xml数据结构处理
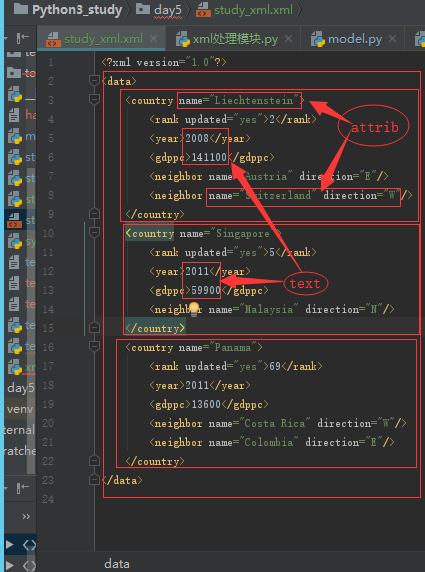
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
XML文件处理,循环遍历取值
import xml.etree.ElementTree as ET
tree = ET.parse('study_xml.xml') #使用parse方法解析这个xml文件
root = tree.getroot() #找到这个解析后的格式化内存地址
# print(root,root.tag) #打印内存地址和标签,tag标签就是大标签
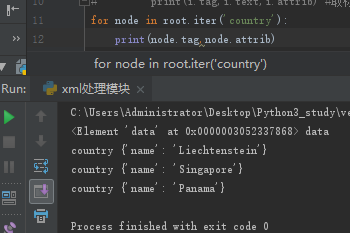
for child in root: #循环取第二层标签内存地址
print(child.tag,child.attrib) #打印标签和属性
for i in child : #再循环第二层标签内存地址
print(i.tag,i.text,i.attrib) #取标签,文本内容和属性(属性就是标签上面 又定义的键值对)

取特定键值对:
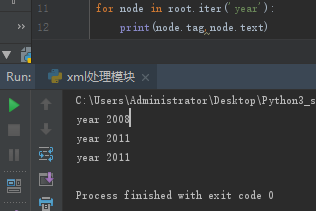
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
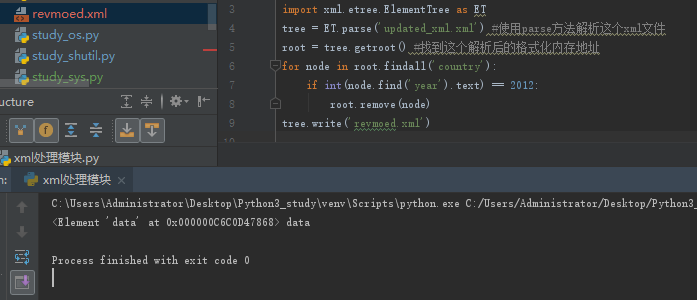
import xml.etree.ElementTree as ETtree = ET.parse("xmltest.xml")root = tree.getroot()#修改for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes")tree.write("xmltest.xml")#删除nodefor country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country)tree.write('output.xml') |
删除
自己创建xml文档
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import xml.etree.ElementTree as ETnew_xml = ET.Element("namelist")name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})age = ET.SubElement(name,"age",attrib={"checked":"no"})sex = ET.SubElement(name,"sex")sex.text = '33'name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})age = ET.SubElement(name2,"age")age.text = '19'et = ET.ElementTree(new_xml) #生成文档对象et.write("test.xml", encoding="utf-8",xml_declaration=True)ET.dump(new_xml) #打印生成的格式 |
xml数据结构处理的更多相关文章
- 数据解析(XML和JSON数据结构)
一 解析 二 XML数据结构 三 JSON 数据结构 一 解析 1 定义: 从事先规定好的格式中提取数据 解析的前提:提前约定好格式,数据提供方按照格式提供数据.数据获取方则按照 ...
- iOS-数据持久化基础-JSON与XML数据解析
解析的基本概念 所谓“解析”:从事先规定好的格式串中提取数据 解析的前提:提前约定好格式.数据提供方按照格式提供数据.数据获取方按照格式获取数据 iOS开发常见的解析:XML解析.JSON解析 一.X ...
- iOS - XML 数据解析
前言 @interface NSXMLParser : NSObject public class NSXMLParser : NSObject 1.XML 数据 XML(Extensible Mar ...
- iOS高级编程之XML,JSON数据解析
解析的基本概念 所谓“解析”:从事先规定好的格式串中提取数据 解析的前提:提前约定好格式.数据提供方按照格式提供数据.数据获取方按照格式获取数据 iOS开发常见的解析:XML解析.JSON解析 一.X ...
- 一个简单的XML与数组之间的转换
xml是网络使用最多的数据交换格式,所以,不掌握怎么操作它,又有蛋疼的了. php中可以操作xml的类/函数很多,个人认为最简单的是SimpleXMLElement这个类,它的使用就跟其名字一样:简单 ...
- UI进阶 解析XML 解析JSON
1.数据解析 解析的基本概念 所谓“解析”:从事先规定好的格式中提取数据 解析的前提:提前约定好格式,数据提供方按照格式提供数据.数据获取方则按照格式获取数据 iOS开发常见的解析:XML解析.JSO ...
- 【Java】Java XML 技术专题
XML 基础教程 XML 和 Java 技术 Java XML文档模型 JAXP(Java API for XML Parsing) StAX(Streaming API for XML) XJ(XM ...
- ios解析XML和json数据
解析的基本概念所谓“解析”:从事先规定好的格式串中提取数据解析的前提:提前约定好格式.数据提供方按照格式提供数据.数据获取方按照格式获取数据iOS开发常见的解析:XML解析.JSON解析 一.XML数 ...
- 数据解析之XML和JSON
1. 解析的基本的概念 解析:从事先规定好的格式中提取数据 解析前提:提前约定好格式,数据提供方按照格式提供数据.数据获取方则按照格式获取数据 iOS开发常见的解析:XML解析.JOSN解析 2. X ...
随机推荐
- 统计学习2:线性可分支持向量机(Scipy实现)
1. 模型 1.1 超平面 我们称下面形式的集合为超平面 \[\begin{aligned} \{ \bm{x} | \bm{a}^{T} \bm{x} - b = 0 \} \end{aligned ...
- js offset系列属性
offsetParent:返回该元素有定位的父级,如果父级都没有定位则返回body offsetTop:返回元素相对父级(带有定位的父级)上方的偏移 offsetLeft:返回元素相对父级(带有定位的 ...
- Codeforces 997D - Cycles in product(换根 dp)
Codeforces 题面传送门 & 洛谷题面传送门 一种换根 dp 的做法. 首先碰到这类题目,我们很明显不能真的把图 \(G\) 建出来,因此我们需要观察一下图 \(G\) 有哪些性质.很 ...
- GO 语言使用copy 拷贝切片的问题
使用copy,直接改变原片的值,而不是先创建一个副本.
- Redis篇:单线程I/O模型
关注公众号,一起交流,微信搜一搜: 潜行前行 redis 单线程 I/O 多路复用模型 纯内存访问,所有数据都在内存中,所有的运算都是内存级别的运算,内存响应时间的时间为纳秒级别.因此 redis 进 ...
- 日常Java 2021/10/30
Java泛型 Java泛型(generics)是JDK5中引入的一个新特性,泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型.泛型的本质是参数化类型,也就是说所操作的数据类型 ...
- day10设置文件权限
day10设置文件权限 yum复习 1.修改IP [root@localhost ~]# sed -i 's#.200#.50#g' /etc/sysconfig/network-scripts/if ...
- flink-----实时项目---day07-----1.Flink的checkpoint原理分析 2. 自定义两阶段提交sink(MySQL) 3 将数据写入Hbase(使用幂等性结合at least Once实现精确一次性语义) 4 ProtoBuf
1.Flink中exactly once实现原理分析 生产者从kafka拉取数据以及消费者往kafka写数据都需要保证exactly once.目前flink中支持exactly once的sourc ...
- ComponentScan注解的使用
在项目初始化时,会将加@component,@service...相关注解的类添加到spring容器中. 但是项目需要,项目初始化时自动过滤某包下面的类,不将其添加到容器中. 有两种实现方案, 1.如 ...
- redis安装与简单实用
1.在Linux上redis的安装时十分简单的: 第一步:wget http://download.redis.io/releases/redis-2.8.12.tar.gz 解压: tar zxvf ...