YOLOv5模型训练及检测
一、为什么使用YOLOv5

二、软件工具
2.1 Anaconda
https://www.anaconda.com/products/individual
2.2 PyCharm
https://www.jetbrains.com/zh-cn/pycharm/download/
2.3 LabelImg
https://github.com/tzutalin/labelImg
三、图片标注
为了训练自己的数据集,需要将自己的图片及要识别的物体进行标注,俗称“打标签”,本文使用LabelImg工具对图像进行标注。
3.1 左侧工具栏
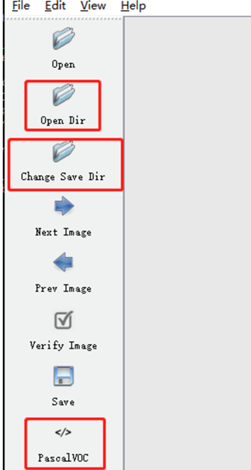
Open Dir:待标注图片数据的路径文件夹
Change Save Dir:保存类别标签的路径文件夹
PascalVOC:标注的标签保存成VOC格式
3.2 上方菜单栏
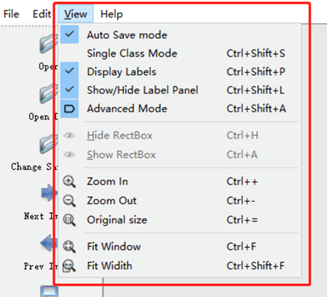
Auto Save mode:当你切换到下一张图片时,就会自动把上一张标注的图片标签自动保存下来,这样就不用每标注一样图片都按Ctrl+S保存一下了
Display Labels:标注好图片之后,会把框和标签都显示出来
Advanced Mode:这样标注的十字架就会一直悬浮在窗口,不用每次标完一个目标,再按一次W快捷键,调出标注的十字架。
3.3 其它快捷键:
W:调出标注的十字架,开始标注
A:切换到上一张图片
D:切换到下一张图片
Ctrl+S:保存标注好的标签
del:删除标注的矩形框
Ctrl+鼠标滚轮:按住Ctrl,然后滚动鼠标滚轮,可以调整标注图片的显示大小
Ctrl+U:选择要标注图片的文件夹
Ctrl+R:选择标注好的label标签存放的文件夹
↑→↓←:移动标注的矩形框的位置
3.4 标注样例

四、环境配置
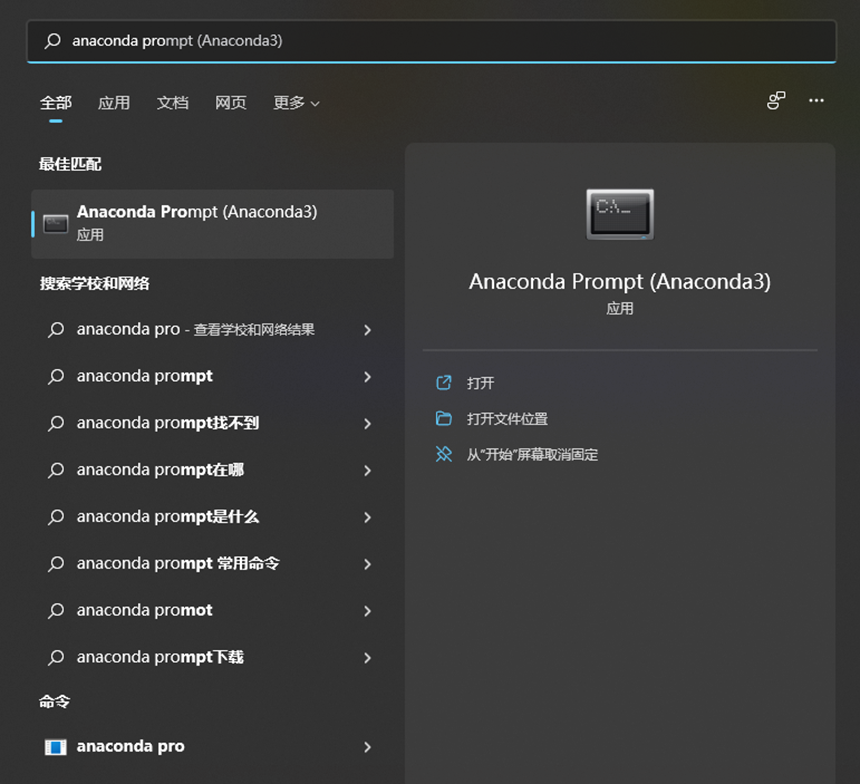
4.1 打开Anaconda Prompt
在安装好Anaconda之后,Win+S进入搜索框,搜索Anaconda Prompt,打开

4.2 创建PyTorch环境
输入指令:
conda create -n pytorch python=3.9
如出现提示询问“是否”,一律输入y,回车,即可。
其中“pytorch”为该环境名称,可改为任意名称,为方便起见,下文一律使用pytorch作为该环境名
4.3 使用PyTorch环境
输入命令:
conda activate pytorch
4.4 安装PyTorch
在使用pytorch环境后,进入PyTorch官网(PyTorch官网),选择自己电脑相应配置,下图为本机使用配置,可作为参考。注意Compute Platform查看好设备显卡是否支持CUDA以及支持版本。
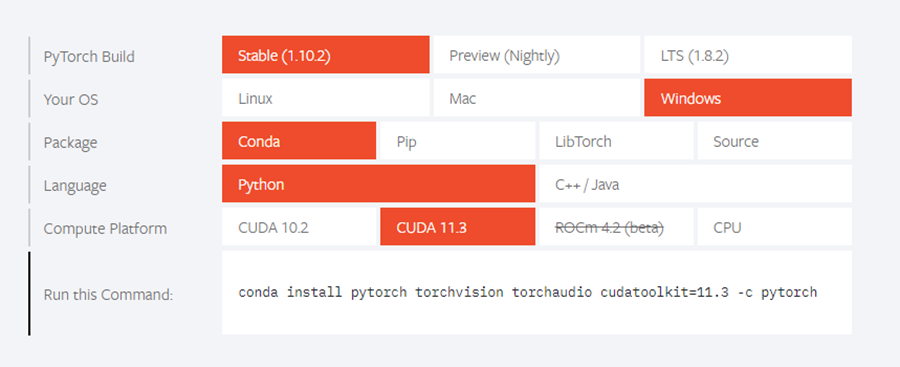
复制Run this Command中的命令到Anaconda Prompt中,回车,即可运行。如询问问题,一律选择y即可。
至此,环境配置安装完成。
五、YOLOv5代码
5.1 代码获取
进入GitHub上官方网页(ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite (github.com)。
点击左上角分支按钮,点击Tags,可以选择代码版本,本文使用v6.0
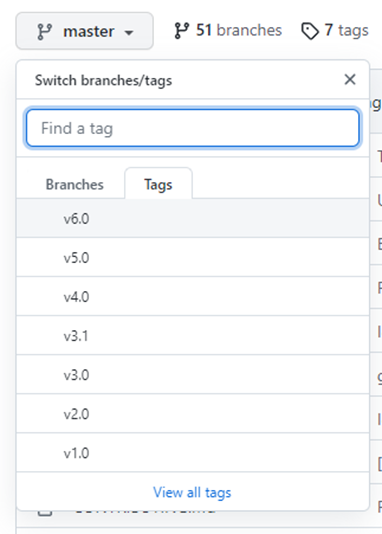
右上角点击点击Code → Download ZIP
解压后放在想要的项目文件夹中即可。
5.2 打开项目以及环境配置
右键项目文件夹→Open Folder as PyCharm Project
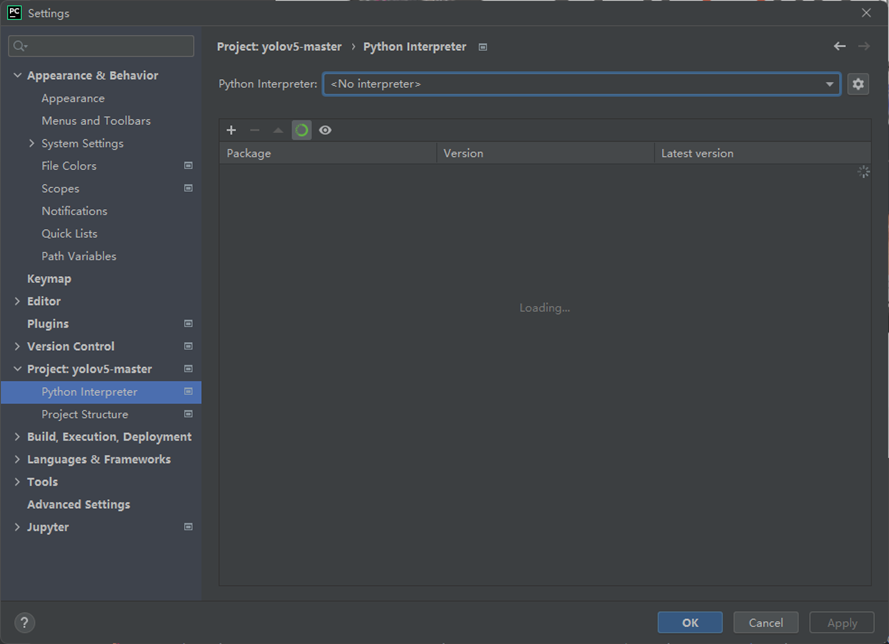
进入PyCharm后,左上角菜单栏选择File→Settings进入设置界面。找到Project:xxxx选项→Python Interpreter,下拉菜单选择环境。
如果没有选项,可以点击右侧齿轮图标,在Conda Environment→Existing environment中找到相应位置,选择编译器。
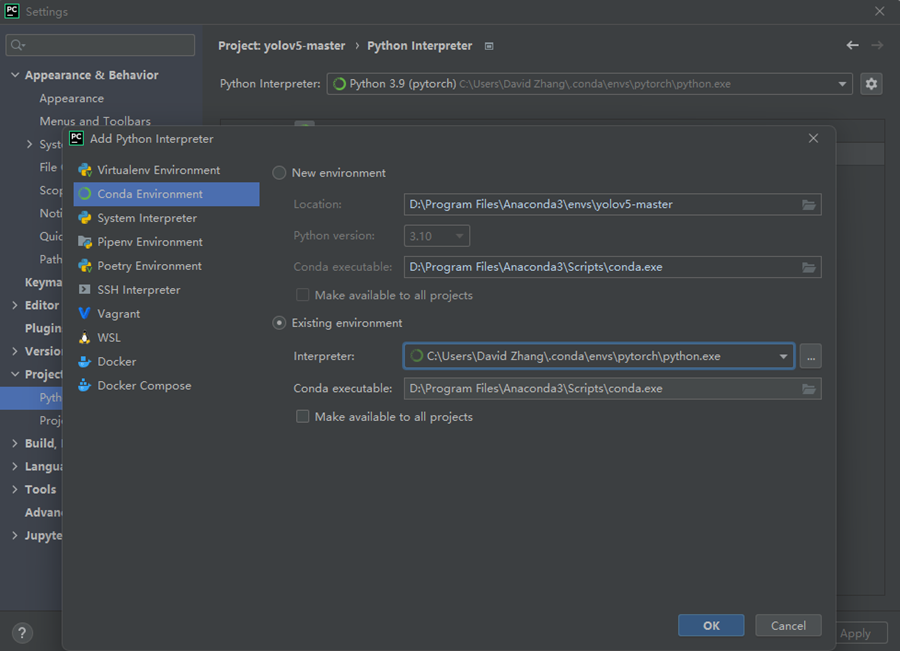
设置好后如图,然后点击Apply。

下方点击Terminal打开命令行窗口,输入指令:
conda activate pytorch
pip install -r requirements.txt
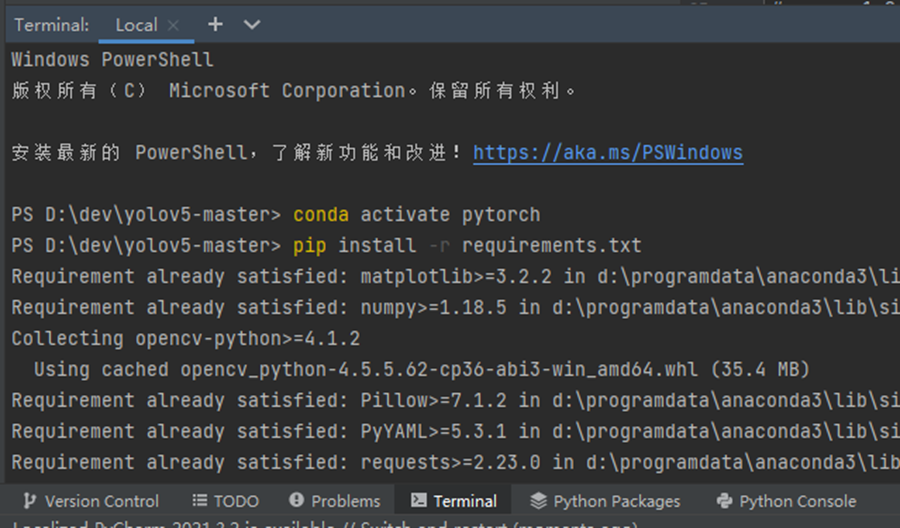
等待安装好所有所需文件即可。
5.3 代码文件
其中主要涉及到的两个文件,一个是train.py用于训练,一个是detect.py用于检测。
5.3.1 train.py
主要需要了解的是451行开始的parse_opt函数,代码如下
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
\# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
epochs:指的就是训练过程中整个数据集将被迭代多少次。
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高。
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
weights:权重文件路径
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
5.3.2 detect.py
其中需要了解的是第216行开始的parse_opt函数,代码如下:
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
weights:训练的权重
source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
output:网络预测之后的图片/视频的保存路径
img-size:网络输入图片大小
conf-thres:置信度阈值
iou-thres:做nms的iou阈值
device:设置设备
view-img:是否展示预测之后的图片/视频,默认False
save-txt:是否将预测的框坐标以txt文件形式保存,默认False
classes:设置只保留某一部分类别,形如0或者0 2 3
agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
augment:推理的时候进行多尺度,翻转等操作(TTA)推理
update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
六、训练自定义数据集
6.1 文件夹及数据准备
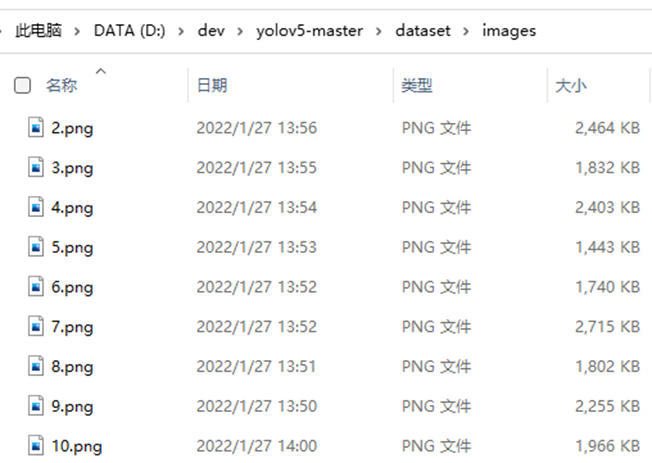
在项目文件夹中创建dataset文件夹

在dataset文件夹中创建三个文件夹:images,annotations,imagesets

将标注过的图片移入images文件夹
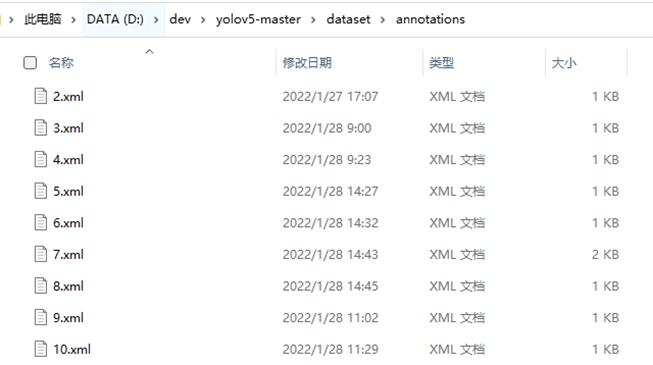
将标注生成的xml文件移入annotations文件夹
在imagesets文件夹中创建main文件夹
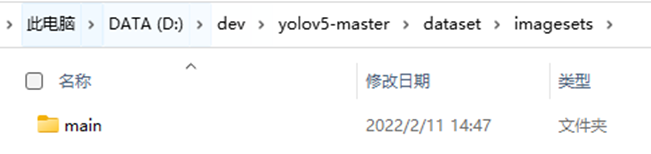
在dataset文件夹中创建python代码split_train_val.py:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='imagesets/main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
注意其中有些目录需要修改为自己计算机上对应目录
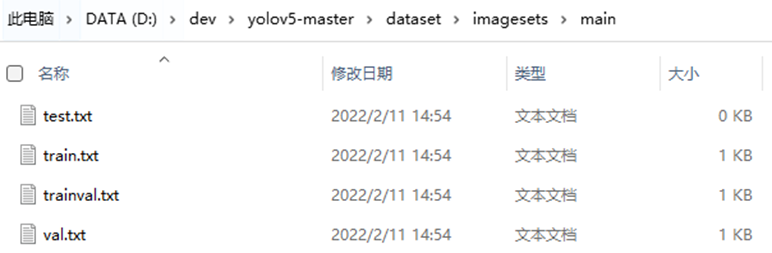
运行代码,会在main文件夹中自动生成如下四个文件:
6.2 准备标签文件
在dataset文件夹中新建python代码文件voc_label.py:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["hat", "no hat"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
#修改自己电脑上对应文件目录
in_file = open('D:/dev/yolov5-master/dataset/annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/dev/yolov5-master/dataset/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
#修改为自己电脑上对应目录
if not os.path.exists('D:/dev/yolov5-master/dataset/labels/'):
os.makedirs('D:/dev/yolov5-master/dataset/labels/')
image_ids = open('D:/dev/yolov5-master/dataset/imagesets/main/%s.txt' % (image_set)).read().strip().split()
list_file = open('D:/dev/yolov5-master/dataset/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '\images\%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
注意修改代码中地址为自己计算机文件中地址、修改标签类别为标注的类别
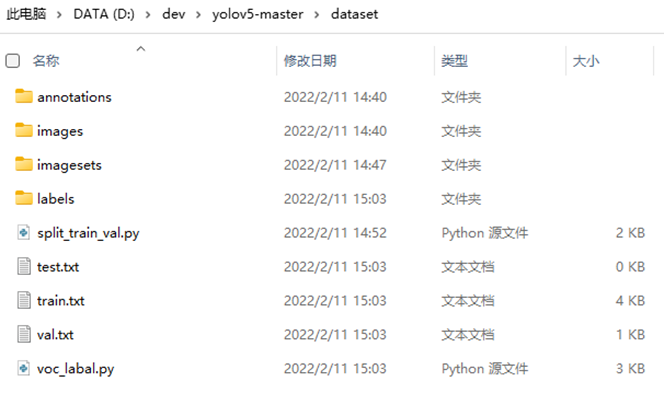
运行后dataset文件夹中会生成labels文件夹,以及三个txt文件:test.txt,train.txt,val.txt,如下图所示:
6.3 创建数据集配置文件
在data文件夹中新建CustomData.yaml:
train: D:\dev\yolov5-master\dataset\train.txt
val: D:\dev\yolov5-master\dataset\val.txt
# number of classes
nc: 2
# class names
names: ['hat', 'no hat']
注意需要修改文件路径、标签类别数量、以及类别名称
6.4 模型配置
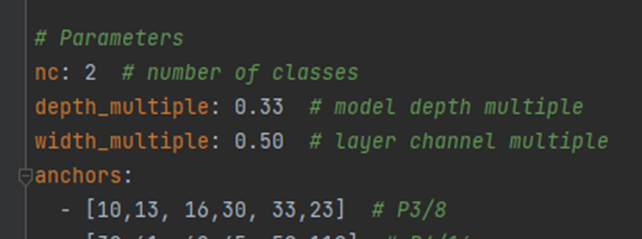
在项目目录下的model文件夹下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov5s.yaml,只用修改一个参数,把nc改成自己的类别数
6.5 训练模型
在train.py文件中修改模型配置路径:

其他参数也可根据需要进行修改,具体请翻阅5.3.1 train.py
在命令行中输入编译运行开始训练:
python train.py --img 640 --batch 8 --epoch 200 --data data/CustomData.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt –-device 0
因为本机只有一张显卡,所以device设为0,若有多张显卡,可设为0,1等
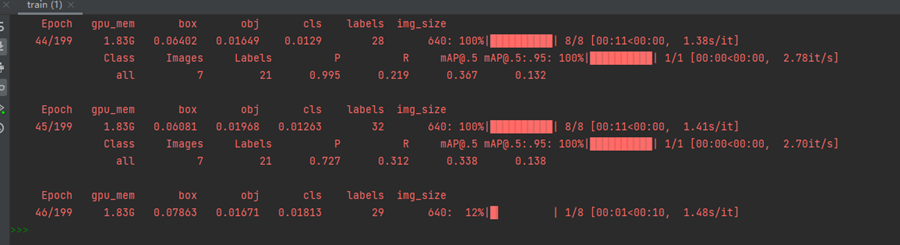
6.6 训练结果
最后结果会保存在项目目录下的runs/train文件夹中,如下图:
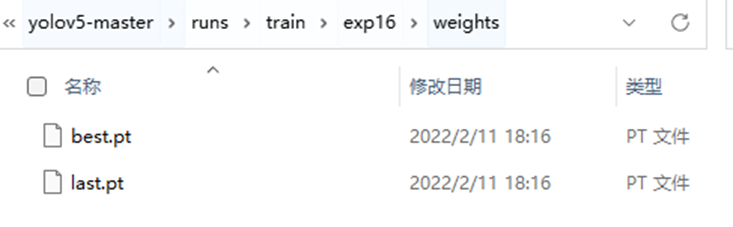
其中权重文件在weights文件夹中,包含best.pt,是效果最好的权重,以及last.pt是最后一次训练的权重。
七、目标识别
下面主要涉及detect.py代码文件
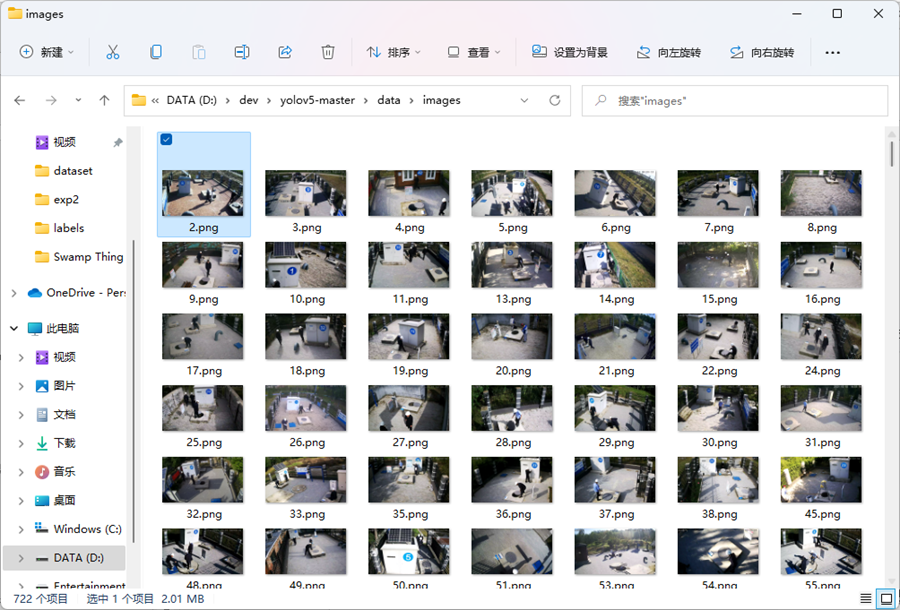
7.1 待检测目标存放
--source可以选择待检测目标的源地址,可以是图片、视频、或者rtps监控视频源等。下以保存在项目目录中data/images文件夹中为例,也就是默认文件夹。
7.2 选择权重文件
权重文件选择刚才训练好的best.pt即可,在--weights中改为刚才训练的best.pt的路径,如图:

7.3 识别
运行detect.py即可,结果默认存放在runs/detect中,如图:
YOLOv5模型训练及检测的更多相关文章
- 机器学习在入侵检测方面的应用 - 基于ADFA-LD训练集训练入侵检测判别模型
1. ADFA-LD数据集简介 ADFA-LD数据集是澳大利亚国防学院对外发布的一套主机级入侵检测数据集合,包括Linux和Windows,是一个包含了入侵事件的系统调用syscall序列的数据集(以 ...
- 人脸检测及识别python实现系列(3)——为模型训练准备人脸数据
人脸检测及识别python实现系列(3)——为模型训练准备人脸数据 机器学习最本质的地方就是基于海量数据统计的学习,说白了,机器学习其实就是在模拟人类儿童的学习行为.举一个简单的例子,成年人并没有主动 ...
- opencv_人脸检测、模型训练、人脸识别
人脸检测.模型训练.人脸识别 2018-08-15 今天给大家带来一套人脸识别一个小案例,主要是帮助小伙伴们解决如何入门OpenCV人脸识别的问题,现在的AI行业比较火热,AI技术的使用比较广泛.就拿 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录10.13 - Google Colab连接 / 数据简单查看 / 模型训练
1. 比赛介绍 比赛地址:阿里云恶意程序检测新人赛 这个比赛和已结束的第三届阿里云安全算法挑战赛赛题类似,是一个开放的长期赛. 2. 前期准备 因为训练数据量比较大,本地CPU跑不起来,所以决定用Go ...
- Fast RCNN 训练自己的数据集(3训练和检测)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https://github.com/YihangLou/fas ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- yolov2在CUDA8.0+cudnn8.0下安装、训练、检测经历
这次用yolov2做检测时遇到个大坑,折腾了我好几天,特以此文记录之. 一.安装cuda+cudnn 它们的版本必须要匹配,否则训练后检测不出目标! 1.下载cuda8.0.61_375.26_lin ...
- 【计算机视觉】如何使用opencv自带工具训练人脸检测分类器
前言 使用opencv自带的分类器效果并不是很好,由此想要训练自己的分类器,正好opencv有自带的工具进行训练.本文就对此进行展开. 步骤 1.查找工具文件: 2.准备样本数据: 3.训练分类器: ...
- 基于Python3.7和opencv的人脸识别(含数据收集,模型训练)
前言 第一次写博客,有点紧张和兴奋.废话不多说,直接进入正题.如果你渴望使你的电脑能够进行人脸识别:如果你不想了解什么c++.底层算法:如果你也不想买什么树莓派,安装什么几个G的opencv:如果你和 ...
随机推荐
- CSS基础 实战案例 模拟小米官方导航栏
效果图 html结构 <ul> <li><a href="#">Xiaomi手机</a></li> <li> ...
- 接口调试没有登录态?用whistle帮你解决
页面的域名是 a.com,接口的域名为 b.com,这是跨域的因此不会将 cookie 带过去的,也就没有登录态. 解决方法:利用 whistle 的 composer 功能. whistle git ...
- Selenium_获取浏览器名称和版本(5)
from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.get(" ...
- CentOS 7 如何清空文件内容
https://www.cnblogs.com/zqifa/p/linux-vim-4.html 方法1.在非编辑状态下使用快捷键gg跳至首行头部,再使用dG即可清空,或 输入"%d&quo ...
- OSPF路由协议详解
OSPF:开放式最短路径优先协议无类别链路状态路由协议,组播更新224.0.0.5/6:跨层封装到三层,协议号89:基于拓扑工作,故更新量大-----需要结构化部署–区域划分.地址规划触发更新.每30 ...
- c# - 数据类型转换和控制台输入
1.使用c#自带的 Convert类转换数据类型 2.源码 using System; namespace ConsoleApp1.toValue { class excutejiecheng { s ...
- 第10组 Beta冲刺 (4/5)(组长)
1.1基本情况 ·队名:今晚不睡觉 ·组长博客: https://www.cnblogs.com/cpandbb/p/14018650.html ·作业博客:https://edu.cnblogs.c ...
- iView 用renderContent自定义树组件
iview的树组件在有默认选中状态的时候默认选中状态的样式改变有bug,默认选中的样式不好看,鉴于此,有renderContent来改造iview的树组件, 效果如图 代码如下 <templat ...
- BugKu CTF(杂项篇MISC)-贝斯手
打开是以下内容 先看一下给了哪些提示 1.介绍 没了?不,拉到最底下还有 2.女神剧照 密码我4不会告诉你的,除非你知道我的女神是哪一年出生的(细品) 大致已经明白了,四位数密码,出生年份 文件是以下 ...
- 谱分解(SD)
前提:矩阵A必须可相似对角化! 充分条件: $A$ 是实对称矩阵 $A$ 有 $n$ 个互异特征值 $A^{\wedge} 2=A $ $\mathrm{A}^{\wedge} 2=\mathrm{E ...