Realtime Data Processing at Facebook
概要
这篇论文发表于2016年,主要是介绍Facebook内部的流式计算平台的设计与思考,对于流式计算的关键特性的实现选型上进行深度对比分析。
流式计算系统5个衡量指标
文中提到有5个重要的考量部分
- 易用性。用户使用什么语言来开发,例如SQL,C++,Java,用户开发,测试,发布一个应用需要花费多久?
- 性能。时延需要达到什么级别?例如毫秒级,秒级,分钟级?吞吐量需要达到多少?在这一点上Facebook设计的流处理系统基本是为了应对秒级的延迟,这是一个大的前提
- 容错处理。什么样的故障能够自动容错处理?以及在容错处理时对数据是怎么样的语义,系统如何来存储和恢复内存的状态?
- 可扩展性。数据是否可以被切分来并行化处理?是否能够回刷老数据进行处理,系统对于数据分区的变化的调整的难易程度
- 正确性。是否需要提供ACID的保障
流式计算系统5个设计维度
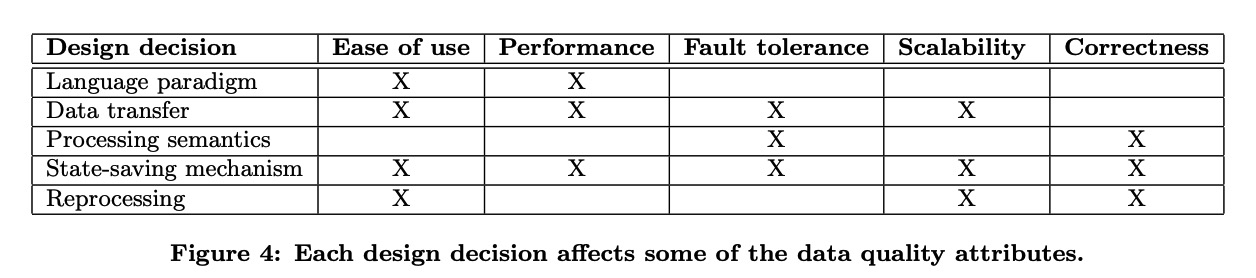
不同的维度对流式计算系统的不同评价维度所产生的影响
Language paradigm
语言范式通常的选择有以下几种
- Declarative。例如 SQL语言,SQL以其简单性和声明式著称,开发起来很快,但是SQL的一大缺点就是表达力偏弱,无法描述很复杂的逻辑
- Functional。这个意思是框架内部内置了一系列功能的算子,用户需要做的就是对这些算子进行编排组合,来描述业务逻辑
- Procedural。例如基于C++,Java, Python。 这些编程语言能够提供最灵活的实现以及更好的性能。app开发者能够完全掌控其中的数据结构以及运行时的逻辑。
语言范式的选择会影响系统的易用性和性能
考虑到没有一种语言能够适用各种场景的需求,因此在Facebook中提供了多种不同的计算引擎。例如Puma引擎是基于SQL编写,Swift基于Python编写,Stylus基于C++开发。从论文描述没法分清这几种不同的计算引擎的运行时是否是通用的,我理解理论上语言范式只是面向用户的api,真正的运行时应该是可以统一的。
Data Transfer
一个典型的流式计算任务通常会有几个计算节点组成,不同的计算节点之间就会需要进行数据传输,而数据传输会影响系统的容错处理,性能,可扩展性以及其易用性(是否易于debug)。
通常的实现方式有以下几种
- Direct message transfer。一般直接通过RPC或者基于内存的message queue,来将数据从一个进程发送到另一个进程。这种方式的一大优势就是快,可以实现10-100ms级别的端到端的延迟。
- Broker based message transfer。基于中间组件进行消息传递。也就是会起一组broker 进程,专门用于消息发送。增加一个中间人会带来额外的负担。但是在可扩展性上会带来一些好处。Broker可以进行多路复用,将一个上游发送给多个下游。当下游出现问题之后,可以对上游的算子进行反压
- Persistent storage based message transfer。两个processor之间通过持久化的消息队列进行连接。上游算子的数据直接写到消息队列中,而下游算子从消息队列中读取数据。除了可以实现多路复用,这种模式可以上下游的处理速度不一致,下游可以在不同的时间对上游的数据进行回放(例如在进行故障恢复期间)。这样不同的处理节点就和其他的节点就完全解耦了,你会发现不同的worker之间并不需要直接交互了,所以单个节点的失败并不会影响其他的worker。 这种方式听起来比较美妙,但是也会带来延迟的放大,因为数据会先写到消息队列,下游再从消息队列消费。Flink中Unaligned checkpoint将中间数据记录在本地就可以实现数据回放有点类似于这个方案中上下游解耦的机制。
在Facebook采用的是第三种方式,基于Scribe的持久化的消息队列,据Facebook的数据是使用这种方式会带来1s左右的延迟per stream。我理解如果串联的节点变多,整体的时延就会放大很多。一个典型的pipeline就如下图所示,不同的节点之间都通过Scribe来发送数据
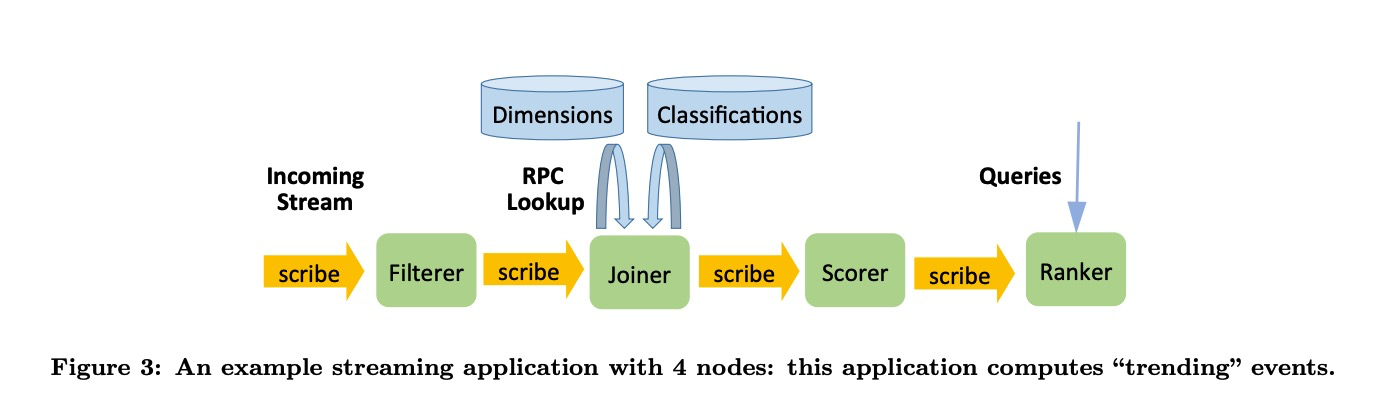
采用持久化消息队列作为数据传输的方式主要有以下的优点
- Fault tolerance。 在大规模的Streaming job中,不同的算子之间能够借助持久化消息队列来保持独立性,是非常有用的一种属性
- Fault tolerance。可以非常快速从错误和失败中恢复,因为只需要替换那些失败的节点
- Fault tolerance。多路复用的能力可以让我们跑一些备用链路,这样在处理链路上就可以有一些冗余
- Performance。如果有些节点处理的比较慢,并不会影响他的上游节点。而像一些内嵌的数据传输的实现中,这样的节点就会导致上游产生反压。任务的峰值吞吐取决于整个pipeline中的最慢的节点
- Ease of use。这种方式下debugging会更方便,当观察到某个节点产生了错误数据时,可以通过创建一个新的计算节点来回放这个上游的数据来复现和debug相应的问题。
- Ease of use。监控和报警也变得更加简单,只需要监控每个节点消费上游数据的延迟就可以反应任务的运行情况
- Ease of use。在任务编排上有了更大的灵活性,可以通过消息队列将其内部的各种流计算的引擎以及存储打通
- Scalability。可以通过配置比较方便的去调整消息队列的partition的大小
主要的缺点
- 延迟会变大,如果串联的节点比较多,时延会放大更多
- 如果写消息队列只保障at least once, 那么在failover的过程中会产生比较多的重复数据 (这个论文中没有提及,但是我任务会带来这种问题)
- 会带来额外的网络和存储开销
- 另外我认为这种持久化存储应该保存的数据结构和计算中流转的数据结构一致,避免多次序列化和反序列化的过程
Processing semantics
文中提到,一个算子主要会有三种类型的活动
- 处理输入数据,可能包含反序列化输入数据,查询外部系统,更新内存中的状态。这样的流程被认为是一次没有副作用的处理
- 产生输出数据。基于输入数据和内存中的状态,会下发数据提供下游所使用
- 将checkpoint保存到db中,用于failover故障恢复
文中还提到一个算子主要会包含两个处理语义
- State semantics 以计数来举例,表示是否每条数据只会被count at-least-once, at-most-once, exactly-once
- Output semantics 以某条输出数据为例,在下游中是否出现 at-least-once, at-most-once, exactly-once
State semantics
无状态的算子只有output semantics。有状态的算子会包含这两种语义。 状态语义取决于保存offset 和 保存 内存状态的顺序
- At-least-once state semantics: 先保存内存状态,然后保存offset
- At-most-once state semantics: 先保存offset,再保存内存状态
- Exactly-once state semantics: 原子化的实现保存内存状态和offset 例如在一个事务中完成
Output semantics
输出语义取决于下发数据 和 保存offset 及内存状态的顺序
- At-least-once output semantics:首先下发数据,然后保存offset 和 state
- At-most-once output semantics:先保存offset 和 state,然后下发数据
- Exactly-once output semantics: 在一个事务中完成保存offset 和 state,以及下发数据。
Facebook中的流计算和存储组件大部分只提供了At-least-once的语义,没有提供事务的功能,不知道其内部对于各个Scribe节点连接的计算节点有没有去重功能,如果没有,一旦有节点发生失败,数据都有可能会发生重复。
State-saving mechanisms
可选项:
- Replication: 有状态的节点被复制多份,来保障状态的可靠性
- Local database persistence。例如Samza将状态保存到local database中,并且将变化量写入kafka,再失败后数据从kafka中恢复,因为kafka没有事务特性,所以其只能支持at lease once语义
- Remote database persistence。checkpoint和state直接存储在远程的db中例如MillWheel。只要远程db能有事务特性,就能够实现exactly once的语义
- Upstream backup。数据在上游缓存,当出现失败后就回放上游的数据
- Global consistent snapshot。Flink采用的就是这种分布式快照的算法来维护全局的一致性snapshot。出现异常后,所有的节点恢复到一致的状态点位
在Facebook的Stylus中实现了local database 和 remote database的引擎。在local database的版本中也是直接保存到RocksDB中,按文中的介绍是定期的将内存数据保存到rocksdb中,在以一个更大的间隔,将本地数据异步的拷贝到HDFS。当进程挂掉后,首先会尝试在原机器上重新启动,那么先前的状态就可以被用来继续恢复状态,如果机器挂了,就会从远程的HDFS上恢复数据。(看起来这个描述并没有做一致性的快照)
Facebook中也使用了Remote database的方案Remote database的一个好处就是可以有更快的failover的时长,因为在重启的时候,无需将全量的状态数据加载到机器上。在这其中还提到,绝大部分的状态操作是Read-and-modify的操作。正常的操作需要将数据读取,在修改再写回。但是如果远程的db能够支持merge操作,那么性能就可以得到大大的提升(这个是否有点类似于计算下推到存储层?)。因为这样带来的效果是可以将Read-and-modify的操作转变为append-only的操作。但是是否所有的操作都可以进行这样的转化?
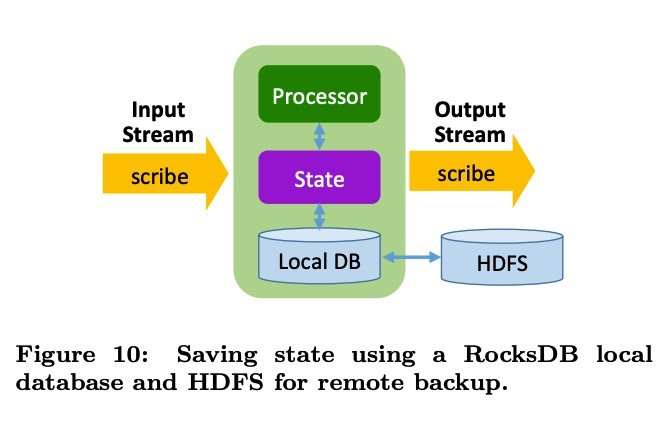
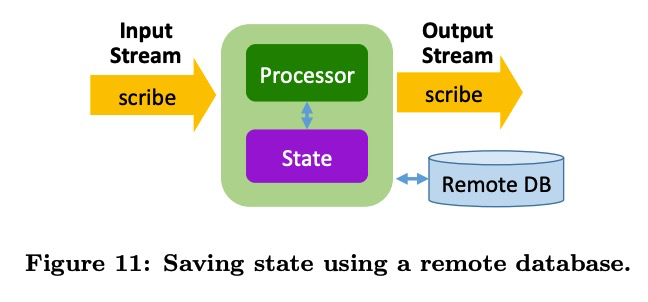
Backfill processing
有很多场景会需要Reprocessing old data,例如
- 当用户开发了一个新的任务,一个比较好的模式是可以基于老数据进行完成的回归测试
- 当添加一个新的指标后,能够基于老数据产出相应的历史曲线
- 当查到过去数据产出的bug,在修复bug后需要重跑相应的数据来进行回填
当有这种Reprocess的需求的时候,通常有以下几种选择
- Stream only。需要上游的消息队列保存足够长时间的历史数据
- Maintain two separate system, 一个跑batch 一个跑stream。为了回归跑历史数据,就拉起批任务去回归。这个模式的主要挑战是两套系统的一致性问题很难解决
- Develop stream processing systems can also run in a batch environment. Spark 和 Flink都是走的这种路线,也是Facebook采取的方式
Facebook中使用Scribe保存短期的消息队列的数据,长期的数据保存在基于Hive构建的数仓中。论文中指出Flink和Spark使用了相似的数据传输和容错方式来处理批和流(这一点是不太成立的Flink的流和批的运行时已经有很大的不同特别是shuffle方式和容错)。
在Facebook中处理Reprocess场景时是基于MapReduce的模型来处理,从Hive中读取数据,然后在批的环境中跑流式的app。具体是指,
Puma的应用在Hive环境中运行时,是作为Hive的udf运行,Puma应用的代码不用改变
Stylus则提供了3种算子1)无状态的算子 2)有状态的算子 3)monoid的算子 当用户开发了一个Stylus应用,就会产生两个binary,一个是流式的一个是批的。 无状态算子的批的实现是一个custom mapper。 有状态算子的批的实现是一个custom reducer。monoid算子的批的实现是map 的partial 聚合。
通过这种方式相当于用户写一套代码,就可以实现既可以跑批也可以跑流。
以下
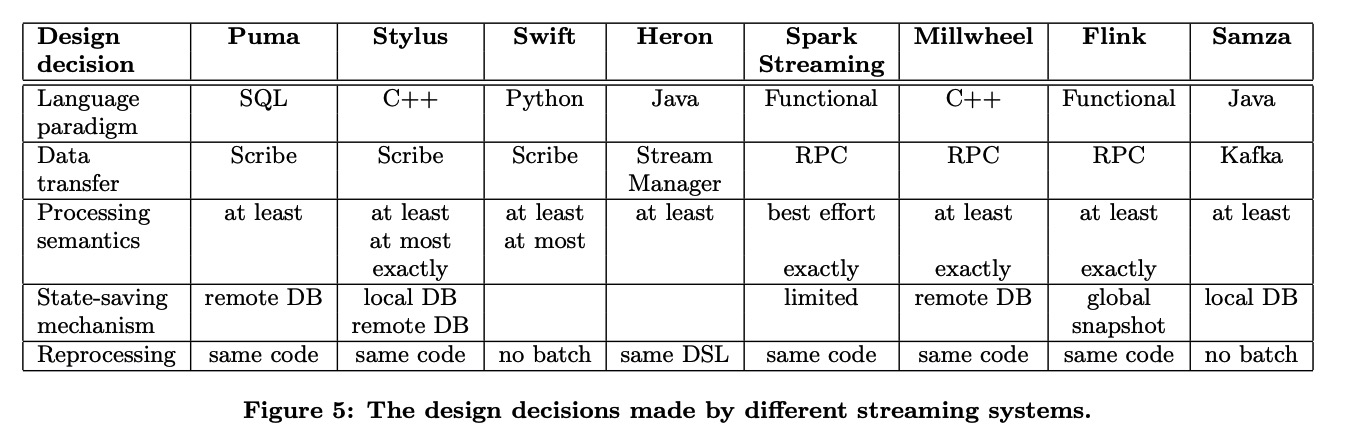
不同的设计维度横向对比其他流式引擎的实现
反思
特别提出的是对于易用性的要求,易用性不只是开发应用要简单,测试,debug,部署,监控都要考虑其易用性。
Multiple systems let us “move fast”
Providing a set of systems at different points in the ease of use versus performance, fault tolerance, and scalability space has worked well in Facebook’s culture of "move fast" and "iterate"
其中还提到用户可能会先基于Puma快速开发一些原型来证明其价值,然后等到有性能 要求的时候再去用Stylus实现更高的性能,并且由于基于Scribe解耦,在替换的过程中只需要挨个替换相应的组件不会牵一发而动全身
Ease of Debugging/Ease of Deploying/Ease of monitoring and operation
这几点在论文开头就着重提及了,可见其对于易用性的追求。
One lesson is to place emphasis on ease of use: not just on the ease of writing applications, but also on the ease of testing, debugging, deploying, and finally monitoring hundreds of applications in production.
Streaming vs batch processing
Streaming versus batch processing is not an either/or decision. Furthermore, streaming-only systems can be authoritative. We do not need to treat realtime system results as an approximation and batch results as the "truth."
参考
论文链接:https://pages.cs.wisc.edu/~shivaram/cs744-readings/Facebook-Streaming.pdf
Facebook 在2021 FlinkForward上的 分享 XStream: Stream Processing Platform at Facebook
Realtime Data Processing at Facebook的更多相关文章
- Flink应用案例:How Trackunit leverages Flink to process real-time data from industrial IoT devices
January 22, 2019Use Cases, Apache Flink Lasse Nedergaard Recently there has been significant dis ...
- The Log: What every software engineer should know about real-time data's unifying abstraction
http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-abo ...
- In-Stream Big Data Processing
http://highlyscalable.wordpress.com/2013/08/20/in-stream-big-data-processing/ Overview In recent y ...
- 分布式Streaming Data Processing - Samza
现在的主流的互联网应用越来越依赖streaming data来提供用户一些interesting statistics insights.以linkedin为例,最近90天有多少人看过你的link ...
- [翻译]MapReduce: Simplified Data Processing on Large Clusters
MapReduce: Simplified Data Processing on Large Clusters MapReduce:面向大型集群的简化数据处理 摘要 MapReduce既是一种编程模型 ...
- SQL Server Reporting Services 自定义数据处理扩展DPE(Data Processing Extension)
最近在做SSRS项目时,遇到这么一个情形:该项目有多个数据库,每个数据库都在不同的服务器,但每个数据库所拥有的数据库对象(table/view/SPs/functions)都是一模一样的,后来结合网络 ...
- Lifetime-Based Memory Management for Distributed Data Processing Systems
Lifetime-Based Memory Management for Distributed Data Processing Systems (Deca:Decompose and Analyze ...
- Linux command line exercises for NGS data processing
by Umer Zeeshan Ijaz The purpose of this tutorial is to introduce students to the frequently used to ...
- SQL Server Reporting Service(SSRS) 第五篇 自定义数据处理扩展DPE(Data Processing Extension)
最近在做SSRS项目时,遇到这么一个情形:该项目有多个数据库,每个数据库都在不同的服务器,但每个数据库所拥有的数据库对象(table/view/SPs/functions)都是一模一样的,后来结合网络 ...
随机推荐
- SYCOJ1613递归函数
题目-递归函数 (shiyancang.cn) 记忆化dfs,注意dp的限制范围 #include<bits/stdc++.h> using namespace std; const in ...
- promise初体验,小白也能看懂
promise出现的目的一为处理JavaScript里的异步,再就是避免回调地狱. promise有三种状态:pending/reslove/reject . pending就是未决,resolve可 ...
- elasticsearch拼写纠错之Term Suggester
一.什么是拼写纠错 拼写纠错就是搜索引擎可以智能的感知用户输入关键字的错误,并使用纠正过的关键字进行搜索展示给用户:拼写纠错是一种改善用户体验的功能: elasticsearch提供了以下不同类型的s ...
- 更快的Maven构建工具mvnd和Gradle哪个更快?
Maven 作为经典的项目构建工具相信很多人已经用很久了,但如果体验过 Gradle,那感觉只有两个字"真香". 前段时间测评了更快的 Maven 构建工具 mvnd,感觉性能挺高 ...
- 进程池与线程池基本使用、协程理论与实操、IO模型、前端、BS架构、HTTP协议与HTML前戏
昨日内容回顾 GIL全局解释器锁 1.在python解释器中 才有GIL的存在(只与解释器有关) 2.GIL本质上其实也是一把互斥锁(并发变串行 牺牲效率保证安全) 3.GIL的存在 是由于Cpyth ...
- Go 常用函数
#### Go 常用函数,错误处理这一节我们来学习一下Go 常用的函数,这些函数有些是内置的,有些是官方标准库内的, 熟悉这些函数对程序开发来讲还是很重要的; 1. len("abc&quo ...
- 集合框架-Vector集合
1 package cn.itcast.p1.vector.demo; 2 3 import java.util.Enumeration; 4 import java.util.Iterator; 5 ...
- Sweetalert模态对话框与Swiper轮播插件、Bootstrap样式组件、AdminLTE后台管理模板地址
Sweetalert纯JS模态对话框插件地址:http://mishengqiang.com/sweetalert/ AdminLTE后台管理模板系统地址(基于Bootstrap):https://a ...
- springboot 的运行原理?
一.@SpringbootApplicaion 是一个组合注解? 在注解中点击查看. 作用:实现自动配置. /* * springboot的运行原理 1. @SpringbootApplicatio ...
- spring 定时任务?
一.什么是定时任务? 我们在项目中遇到的需求: 需要定时送异步请求. 二.怎么实现? 2.1 mvc中启用定时任务. <?xml version="1.0" encodin ...