SparkSQL电商用户画像(三)之环境准备
五、 电商用户画像环境搭建
众所周知,Hive的执行任务是将hql语句转化为MapReduce来计算的,Hive的整体解决方案很不错,但是从查询提交到结果返回需要相当长的时间,查询耗时太长。这个主要原因就是由于Hive原生是基于MapReduce的,那么如果我们不生成MapReduce Job,而是生成Spark Job,就可以充分利用Spark的快速执行能力来缩短HiveHQL的响应时间。
本项目采用SparkSql与hive进行整合(spark on hive),通过SparkSql读取hive中表的元数据,把HiveHQL底层采用MapReduce来处理任务,导致性能慢的特点,改为更加强大的Spark引擎来进行相应的分析处理,快速的为用户打上标签构建用户画像。
5.1 环境准备
1、搭建hadoop集群
2、安装hive构建数据仓库
3、安装spark集群
4、sparksql 整合hive
5.2 sparksql整合hive
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是RDD,也可以是外部的数据源(比如文本、Hive、Json等)。Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。SparkSql整合hive就是获取hive表中的元数据信息,然后通过SparkSql来操作数据。
整合步骤:
① 需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置。
② 如果Hive的元数据存放在Mysql中,我们还需要准备好Mysql相关驱动,比如:mysql-connector-java-5.1.35.jar
5.3 测试sparksql整合hive是否成功
先启动hadoop集群,在启动spark集群,确保启动成功之后执行命令:
/var/local/spark/bin/spark-sql --master spark://itcast01:7077 --executor-memory 1g --total-executor-cores 4
指明master地址、每一个executor的内存大小、一共所需要的核数、
mysql数据库连接驱动。
执行成功后的界面:进入到spark-sql 客户端命令行界面
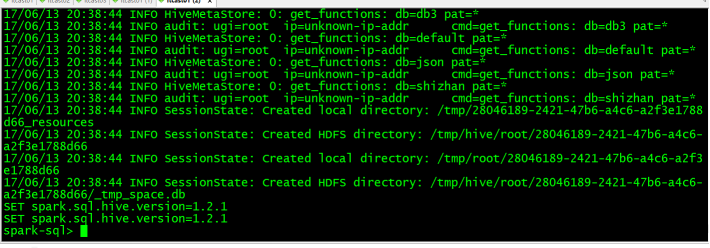
接下来就可以通过sql语句来操作数据库表:
查看当前有哪些数据库 ---show databases;
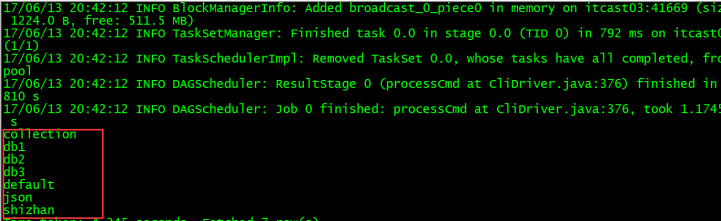
看到以上结果,说明sparksql整合hive成功!
日志太多,我们可以修改spark的日志输出级别(conf/log4j.properties)
前方高能:
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在哪里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据信息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
所有在启动的时候需要加上这样一个参数:
--conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录。
如果使用的是spark2.0之前的版本,由于没有sparkSession,不会有spark.sql.warehouse.dir配置项,不会出现上述问题。
最后的执行脚本;
spark-sql \ --master spark://node1:7077 \ --executor-memory 1g \ --total-executor-cores 2 \ --conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse
SparkSQL电商用户画像(三)之环境准备的更多相关文章
- SparkSQL电商用户画像(五)之用户画像开发(客户基本属性表)
7.电商用户画像开发 7.1用户画像--数据开发的步骤 u 数据开发前置依赖 -需求确定 pv uv topn -建模确定表结构 create table t1(pv int,uv int,topn ...
- SparkSQL电商用户画像(二)之如何构建画像
四. 如何构建电商用户画像 4.1 构建电商用户画像技术和流程 构建一个用户画像,包括数据源端数据收集.数据预处理.行为建模.构建用户画像 有些标签是可以直接获取到的,有些标签需要通过数据挖掘分析到! ...
- SparkSQL电商用户画像(四)之电商用户画像数据仓库建立
六. 电商用户画像数据仓库建立 7.1 数据仓库准备工作 为什么要对数据仓库分层?星型模型 雪花模型 User----->web界面展示指标表 l 用空间换时间,通过大量的预处理来提升 ...
- Flink SQL结合Kafka、Elasticsearch、Kibana实时分析电商用户行为
body { margin: 0 auto; font: 13px / 1 Helvetica, Arial, sans-serif; color: rgba(68, 68, 68, 1); padd ...
- Spark项目之电商用户行为分析大数据平台之(三)大数据集群的搭建
Zookeeper集群搭建 http://www.cnblogs.com/qingyunzong/p/8619184.html Hadoop集群搭建 http://www.cnblogs.com/qi ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- Spark项目之电商用户行为分析大数据平台之(六)用户访问session分析模块介绍
一.对用户访问session进行分析 1.可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄.职业.城市): 2.对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出 ...
- Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建
一.CentOS7集群搭建 1.1 准备3台centos7的虚拟机 IP及主机名规划如下: 192.168.123.110 spark1192.168.123.111 spark2192.168.12 ...
- Spark项目之电商用户行为分析大数据平台之(一)项目介绍
一.项目概述 本项目主要用于互联网电商企业中,使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.购物行为.广告点击行为等)进行复杂的分析.用统计分析出来的数据,辅助公司中 ...
随机推荐
- python plt画图横纵坐标0点重合
# -*- coding: utf-8 -*- import numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot a ...
- Flutter教程- Dart语言规范-知识点整理
Flutter教程- Dart语言知识点整理 Dart语言简介 Dart语言介绍 ① 注释的方式 ② 变量的声明 ③ 字符串的声明和使用 ④ 集合变量的声明 ⑤ 数字的处理 ⑥ 循环的格式 ⑦ 抛异常 ...
- Aibabelx-shop 大型微服务架构系列实战之技术选型
一.本项目涉及编程语言java,scala,python,涉及的技术如下: 1.微服务架构: springboot springcloud mybatisplus shiro 2.全文检索技术 sol ...
- rman全备脚本
cat rman_back.sh #!/bin/bash source /home/oracle/.bash_profile rman log=/u01/backup/backupall_rman ...
- 【关系抽取-R-BERT】定义训练和验证循环
[关系抽取-R-BERT]加载数据集 [关系抽取-R-BERT]模型结构 [关系抽取-R-BERT]定义训练和验证循环 相关代码 import logging import os import num ...
- (数据科学学习手札115)Python+Dash快速web应用开发——交互表格篇(上)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- Scrum完整项目实例
一.背景 在谈 JIRA 之前,就不得不说说敏捷开发了.正式由于项目是基于敏捷开发进行的,因此才引入了 JIRA 这款适合于敏捷开发的项目管理工具.当然,这里不会大篇章的介绍敏捷开发,之前的文章有详细 ...
- electron踩坑系列之一
前言 以electron作为基础框架,已经开发两个项目了.第一个项目,我主要负责用react写页面,第二项目既负责electron部分+UI部分. 做项目,就是踩坑, 一路做项目,一路踩坑,坑多不可怕 ...
- [SIGIR2020] Sequential Recommendation with Self-Attentive Multi-Adversarial Network
这篇论文主要提出了一个网络,成为Multi-Factor Generative Adversarial Network,直接翻译过来的话就是多因子生成对抗网络.主要是期望能够探究影响推荐的其他因子(因 ...
- 答应我,别在go项目中用init()了
前言 go的 init函数给人的感觉怪怪的,我想不明白聪明的 google团队为何要设计出这么一个"鸡肋"的机制.实际编码中,我主张尽量不要使用init函数. 首先来看看 init ...