python11文件读写模块


将文件的打开和关闭,交给上下文管理工具with去实现。
def read_file():
"""
读取文件
:return:
"""
file_path1 = 'D:\\PycharmProjects\\p1\\text.txt'
file_path2 = 'D:/PycharmProjects/p1/text.txt'
#普通读取
f = open(file_path1,encoding='utf-8')
#rest = f.read()
###############################
#读取指定的内容
###他不会从头开始读取,而是延续上一次读取的位置进行读取
rest = f.read(10)
print(rest)
print("@@@@@@@@@@@@@@@@")
rest = f.read(20)
print(rest)
print("@@@@@@@@@@@@@@@@")
rest = f.read()
print(rest)
##############################
f.close()
if __name__ == "__main__":
read_file() jieguo :
【发文说明】
博客园
@@@@@@@@@@@@@@@@
是面向开发者的知识分享社区,不允许发布任
@@@@@@@@@@@@@@@@
何推广、广告、政治方面的内容。
博客园首页(即网站首页)只能发布原创的、高质量的、能让读者从中学到东西的内容。
如果博文质量不符合首页要求,会被工作人员移出首页,望理解。如有疑问,请联系contact@cnblogs.com。
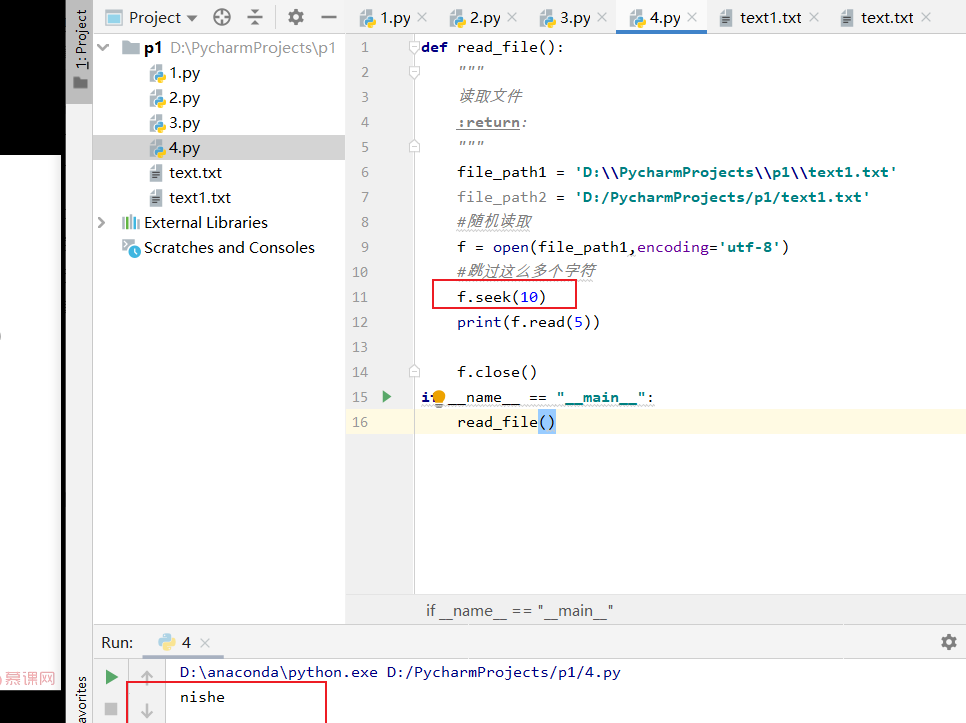
def read_file():
"""
读取文件
:return:
"""
file_path1 = 'D:\\PycharmProjects\\p1\\text1.txt'
file_path2 = 'D:/PycharmProjects/p1/text1.txt'
#随机读取
f = open(file_path1,encoding='utf-8')
#跳过这么多个字符
#f.seek(10)
#print(f.read(5))
#rest = f.readline()
# print(rest)
#print(f.readline())#接着上一次读取继续读取
# print(f.readline()) #读取所有的行,返回列表:
rest = f.readlines()
print(rest) f.close()
if __name__ == "__main__":
read_file() jeiguo :
['Process finished with exit code 0\n', 'finished with exit code\n', '\n', 'finished with exit\n', '\n', 'finished with exit code\n']
import random
from datetime import datetime def w_f():
"""
写入文件
:return:
"""
file_name = 'D:/PycharmProjects/p1/text1.txt' f = open(file_name,'w')
f.write("quanzhiqiang")
f.write("\n")
f.write("QQQQ")
f.close()
def w_m_f():
file_name = "D:/PycharmProjects/p1/text1.txt"
with open(file_name,"w",encoding='utf-8') as f:
l = ["11111","2222222","3333"]
f.writelines(l) def w_u_l():
rest = "用户:{}-访问时间:{}\n".format(random.randint(1000,9999),datetime.now())
file_name = "write_user_log.txt"
with open(file_name,"a",encoding="utf-8") as f:
f.writelines(rest) def read_and_write():
"""
先读再写入
:return:
"""
file_name = "read_and_write.txt"
with open(file_name,"r+",encoding="utf-8") as f:
read_rest = f.read()
#如果里面没用1,写入一行数据aaa
#如果有,写入bbb
if "1" in read_rest:
f.write("bbb")
else:
f.write("aaa") if __name__ == "__main__":
read_and_write()
文件的备份:
import os
class FileBackup(object):
"""
文本的备份
"""
def __init__(self,src,dist):
"""
构造方法
:param src: 需要备份的文件目录
:param dist: 备份到的目录
"""
self.src = src
self.dist = dist def read_files(self):
""" 读取src的所有文件
:return:
"""
ls = os.listdir(self.src)
print(ls)
for l in ls:
self.back_file(l) def back_file(self,filename):
"""
备份
:param filename: 文件/文件夹的名称
:return:
"""
#判断dist是否存在,不存在就创建这个目录
if not os.path.exists(self.dist):
os.makedirs(self.dist)
print("文件夹不存在,已经创建")
#拼接文件的完整路径
full_src_path = os.path.join(self.src,filename)
full_dist_path = os.path.join(self.dist, filename)
#判断文件是否为我们备份的文件
if os.path.isfile(full_src_path) and os.path.splitext(full_src_path)[-1].lower() == ".txt":
print(full_src_path)
#读取文件内容
with open(full_dist_path,"w",encoding="utf-8") as f_dist:
print(">>开始备份 {}".format(filename))
with open(full_src_path,"r",encoding="utf-8") as f_src:
while True:
rest = f_src.read(100)
if not rest:
break
f_dist.write(rest)
f_dist.flush()
#把读取的内容写入新的文件
else:
print("不存在") if __name__ == "__main__":
"""
这样子写通用性不高
src_path = 'D:\\PycharmProjects\\p1\\src'
dist_path = 'D:\\PycharmProjects\\p1\\dist'
"""
base_path = os.path.dirname(os.path.abspath(__file__))
src_path = os.path.join(base_path,"src")
dist_path = os.path.join(base_path,"dist")
print(base_path)
bak = FileBackup(src_path,dist_path)
bak.read_files()
python11文件读写模块的更多相关文章
- node.js之文件读写模块,配合递归函数遍历文件夹和其中的文件
fs.stat会返回文件夹会文件的属性 var fs = require('fs'); var wenwa = function (pathname,callback) { fs.stat(pathn ...
- 7. Buffer_包描述文件_npm常用指令_fs文件读写_模块化require的规则
1. Buffer 一个和数组类似的对象,不同是 Buffer 是专门用来保存二进制数据的. 特点: 大小固定: 在创建时就确定了,且无法调整 性能较好: 直接对计算机的内存进行操作 每个元素大小为1 ...
- python自动化--语言基础四模块、文件读写、异常
模块1.什么是模块?可以理解为一个py文件其实就是一个模块.比如xiami.py就是一个模块,想引入使用就在代码里写import xiami即可2.模块首先从当前目录查询,如果没有再按path顺序逐一 ...
- nodejs基础(回调函数、模块、事件、文件读写、目录的创建与删除)
node官网:http://nodejs.cn/ 今天想看看node的视频,对node进一步了解, 1.我们可以从官网下载node到自己的电脑上,今天了解到node的真正概念,node时javascr ...
- [Python]-pandas模块-CSV文件读写
Pandas 即Python Data Analysis Library,是为了解决数据分析而创建的第三方工具,它不仅提供了丰富的数据模型,而且支持多种文件格式处理,包括CSV.HDF5.HTML 等 ...
- python基础之文件读写
python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使用os模块的一些方法如下: 得到 ...
- Python之文件读写
本节内容: I/O操作概述 文件读写实现原理与操作步骤 文件打开模式 Python文件操作步骤示例 Python文件读取相关方法 文件读写与字符编码 一.I/O操作概述 I/O在计算机中是指Input ...
- 第二篇:python基础之文件读写
python基础之文件读写 python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使 ...
- [js高手之路]node js系列课程-创建简易web服务器与文件读写
web服务器至少有以下几个特点: 1.24小时不停止的工作,也就是说这个进程要常驻在内存中 2.24小时在某一端口监听,如: http://localhost:8080, www服务器默认端口80 3 ...
随机推荐
- UltraSoft - Beta - 发布声明
1. Beta版本更新内容 新功能 (1)消息中心页面 课程爬取到新DDL.资源时会以通知的方式通知用户,本次同步更新了哪些内容一目了然.此外,当被作为参与成员添加DDL时也会通知.一些系统通知也会放 ...
- [火星补锅] 非确定性有穷状态决策自动机练习题Vol.1 T3 第K大区间 题解
前言: 老火星人了 解析: 很妙的二分题.如果没想到二分答案.. 很容易想到尝试用双指针扫一下,看看能不能统计答案. 首先,tail指针右移时很好处理,因为tail指针右移对区间最大值的影响之可能作用 ...
- IRCUT作用
IRCUT组成原理 IRCUT由两层滤光片组成,一片红外截止或吸收滤光片和一片全透光谱滤光片 白天是红外截止滤光片工作,晚上是全透滤光片工作,白天摄像头可以接收到人眼无法识别的红外线,会导致图像与肉眼 ...
- c++ get keyboard event
#include <string> #include <iostream> #include "windows.h" #include <conio. ...
- Spring事务不生效问题
事务未生效可能造成严重的数据不一致性问题,因而保证事务生效至关重要.Spring事务是通过Spring aop实现的,所以不生效的本质问题是spring aop没生效,或者说没有代理成功,所以有必要了 ...
- QuantumTunnel:内网穿透服务设计
背景 最近工作中有公网访问内网服务的需求,便了解了内网穿透相关的知识.发现原理和实现都不复杂,遂产生了设计一个内网穿透的想法. 名字想好了,就叫QuantumTunnel,量子隧道,名字来源于量子纠缠 ...
- 小入门 Django(做个疫情数据报告)
Django 是 Python web框架,发音 [ˈdʒæŋɡo] ,翻译成中文叫"姜狗". 为什么要学框架?其实我们自己完全可以用 Python 代码从0到1写一个web网站, ...
- 性能工具之代码级性能测试工具ContiPerf
前言 做性能的同学一定遇到过这样的场景:应用级别的性能测试发现一个操作的响应时间很长,然后要花费很多时间去逐级排查,最后却发现罪魁祸首是代码中某个实现低效的底层算法.这种自上而下的逐级排查定位的方法, ...
- C++ new 运算符 用法总结
C++ new 运算符 用法总结 使用 new 运算符 分配内存 并 初始化 1.分配内存初始化标量类型(如 int 或 double),在类型名后加初始值,并用小括号括起,C++11中也支持大括号. ...
- xxx.app已损坏无法打开、来自身份不明的开发者解决办法
在 Mac 上安装非 App Store 软件时,可能会遇到一些这样或那样的问题,这篇文章就 Mac 从 .dmg 安装软件时可能遇到的问题提一些解决方法. 状况一:双击 .dmg 安装软件出现以下情 ...