,大白话可以理解为:Dapr是一个运行时, ...
- 配置Nginx和php-fpm用Sock套接字连接时,找不到php-fpm.sock的原因
php5.3之后的版本,php-fpm.conf里的listen的默认配置是127.0.0.1:9000,就不会生成php-fpm.sock,因此如果需要Nginx里的配置有链接tmp/php-fpm ...
- P5405-[CTS2019]氪金手游【树形dp,容斥,数学期望】
前言 话说在\(Loj\)下了个数据发现这题的名字叫\(fgo\) 正题 题目链接:https://www.luogu.com.cn/problem/P5405 题目大意 \(n\)张卡的权值为\(1 ...