【odoo】【知识点】生成pdf文件时缺少样式的问题
欢迎转载,但需标注出处,谢谢!
背景
近期在客户的项目中发现在自定义报表样式的时候,存在渲染为html正常,但是在生成pdf的时候,缺少样式的情况。
分析
涉及到的odoo源码中的ir_actions_report.py文件中的代码
def _prepare_html(self, html):
'''Divide and recreate the header/footer html by merging all found in html.
The bodies are extracted and added to a list. Then, extract the specific_paperformat_args.
The idea is to put all headers/footers together. Then, we will use a javascript trick
(see minimal_layout template) to set the right header/footer during the processing of wkhtmltopdf.
This allows the computation of multiple reports in a single call to wkhtmltopdf.
:param html: The html rendered by render_qweb_html.
:type: bodies: list of string representing each one a html body.
:type header: string representing the html header.
:type footer: string representing the html footer.
:type specific_paperformat_args: dictionary of prioritized paperformat values.
:return: bodies, header, footer, specific_paperformat_args
'''
IrConfig = self.env['ir.config_parameter'].sudo()
base_url = IrConfig.get_param('report.url') or IrConfig.get_param('web.base.url')
# Return empty dictionary if 'web.minimal_layout' not found.
layout = self.env.ref('web.minimal_layout', False)
if not layout:
return {}
layout = self.env['ir.ui.view'].browse(self.env['ir.ui.view'].get_view_id('web.minimal_layout'))
root = lxml.html.fromstring(html)
match_klass = "//div[contains(concat(' ', normalize-space(@class), ' '), ' {} ')]"
header_node = etree.Element('div', id='minimal_layout_report_headers')
footer_node = etree.Element('div', id='minimal_layout_report_footers')
bodies = []
res_ids = []
body_parent = root.xpath('//main')[0]
# Retrieve headers
for node in root.xpath(match_klass.format('header')):
body_parent = node.getparent()
node.getparent().remove(node)
header_node.append(node)
# Retrieve footers
for node in root.xpath(match_klass.format('footer')):
body_parent = node.getparent()
node.getparent().remove(node)
footer_node.append(node)
# Retrieve bodies
for node in root.xpath(match_klass.format('article')):
layout_with_lang = layout
# set context language to body language
if node.get('data-oe-lang'):
layout_with_lang = layout_with_lang.with_context(lang=node.get('data-oe-lang'))
body = layout_with_lang._render(dict(subst=False, body=lxml.html.tostring(node), base_url=base_url))
bodies.append(body)
if node.get('data-oe-model') == self.model:
res_ids.append(int(node.get('data-oe-id', 0)))
else:
res_ids.append(None)
if not bodies:
body = bytearray().join([lxml.html.tostring(c) for c in body_parent.getchildren()])
bodies.append(body)
# Get paperformat arguments set in the root html tag. They are prioritized over
# paperformat-record arguments.
specific_paperformat_args = {}
for attribute in root.items():
if attribute[0].startswith('data-report-'):
specific_paperformat_args[attribute[0]] = attribute[1]
header = layout._render(dict(subst=True, body=lxml.html.tostring(header_node), base_url=base_url))
footer = layout._render(dict(subst=True, body=lxml.html.tostring(footer_node), base_url=base_url))
return bodies, res_ids, header, footer, specific_paperformat_args
- 我们可以看到在
base_url = IrConfig.get_param('report.url') or IrConfig.get_param('web.base.url')中取了系统参数中的report.url或web.base.url中的地址。 - 在
body = layout_with_lang._render(dict(subst=False, body=lxml.html.tostring(node), base_url=base_url))中渲染了我们必要的样式,若这里的url出错,那么这里我们将缺少样式内容。当然,若是全部都通过html原生去实现样式,那么也是可以避免如上的问题。
解决方案
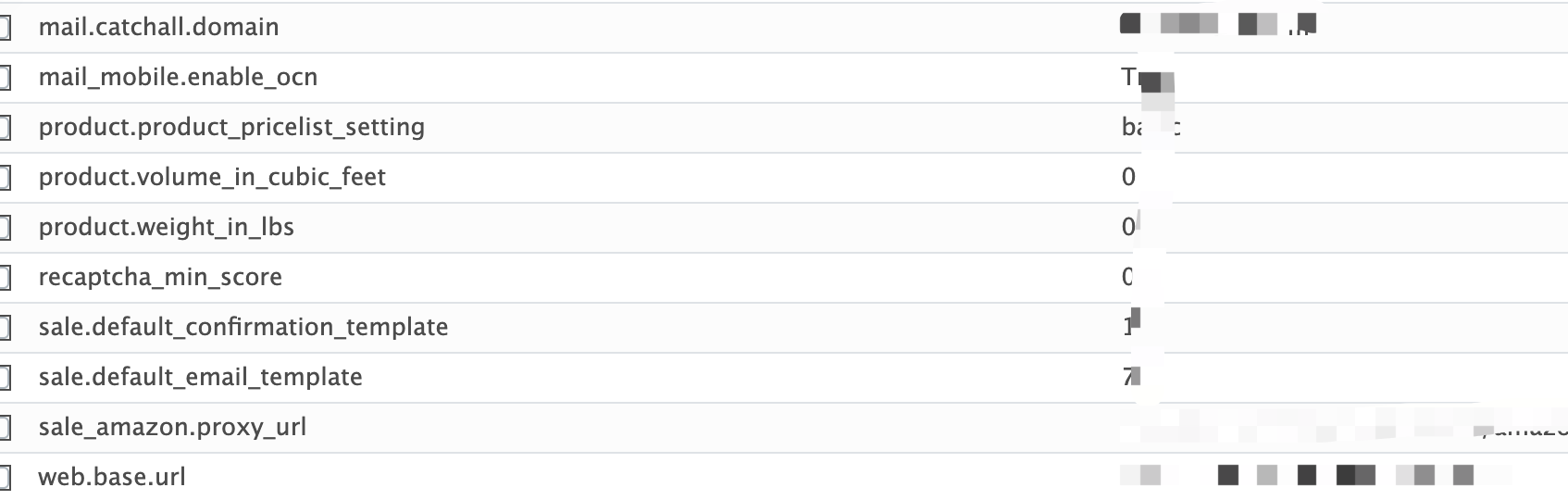
在系统参数添加report.url或者web.base.url的值为http://127.0.0.1:8069(填写本机的地址)
【odoo】【知识点】生成pdf文件时缺少样式的问题的更多相关文章
- 在js内生成PDF文件并下载的功能实现(不调用后端),以及生成pdf时换行的格式不被渲染,word-break:break-all
在js内生成PDF文件并下载的功能实现(不调用后端),以及生成pdf时换行的格式不被渲染,word-break:break-all 前天来了个新需求, 有一个授权书的文件要点击下载, 需要在前端生成, ...
- Itext生成pdf文件
来源:https://my.oschina.net/lujianing/blog/894365 1.背景 在某些业务场景中,需要提供相关的电子凭证,比如网银/支付宝中转账的电子回单,签约的电子合同等. ...
- Java 动态生成 PDF 文件
每片文章前来首小诗: 今日夕阳伴薄雾,印着雪墙笑开颜.我心仿佛出窗前,浮在半腰望西天. --泥沙砖瓦浆木匠 需求: 项目里面有需要java动态生成 PDF 文件,提供下载.今天我找了下有关了,系 ...
- JavaWeb项目生成PDF文件添加水印图片并导出
一.前言 首先需要在Maven中添加相应的jar包依赖,若项目没用到Maven,也可自行下载相应所需的jar包(itextpdf.jar 与 itext-asian.jar),如下图所示.点此下载 M ...
- Java生成PDF文件(转)
原文地址:https://www.cnblogs.com/shuilangyizu/p/5760928.html 一.前言 前几天,做ASN条码收货模块,需要实现打印下载收货报表,经一番查找,选定iT ...
- [itext]Java生成PDF文件
一.前言 最近在做也导出试卷的功能,刚开始是导出为doc,可是导出来格式都有变化,最后说直接将word转为pdf,可是各种不稳定,各种报错.最后想到直接将文件写入pdf(参考:http://www.c ...
- springMVC生成pdf文件
pom.xml文件配置=== <!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf --> <dependenc ...
- [轉載]史上最强php生成pdf文件,html转pdf文件方法
之前有个客户需要把一些html页面生成pdf文件,然后我就找一些用php把html页面围成pdf文件的类.方法是可谓是找了很多很多,什么html2pdf,pdflib,FPDF这些都试过了,但是都没有 ...
- 怎么用PHP在HTML中生成PDF文件
原文:Generate PDF from html using PHP 译文:使用PHP在html中生成PDF 译者:dwqs 利用PHP编码生成PDF文件是一个非常耗时的工作.在早期,开发者使用PH ...
随机推荐
- 9.5、zabbix高级操作(1)
在zabbix-web中删除之前所有监控的主机: 1.zabbix自动发现配置: zabbix-server通过扫描指定范围的ip地址发现zabbix-agent并自动添加监控主机,适用于zabbix ...
- 4、oracle表操作
4.1.dml操作: 1.查看当前用户下所有的表: select * from user_tables; 2.查看某表的大小: select sum(bytes)/(1024*1024) as &qu ...
- (C++)戳西瓜
写在前面的话: 请不要吝啬你的点赞!!! 题目描述 有 n 个西瓜,编号为0 到 n-1,每个西瓜上都标有一个数字,这些数字存在数组 nums 中. 现在要求你戳破所有的西瓜.每当你戳破一个西瓜 i ...
- 同步工具——Exchanger
本博客系列是学习并发编程过程中的记录总结.由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅. 并发编程系列博客传送门 本文是转载文章,原文请见这里 一.Exchanger简介 ...
- keycloak~OIDC&OAuth2&自定义皮肤
1 OpenID & OAuth2 & SAML 1.1 相关资料 https://github.com/keycloak/keycloak https://www.keycloak. ...
- 《汇编语言程序设计》(Professional Assembly Language)学习笔记(二)
挖坑:学习笔记(一)讲述如何在 Windows Vmware 上安装 Ubuntu 20.04 实践环境 本文是基于Ubuntu 20.04平台进行实验,下文中的解决方法都基于此前提 问题记录 问题一 ...
- Swoole实现毫秒级定时任务
项目开发中,如果有定时任务的业务要求,我们会使用linux的crontab来解决,但是它的最小粒度是分钟级别,如果要求粒度是秒级别的,甚至毫秒级别的,crontab就无法满足,值得庆幸的是swoole ...
- CG-CTF WxyVM
一. 之前一直以为虚拟机是那种vmp的强壳,下午看了一些文章才逐渐明白虚拟机这个概念,目前ctf中题目出现的都是在程序中相等于内嵌了一个虚拟机,将程序代码转换成自己定义的指令,通过内嵌的虚拟机进行解释 ...
- linux挂载光驱
挂载光驱到linux中.linux的镜像盘中有安装oracle的所有的软件包,可以会用yum一键安装. 1.此时的linux的界面显示光驱图标 2.挂载 因为光盘里面的文件是只读模式的,yum安装时不 ...
- Spring Boot入门学习必知道企业常用的Starter
SpringBoot企业常用的 starter SpringBoot简介 SpringBoot运行 SpringBoot目录结构 整合JdbcTemplate @RestController 整合JS ...