☕【Java技术指南】「并发原理专题」AQS的技术体系之CLH、MCS锁的原理及实现
背景
SMP(Symmetric Multi-Processor)
对称多处理器结构,它是相对非对称多处理技术而言的、应用十分广泛的并行技术。
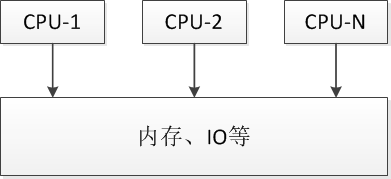
- 在这种架构中,一台计算机由多个CPU组成,并共享内存和其他资源,所有的CPU都可以平等地访问内存、I/O和外部中断。
- 虽然同时使用多个CPU,但是从管理的角度来看,它们的表现就像一台单机一样。
- 操作系统将任务队列对称地分布于多个CPU之上,从而极大地提高了整个系统的数据处理能力。
- 但是随着CPU数量的增加,每个CPU都要访问相同的内存资源,共享资源可能会成为系统瓶颈,导致CPU资源浪费。
NUMA(Non-Uniform Memory Access)
非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问。
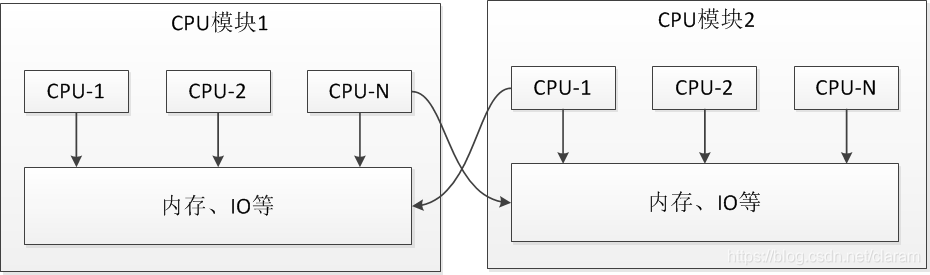
访问本地内存(本CPU模块的内存)的速度将远远高于访问远程内存(其他CPU模块的内存)的速度,这也是非一致存储访问的由来。
NUMA较好地解决SMP的扩展问题,当CPU数量增加时,因为访问远地内存的延时远远超过本地内存,系统性能无法线性增加。
CLH锁
CLH是一种基于单向链表的高性能、公平的自旋锁。申请加锁的线程通过前驱节点的变量进行自旋。在前置节点解锁后,当前节点会结束自旋,并进行加锁。
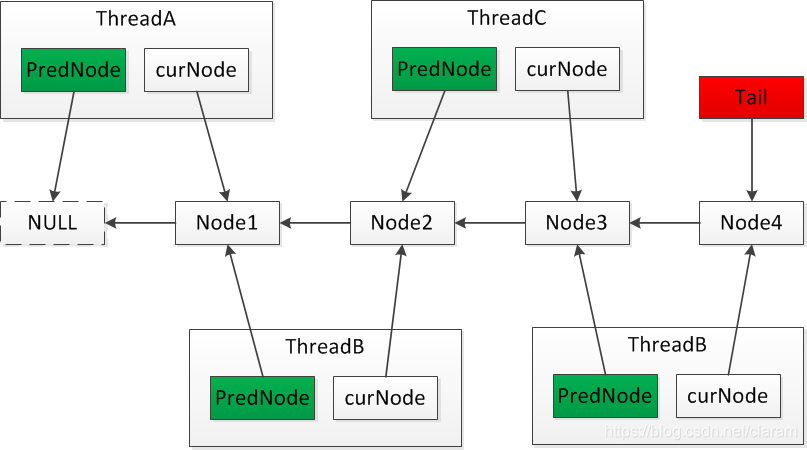
- 在SMP架构下,CLH更具有优势。
- 在NUMA架构下,如果当前节点与前驱节点不在同一CPU模块下,跨CPU模块会带来额外的系统开销,而MCS锁更适用于NUMA架构。
加锁逻辑
获取当前线程的锁节点,如果为空,则进行初始化;
同步方法获取链表的尾节点,并将当前节点置为尾节点,此时原来的尾节点为当前节点的前置节点。
如果尾节点为空,表示当前节点是第一个节点,直接加锁成功。
如果尾节点不为空,则基于前置节点的锁值(locked==true)进行自旋,直到前置节点的锁值变为false。
解锁逻辑
获取当前线程对应的锁节点,如果节点为空或者锁值为false,则无需解锁,直接返回;
同步方法为尾节点赋空值,赋值不成功表示当前节点不是尾节点,则需要将当前节点的locked=false解锁节点。如果当前节点是尾节点,则无需为该节点设置。
public class CLHLock {
private final AtomicReference<Node> tail;
private final ThreadLocal<Node> myNode;
private final ThreadLocal<Node> myPred;
public CLHLock() {
tail = new AtomicReference<>(new Node());
myNode = ThreadLocal.withInitial(() -> new Node());
myPred = ThreadLocal.withInitial(() -> null);
}
public void lock(){
Node node = myNode.get();
node.locked = true;
Node pred = tail.getAndSet(node);
myPred.set(pred);
while (pred.locked){}
}
public void unLock(){
Node node = myNode.get();
node.locked=false;
myNode.set(myPred.get());
}
static class Node {
volatile boolean locked = false;
}
}
MCS锁
MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同:CLH是在前趋结点的locked域上自旋等待,而MCS是在自己的结点的locked域上自旋等待。正因为如此,它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题。
MCS锁具体实现规则:
a. 队列初始化时没有结点,tail=null
b. 线程A想要获取锁,将自己置于队尾,由于它是第一个结点,它的locked域为false
c. 线程B和C相继加入队列,a->next=b,b->next=c,B和C没有获取锁,处于等待状态,所以locked域为true,尾指针指向线程C对应的结点
d. 线程A释放锁后,顺着它的next指针找到了线程B,并把B的locked域设置为false,这一动作会触发线程B获取锁。
public class MCSLock {
private final AtomicReference<Node> tail;
private final ThreadLocal<Node> myNode;
public MCSLock() {
tail = new AtomicReference<>();
myNode = ThreadLocal.withInitial(() -> new Node());
}
public void lock() {
Node node = myNode.get();
Node pred = tail.getAndSet(node);
if (pred != null) {
node.locked = true;
pred.next = node;
while (node.locked) {
}
}
}
public void unLock() {
Node node = myNode.get();
if (node.next == null) {
if (tail.compareAndSet(node, null)) {
return;
}
while (node.next == null) {
}
}
node.next.locked = false;
node.next = null;
}
class Node {
volatile boolean locked = false;
Node next = null;
}
public static void main(String[] args) {
MCSLock lock = new MCSLock();
Runnable task = new Runnable() {
private int a;
@Override
public void run() {
lock.lock();
for (int i = 0; i < 10; i++) {
a++;
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(a);
lock.unLock();
}
};
new Thread(task).start();
new Thread(task).start();
new Thread(task).start();
new Thread(task).start();
}
}
☕【Java技术指南】「并发原理专题」AQS的技术体系之CLH、MCS锁的原理及实现的更多相关文章
- ☕【Java技术指南】「并发编程专题」Fork/Join框架基本使用和原理探究(基础篇)
前提概述 Java 7开始引入了一种新的Fork/Join线程池,它可以执行一种特殊的任务:把一个大任务拆成多个小任务并行执行. 我们举个例子:如果要计算一个超大数组的和,最简单的做法是用一个循环在一 ...
- ☕【Java技术指南】「并发编程专题」CompletionService框架基本使用和原理探究(基础篇)
前提概要 在开发过程中在使用多线程进行并行处理一些事情的时候,大部分场景在处理多线程并行执行任务的时候,可以通过List添加Future来获取执行结果,有时候我们是不需要获取任务的执行结果的,方便后面 ...
- ☕【Java技术指南】「并发编程专题」针对于Guava RateLimiter限流器的入门到精通(含实战开发技巧)
并发编程的三剑客 在开发高并发系统时有三剑客:缓存.降级和限流. 缓存 缓存的目的是提升系统访问速度和增大系统处理容量. 降级 降级是当服务出现问题或者影响到核心流程时,需要暂时屏蔽掉,待高峰或者问题 ...
- 🏆【Java技术专区】「并发编程专题」教你如何使用异步神器CompletableFuture
前提概要 在java8以前,我们使用java的多线程编程,一般是通过Runnable中的run方法来完成,这种方式,有个很明显的缺点,就是,没有返回值.这时候,大家可能会去尝试使用Callable中的 ...
- ☕【Java深层系列】「并发编程系列」让我们一起探索一下CyclicBarrier的技术原理和源码分析
CyclicBarrier和CountDownLatch CyclicBarrier和CountDownLatch 都位于java.util.concurrent这个包下,其工作原理的核心要点: Cy ...
- ☕【Java深层系列】「并发编程系列」深入分析和研究MappedByteBuffer的实现原理和开发指南
前言介绍 在Java编程语言中,操作文件IO的时候,通常采用BufferedReader,BufferedInputStream等带缓冲的IO类处理大文件,不过java nio中引入了一种基于Mapp ...
- ☕【Java技术指南】「JPA编程专题」让你不再对JPA技术中的“持久化型注解”感到陌生了!
JPA的介绍分析 Java持久化API (JPA) 显著简化了Java Bean的持久性并提供了一个对象关系映射方法,该方法使您可以采用声明方式定义如何通过一种标准的可移植方式,将Java 对象映射到 ...
- 🏆【Java技术专区】「探针Agent专题」Java Agent探针的技术介绍(1)
前提概要 Java调式.热部署.JVM背后的支持者Java Agent: 各个 Java IDE 的调试功能,例如 eclipse.IntelliJ : 热部署功能,例如 JRebel.XRebel. ...
- 🏆【Java技术专区】「延时队列专题」教你如何使用【精巧好用】的DelayQueue
延时队列前提 定时关闭空闲连接:服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之. 定时清除额外缓存:缓存中的对象,超过了空闲时间,需要从缓存中移出. 实现任务超时处理:在网络协议滑动窗口请求 ...
随机推荐
- 13 shell while循环与until循环
while 循环是 Shell 脚本中最简单的一种循环,当条件满足时,while 重复地执行一组语句,当条件不满足时,就退出 while 循环. unti 循环和 while 循环恰好相反,当判断条件 ...
- 从GAN到WGAN的来龙去脉
一.原始GAN的理论分析 1.1 数学描述 其实GAN的原理很好理解,网络结构主要包含生成器 (generator) 和鉴别器 (discriminator) ,数据主要包括目标样本 \(x_r \s ...
- ARTS第六周
第六周.后期补完,太忙了. 1.Algorithm:每周至少做一个 leetcode 的算法题2.Review:阅读并点评至少一篇英文技术文章3.Tip:学习至少一个技术技巧4.Share:分享一篇有 ...
- CVE-2017-12615 Tomcat远程代码执行
影响版本: Apache Tomcat 7.0.0 - 7.0.81 ps:安装Tomcat需要安装jdk(JAVA环境) 下面来正经复现,Payload: 利用burpsuite 进行抓包 发送到r ...
- Pandas高级教程之:window操作
目录 简介 滚动窗口 Center window Weighted window 加权窗口 扩展窗口 指数加权窗口 简介 在数据统计中,经常需要进行一些范围操作,这些范围我们可以称之为一个window ...
- python使用笔记009--小练习
1.密码生成器 1 ''' 2 1.写一个生产密码的程序,输入几,就产生几条密码,密码产生的不重复. 3 要求密码:长度6-12,密码必须包含 大写字母.小写字母.数字 4 产生完密码后存到一个文件里 ...
- 关于hive的基础
Hive基础 1.引入原因 对存在HDFS上的文件或HBase中的表进行查询时,是要手工写一堆MapReduce代码 对于统计任务,只能由懂MapReduce的程序员才能搞定 事实上,许多底层细节实际 ...
- 微信小程序云开发-数据库-商品列表数据显示N条数据
一.wxml文件 在wxml文件中,写页面和点击事件,添加绑定事件limitGoods 二.js文件 在js文件中写limitGoods(),使用.limit(3)表示只显示3条数据
- vue(23)Vuex的5个核心概念
Vuex的核心概念 Vuex有5个核心概念,分别是State,Getters,mutations,Actions,Modules. State Vuex使用单一状态树,也就是说,用一个对象包含了所 ...
- ThinkPHP3.2.3使用PHPExcel类操作excel导出excel
如何导入excel请看:ThinkPHP3.2.3使用PHPExcel类操作excel导入读取excel // 引入PHPExcel类 import("Org.Util.PHPExccel& ...