论文解读(Line)《LINE: Large-scale Information Network Embedding》
论文题目:《LINE: Large-scale Information Network Embedding》
发表时间: KDD 2015
论文作者: Jian Tang, Meng Qu , Mingzhe Wang, Ming Zhang, Jun Yan, Qiaozhu Mei
论文地址: Download
前言
大规模信息网络 (large-scale information Network) 无论在存取性,使用性上比起普通的信息处理方式更加复杂,更加多变,例如航空公司网络,出版物网络,社会和通信网络以及万维网。大多数现有的图嵌入方法都不能用于通常包含数百万个节点的真实信息网络。本文提出的 LINE 模型致力于将这种大型的信息网络嵌入到低维的向量空间中,且该模型适用于任何类型(有向、无向亦或是有权重)的信息网络。该方法优化了一个精心设计的目标函数,同时保持了局部和全局网络结构。针对经典随机梯度下降的局限性,提出了一种边缘采样算法(edge-sampling algorithm),实验证明了该网络在各种真实世界的信息网络上的有效性,包括语言网络、社交网络和引文网络。该算法非常高效,能够在一台典型的单一机器上,在几个小时内学习嵌入具有数百万个顶点和数十亿条边的网络。且可用于可视化,节点分类以及关系预测等方面。
关键词:信息网络嵌入;可扩展性;特征学习;降维。
1 Introduction
举例:事实上,有许多共同朋友的人可能有同样的兴趣成为朋友,与许多相似单词一起使用的单词可能有相似的含义。
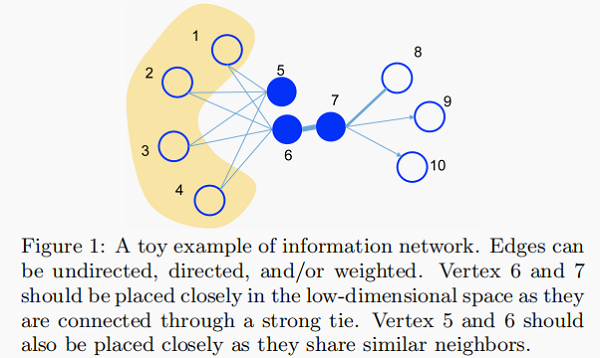
Figure 1 给出了一个说明性的例子。由于顶点 6 和 7 之间的边的权重很大,即 6 和 7 的一阶(first-order)接近,因此在嵌入空间中应紧密表示。另一方面,虽然顶点 5 和顶 6 之间没有联系,但它们共享许多共同的邻居,即它们具有很高的二阶接近性,因此也应相互紧密地表示。我们期望对二阶接近度的考虑能够有效地补充一阶接近度的稀疏性,并更好地保持网络的全局结构。在本文中,我们将提出精心设计的目标,以保持一阶和二阶的接近性。
即使找到一个合理的目标,为一个非常大的网络优化它也是一项挑战。近年来引起人们注意的一种方法是利用随机梯度下降法进行优化。然而,我们证明直接部署随机梯度下降对现实世界的信息网络有问题。这是因为在许多网络中,边是加权的,权值通常呈现出高方差。考虑一个单词共现网络,其中单词对的权值(共现)可能从1到数十万不等。这些边缘的权重将被乘以梯度,导致梯度的爆炸,从而影响性能。为了解决这一问题,我们提出了一种新的边缘采样(edge-sampling)方法,它提高了推理的有效性和效率。我们对概率与其权值成正比的边进行采样,然后将采样的边作为二进制边进行模型更新。
Line Model 是具有通用性的,它适用于有向或无向、加权或非加权图。我们评估了各种真实世界的信息网络的链接性能,包括语言网络、社交网络和引文网络。在多个单词类比、文本分类和节点分类等数据挖掘任务中,评估了学习到的嵌入的有效性。结果表明,Line 模型在有效性和效率方面都优于其他竞争基线。
综上所述,我们有以下贡献:
- 我们提出了一种新的网络嵌入模型,它适合任意类型的信息网络,并且很容易扩展到数百万个节点。它有一个精心设计的目标函数,同时保持了一阶和二阶近点。
- 我们提出了一种优化目标的边缘采样算法。该算法解决了经典随机梯度的局限性,提高了推理的有效性和效率。
- 我们在真实世界的信息网络上进行了广泛的实验。实验结果证明了该 Line Model 的有效性和有效性。
2 Related Work
我们的工作与经典的图嵌入或降维方法有关,如 MDS、IsoMap、LLE 和拉普拉斯特征映射(Laplacian Eigenmap)。这些方法通常首先使用数据点的特征向量来构造亲和图( Affinity graph),例如,数据的 K-nearest 图,然后将亲和图嵌入到一个低维空间中。然而,这些算法通常依赖于求解亲和矩阵的主要特征向量,其复杂度至少是节点数的二次型,使得它们对大规模网络的处理效率低下。
还有 图分解(Graph factorization)的技术。通过矩阵分解得到了一个大图的低维嵌入,并利用随机梯度下降法进行了优化。这是可能的,因为一个图可以表示为一个 Affinity matrix。然而,矩阵分解的目标并不是为网络设计的,因此不一定能保持全局网络结构。直观地说,图分解期望具有高一阶接近的节点被紧密表示。相反,LINE 使用了一个专门为网络设计的目标,它同时保留了一阶(first-order)和二阶(second-order)近似性。实际上,Graph factorization 方法只适用于无向图,而 Line Model 同时适用于无向图和有向图。
与我们相关的最新工作是 DeepWalk ,它部署了一个 截断随机行走(truncated random walk)来获得 representation。虽然在经验上很有效,但 DeepWalk 并没有提供一个明确的目标来明确保留了哪些网络属性。直观地说,DeepWalk 期望具有高二阶接近度的节点产生相似的低维表示,而 LINE 同时保持了一阶和二阶接近度。DeepWalk 使用随机游走来扩展顶点的邻域(类似于深度优先搜索)。LINE 使用宽度优先搜索策略,这是一种更合理的处理二阶接近的方法。实际上,DeepWalk只适用于未加权网络,而我们的模型同时适用于具有加权边和非加权边的网络。
3 Problem definition
我们利用一阶和二阶近似性正式定义了大规模信息网络嵌入的问题。
首先定义了一个信息网络如下:
定义1:Information Network
- 定义为 $G=(V,E)$ ,其中 $V$ 是顶点集,每个顶点表示一个数据对象,$E$ 是顶点之间的边集,每个边表示两个数据对象之间的关系。每条边都是一个有序的对 $e=( u,v)$,与权重 $w_{uv}>0$ 相关联,表示关系的强度。如果 $G$ 是无向的,我们有 $(u,v)≡(v,u)$ 和 $w_{uv}≡w_{vu}$ ,如果 $G$ 有向,我们有 $(u, v) \not \equiv(v, u)$ 和 $w_{u v} \not \equiv w_{v u} $。
在实践中,信息网络可以是定向的(例如引文网络),也可以是无定向的(例如Facebook中的用户社交网络)。边的权值可以是二进制的,也可以取任何实值。请注意,虽然负边权值是可能的,但在本研究中,我们只考虑非负边权值。例如,在引文网络和社交网络中,$w_{uv}$ 取二进制值;在不同对象之间的共现网络中,$w_{uv}$ 可以取任何非负值。在某些网络中,边缘的权值可能会发散,因为一些物体会多次同时出现,而另一些物体可能只是同时出现几次。
定义2:First-order Proximity
- 定义为:网络中的一阶接近度是两个顶点之间的局部成对接近度。对于每一条由边 $(u,v)$ 连接的每对顶点,该边上的权值$w_{uv}$ 表示 $u$ 和 $v$ 之间的第一阶接近程度。如果在 $u$ 和 $v$ 之间没有边,它们的一阶接近度为 $0$ 。
- 如 Figure 1 ,6 和 7 之间存在直连边,且边权较大,则认为两者相似且 1 阶相似度较高,而 5 和 6 之间不存在直连边,则两者间1 阶相似度为 0。
一阶接近通常意味着真实网络中两个节点的相似性。由于这一重要性,许多现有的图嵌入算法,如 $IsoMap$、$LLE$、拉普拉斯特征映射和图分解,都具有保持一阶接近性的目标。
然而,在真实世界的信息网络中,观察到的链接比例很小,其他许多链接缺少。缺失链路上的一对节点的一阶接近度为零,尽管它们在本质上非常相似。因此,仅凭一阶接近并不足以保持网络结构,而寻找另一种解决稀疏性问题的接近概念是很重要的。一种自然的直觉是,共享相似邻居的顶点往往彼此相似。例如,在社交网络中,拥有相似朋友的人往往有相似的兴趣,因此成为朋友;在单词共现网络中,总是与同一组单词同时出现的单词往往具有相似的含义。因此,我们定义了二阶接近,它补充了一阶接近,并保持了网络结构。
定义3:Second-order Proximity
- 定义为:网络中一对顶点 $(u、v)$ 之间的二阶接近性是它们的邻域网络结构之间的相似性。数学上,让$p_{u}=\left(w_{u, 1}, \ldots, w_{u,|V|}\right)$ 表示 $u$ 与所有其他顶点的一阶接近,那么$u$ 和 $v$ 之间的二阶接近由 $p_u$ 和 $p_v$ 之间的相似性决定。如果没有顶点从 $u$ 和 $v$ 同时相连,则 $u$ 和 $v$ 之间的二阶接近度为 $0$。
- 如 Figure 1 ,虽然 5 和 6 之间不存在直连边,但是他们有很多相同的邻居顶点 $(1,2,3,4)$,这其实也可以表明5和6是相似的,而 $2$ 阶相似度就是用来描述这种关系的。
定义4:Large-scale Information Network Embedding
- 定义为:给定大网络 $G=(V,E)$,大规模信息网络嵌入问题的目的是将每个顶点 $v∈V$ 表示为低维空间向量。即学习函数 $f_G:V→R^d$,其中 $d \ll|V|$。在空间 $R^d$ 中,保留了顶点之间的一阶接近和二阶接近度。
4. LINE: LARGE-SCALE INFORMATION NETWORK EMBEDDING
- 它必须能够保持顶点之间的一阶接近和二阶接近;
- 它必须扩展到非常大的网络,比如数百万个顶点和数十亿条边;
- 它可以处理具有任意类型边的网络:有向、无向和/或加权。
4.1 Model Description
我们分别描述了保持一阶接近度和二阶接近度的 LINE 模型,然后引入了一种简单的方法来结合这两种接近度。
4.1.1 LINE with First-order Proximity
一阶接近是指网络中顶点之间的局部成对概率。
对于每条无向边 $(i、j)$,我们对顶点 $v_i$ 和 $v_j$ 之间的联合概率进行了细化如下:
${\large p_{1}\left(v_{i}, v_{j}\right)=\frac{1}{1+\exp \left(-\vec{u}_{i}^{T} \cdot \vec{u}_{j}\right)}} $
其中 $\vec{u}_{i} \in R^{d}$ 为顶点 $v_i$ 的低维向量表示。上述公式定义了空间 $V×V$ 上的分布 $p(·,·)$ 。
其经验概率可以定义为 $\hat{p}_{1}(i, j)=\frac{w_{i j}}{W} $ ,其中 $W=\sum_{(i, j) \in E} w_{i j}$ 。
优化目标如下:
$O_{1}=d\left(\hat{p}_{1}(\cdot, \cdot), p_{1}(\cdot, \cdot)\right)$
其中 $d(·,·)$ 为两个分布之间的距离。常用的衡量两个概率分布差异的指标为 KL 散度,使用 KL 散度并忽略常数项后有
$O_{1}=-\sum_{(i, j) \in E} w_{i j} \log p_{1}\left(v_{i}, v_{j}\right)$
请注意,一阶接近只适用于无向图,而不适用于有向图。通过找到 $\left\{\vec{u}_{i}\right\}_{i=1 . .|V|}$ ,最小化目标上述式子。我们可以表示 $d$ 维空间中的每个顶点。
4.1.2 LINE with Second-order Proximity
二阶接近性适用于有向图和无向图。
给定一个网络,在不丧失一般性的情况下,我们假设它是有向的(一条无向边可以看作是两条方向相反、权值相等的有向边)。二阶接近性假设与其他顶点共享许多连接的顶点彼此之间是相似的。在这种情况下,每个顶点也被视为一个特定的 “上下文”,并且假设在“上下文”上分布相似的顶点是相似的。
因此,每个顶点扮演两个角色:顶点本身和其他顶点的特定 “上下文”。我们引入了两个向量 $ \vec{u}_{i}$ 和 $\vec{u}_{i}^{\prime} $,其中 $ \vec{u}_{i}$ 在被视为顶点时是 $v_i$ 的表示,而 $\vec{u}_{i}^{\prime} $ 在被视为特定的“上下文”时是 $v_i$ 的表示。对于每个有向边 $(i、j)$,我们首先将顶点 $v_i$ 生成的“上下文” $v_j$ 的概率定义为:
${\large p_{2}\left(v_{j} \mid v_{i}\right)=\frac{\exp \left(\vec{u}_{j}^{T} \cdot \vec{u}_{i}\right)}{\sum_{k=1}^{|V|} \exp \left(\vec{u}_{k}^{\prime T} \cdot \vec{u}_{i}\right)}} $
其中,$|V|$ 是顶点或“上下文”的数量。对于每个顶点 $v_i$。上述式子实际上在上下文上定义了一个条件分布 $p_2(·|v_i)$ ,即网络中的整个顶点集。如上所述,二阶接近性假定在上下文上具有相似分布的顶点彼此相似。为了保持二阶接近性,我们应该使低维表示所指定的上下文 $ p_2(·|v_i)$ 的条件分布接近于经验分布 $\hat{p}_{2}\left(\cdot \mid v_{i}\right)$。因此,我们将最小化以下目标函数:
$O_{2}=\sum \limits _{i \in V} \lambda_{i} d\left(\hat{p}_{2}\left(\cdot \mid v_{i}\right), p_{2}\left(\cdot \mid v_{i}\right)\right)$
其中 $d(·,·)$ 为两个分布之间的距离。由于网络中顶点的重要性可能不同,我们在目标函数中引入 $λ_i$ 来表示网络中顶点 $i$ 在网络中的声望,这可以通过度来衡量,也可以通过 PageRank 等算法来估计。经验分布 $\hat{p}_{2}\left(v_{j} \mid v_{i}\right)$ 定义为 $\hat{p}_{2}\left(v_{j} \mid v_{i}\right)=\frac{w_{i j}}{d_{i}}$,其中 $w_{ij} $ 是边 $(i,j)$ 的权重,$d_i$ 是顶点 $i$ 的出度,即 $d_{i}=\sum \limits _{k \in N(i)} w_{i k}$,其中 $N(i)$ 是 $v_i$ 的外邻集合。为了简单起见,我们将 $λ_i$ 设为顶点 $i$ 的度,即 $λ_i=d_i$,这里我们也采用 kl 散度 $\hat{p}_{2}\left(v_{j} \mid v_{i}\right)=\frac{w_{i j}}{d_{i}}$ 作为距离函数。用 kl 散度替换 $d(·,·)$ ,设置 $λ_i=d_i$ 并省略一些常数,我们有:
$O_{2}=-\sum \limits _{(i, j) \in E} w_{i j} \log p_{2}\left(v_{j} \mid v_{i}\right)$
通过学习 $\left\{\vec{u}_{i}\right\}_{i=1 . .|V|} $ 和 $\left\{\vec{u}_{i}^{\prime}\right\}_{i=1 . .|V|} $ 最小化这个目标,我们能够用 $d$ 维向量 $\vec{u}_{i} $ 来表示每个顶点 $v_{i}$。
4.1.3 Combining fifirst-order and second-order proximities
4.2 Model Optimization
优化目标 $O_2$ 的计算代价很高,需要在计算条件概率 $p_2(·|v_i)$ 时需要对整个顶点集合进行总和。为了解决这一问题,我们采用了中提出的负采样方法,根据每条边 $(i、j)$ 的一定的噪声分布,对多个负边进行采样。更具体地说,它为每条边 $(i、j)$ 指定了以下目标函数:
$\log \sigma\left(\vec{u}_{j}^{T} \cdot \vec{u}_{i}\right)+\sum \limits _{i=1}^{K} E_{v_{n} \sim P_{n}(v)}\left[\log \sigma\left(-\vec{u}_{n}^{\prime T} \cdot \vec{u}_{i}\right)\right]$
其中 $σ(x)=1/(1+exp(−x))$ 为 Sigmoid 函数。第一项表示观测到的边,第二项表示由噪声分布得到的负边,$K$ 是负边的个数。我们将 $P_{n}(v) \propto d_{v}^{3 / 4}$ 设置为中提出的 $3/4$,其中 $d_v$ 是顶点 $v$ 的出度。
对于目标函数,存在一个简单的解:$u_{i k}=\infty$,对于 $i=1,……,|V|$ 和 $k=1,……,d$ 。为了避免这个简单的解决方案,我们仍然可以利用负采样方法,只将 $ \vec{u}_{j}^{\prime}$ 更改为 $\vec{u}_{j}^{T}$。
采用异步随机梯度算法(ASGD)进行优化。在每一步中,ASGD算法对一批边缘进行采样,然后更新模型参数。如果对一条边 $(i、j)$ 进行采样,则采用梯度w.r.t.顶点 $i$ 的嵌入向量 $\vec{u}_{i}$ 将计算为:
$\frac{\partial O_{2}}{\partial \vec{u}_{i}}=w_{i j} \cdot \frac{\partial \log p_{2}\left(v_{j} \mid v_{i}\right)}{\partial \vec{u}_{i}}$
请注意,梯度将乘以边的权重。当边的权值具有高方差时,这就会成为问题。例如,在一个单词共发生网络中,一些单词同时出现很多次(例如,数万个),而有些单词只同时出现几次。在这样的网络中,梯度的尺度会发散,很难找到一个好的学习率。如果根据权值小的边选择较大的学习率,权值大的边上的梯度会爆炸,而如果根据权值大的边选择学习率,梯度会太小。
4.2.1 Optimization via Edge Sampling
令 $W = (w_1, w_2, ... , w_{|E|}) $ 表示边的权重。 首先可以简单地计算权重总和 $w_{sum} = = \sum_{i=1}^{|E|}w_{i}$ ,然后对进行采样 $[0, w_{sum}]$ 范围内的随机值,以查看随机值属于 $[\sum_{j=0}^{i-1}w_{j}, \sum_{j=0}^{i}w_{j})$ 哪个区间 。 这个 方法需要 $O(|E|) $ 时间来抽取样本,当边数 $|E| $ 很大这是昂贵的。 我们使用别名表 方法根据权重抽取样本边,重复绘制时只需要 $O(1) $ 时间来自相同离散分布的样本。
从别名表中采样一条边需要恒定的时间 $O(1) $ ,而使用负采样的优化需要 $O(d(K+1))$ 时间,其中 $K$ 为负样本的数量。因此,总体上,每个步骤都需要 $O(dK)$ 时间。在实践中,我们发现用于优化的步骤数通常与边数 $O(|E|)$ 成正比。因此,直线的总体时间复杂度为 $O(dK|E|)$ ,它与边数 $|E|$ 呈线性关系,而不依赖于顶点数 $|V|$ 。边缘采样处理提高了随机梯度下降的有效性,而不降低了效率。
4.3 Discussion
我们讨论了直线模型的几个实际问题:
- Low degree vertices
一个实际的问题是如何准确地嵌入小度的顶点。由于这种节点的邻居数量非常少,很难准确地推断出其表示,特别是基于二阶接近的方法,它严重依赖于 “上下文” 的数量。一个直观的解决方案是通过添加更高阶的邻居来扩展这些顶点的邻居,比如邻居的邻居。在本文中,我们只考虑向每个顶点添加二阶邻居,即邻居的邻居。顶点 $i$ 与其二阶邻域 $j$ 之间的权重被测量为
$w_{i j}=\sum \limits _{k \in N(i)} w_{i k} \frac{w_{k j}}{d_{k}}$
在实践中,只能添加一个顶点集 ${j}$,它们具有最大的顶点子集。
- New vertices
另一个实际的问题是如何找到新到达的顶点的表示。对于一个新的顶点 $i$,如果它与现有顶点的连接已知,我们可以得到现有顶点上的经验分布 $\hat{p}_{1}\left(\cdot, v_{i}\right)$ 和 $\hat{p}_{2}\left(\cdot \mid v_{i}\right)$。根据目标函数 $O_1$ 或者 $O_2$,得到新顶点的嵌入。一种简单的方法是最小化以下目标函数之一
$-\sum \limits _{j \in N(i)} w_{j i} \log p_{1}\left(v_{j}, v_{i}\right), \text { or }-\sum \limits_{j \in N(i)} w_{j i} \log p_{2}\left(v_{j} \mid v_{i}\right)$
通过更新新顶点的嵌入和保持现有顶点的嵌入。如果没有观察到新顶点和现有顶点之间的连接,我们必须求助于其他信息,如顶点的文本信息,并将其留给我们未来的工作。
5. EXPERIMENTS
我们将该方法应用于不同类型的几个大型现实世界网络,包括语言网络,两个社交网络和两个引用网络。
数据集:
(1)语言网络:整个英文维基百科页面构建了一个词共同网络
(2)社交网络:Flickr和Youtube
(3)引用网络:作者引文网和论文引文网
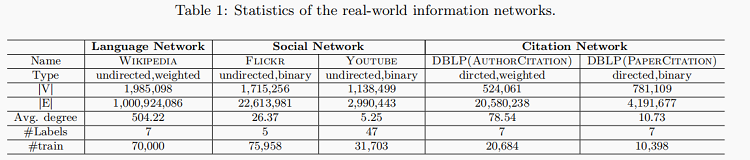
以上网络的详细统计数据总结在表1中,代表一系列信息网络(有向或无向、加权或否);每个网络包含至少50万个节点和数百万个边。
算法比较:将LINE模型与一些常见的图嵌入算法进行比较,包括GF算法,Deep Walk算法,LINE-SGD,LINE算法等。
数据集表一:
参数设置:
对于所有方法,随机梯度下降的小批量大小设置为1;以起始值 $\rho_{0}=0.025$ 和 $\rho_{t}=\rho_{0}(1-t / T)$ 设定学习速度,$T$ 是小批量或边缘样品的总数;为了公平比较,语言网络嵌入的维度被设置为 $200$;而其他网络中,默认设置为 $128$;其他的默认参数设置包括:LINE的负采样 $K=5$,样本总数 $T = 100$ 亿(LINE),$T=200$ 亿(GF),窗口大小 $win = 10$,步行长度 $t = 40$,对于 Deep Walk,每顶点行走 $\gamma=40$;所有的嵌入向量最终通过设置$\|w\|_{2}=1$ 进行归一化。
定量结果:
1.语言网络:
两个应用程序用于评估学习嵌入的有效性:词类比和文档分类。
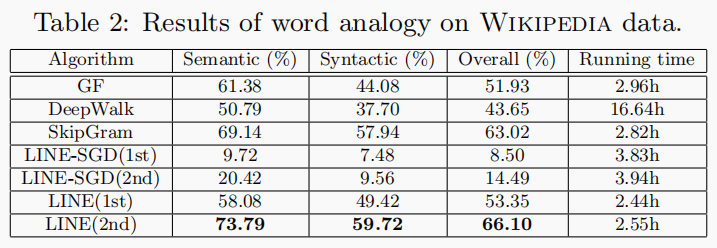
词类比:给定一个单词对 $(a,b) $ 和一个单词 $c$,该任务旨在找到一个单词 $d$ ,使得 $c$和 $d$ 之间的关系类似于 $a$ 和 $b$ 之间的关系,或表示为:$a: b \rightarrow c: ?$ ; 表2 使用在维基百科语料库或维基百科词汇网络上学习的词汇的嵌入来报告单词类比的结果,对于图分解,每对单词之间的权重被定义为同时出现次数的对数,这导致比共同出现的原始值更好的性能。对于DeepWalk,尝试不同的截止阈值将语言网络转换为二进制网络,并且当所有边缘保留在网络中时,实现最佳性能。同时与与最先进的词嵌入模式SkipGram进行比较。直接从原始维基百科页面学习嵌入词,也隐含地是矩阵分解法。

2.社交网络:
与语言网络相比,社交网络更加稀缺;将每个节点分配到一个或多个社区的多标签分类任务来评估顶点嵌入;随机抽取不同百分比的顶点进行训练,其余用于评估。结果在10次不同运行中进行平均。

引用网络:
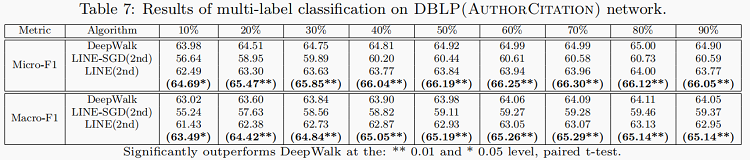
通过GF和LINE两种方法对引用网络进行评估。还通过多标签分类任务评估顶点嵌入。 我们选择7个流行会议,包括AAAI,CIKM,ICML,KDD,NIPS,SIGIR和WWW作为分类类别。
DBLP(AuthorCitation) Network:
DBLP(PaperCitation) Network :

训练结果:

6. 总结
LINE模型具有精心设计的客观功能,保留了一阶和二阶接近度,相互互补。并提出了一种有效和有效的边缘抽样方法进行模型推理;解决了加权边缘随机梯度下降的限制,而不影响效率。此外,除一阶和二阶之外更高的相似度也是LINE模型算法在未来能够更加拓宽的方面。异构网络的嵌入,也是研究的方向之一。
参考博客


- https://zhuanlan.zhihu.com/p/56478167
- https://zhuanlan.zhihu.com/p/27037042
- https://zhuanlan.zhihu.com/p/74746503
『总结不易,加个关注呗!』2021-11-14 17:22:26
论文解读(Line)《LINE: Large-scale Information Network Embedding》的更多相关文章
- 论文阅读:Relation Structure-Aware Heterogeneous Information Network Embedding
Relation Structure-Aware Heterogeneous Information Network Embedding(RHINE) (AAAI 2019) 本文结构 (1) 解决问 ...
- 论文笔记之:Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation
Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation Google 2016.10.06 官方 ...
- 论文阅读 GloDyNE Global Topology Preserving Dynamic Network Embedding
11 GloDyNE Global Topology Preserving Dynamic Network Embedding link:http://arxiv.org/abs/2008.01935 ...
- 论文解读SDCN《Structural Deep Clustering Network》
前言 主体思想:深度聚类需要考虑数据内在信息以及结构信息. 考虑自身信息采用 基础的 Autoencoder ,考虑结构信息采用 GCN. 1.介绍 在现实中,将结构信息集成到深度聚类中通常需要解决以 ...
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- Network Embedding 论文小览
Network Embedding 论文小览 转自:http://blog.csdn.net/Dark_Scope/article/details/74279582,感谢分享! 自从word2vec横 ...
- Network Embedding
网络表示 网络表示学习(DeepWalk,LINE,node2vec,SDNE) https://blog.csdn.net/u013527419/article/details/76017528 网 ...
- 论文解读(SDNE)《Structural Deep Network Embedding》
论文题目:<Structural Deep Network Embedding>发表时间: KDD 2016 论文作者: Aditya Grover;Aditya Grover; Ju ...
- network embedding 需读论文
Must-read papers on NRL/NE. github: https://github.com/nate-russell/Network-Embedding-Resources NRL: ...
随机推荐
- excel模板数据填充 :tablefill
背景(问题) 在Web后台系统中或多或少都存在导入数据的功能,其中操作流程基本是 1.下载模板 2.填充模板数据 3.上传模板 但通常比较耗费时间的是填充模板数据这一步骤, 已自己为例之前的数据要么是 ...
- Win32对话框模板创建的窗口上响应键消息,Tab焦点切换消息,加速键消息
今天在学习的时候,发现对话框上不响应键盘消息,查了老半天,终于成功了,现分享出来, 1,首先要在消息循环的时候加如下代码. int WINAPI WinMain(_In_ HINSTANCE hIns ...
- Vulnhub实战-JIS-CTF_VulnUpload靶机👻
Vulnhub实战-JIS-CTF_VulnUpload靶机 下载地址:http://www.vulnhub.com/entry/jis-ctf-vulnupload,228/ 你可以从上面地址获取靶 ...
- 洛谷4051 JSOI2007 字符加密(SA)
真是一道良好的SA模板题 首先,由于涉及到从左边移动到右边这个过程,我们不妨直接把字符串复制一遍,接在后面. 然后直接构造后缀数组,按排名从小到大,枚举所有的位置,如果这个后缀的起始点是在原串中的,那 ...
- md5验证文件上传,确保信息传输完整一致
注:因为是公司项目,仅记录方法和思路以及可公开的代码. 最近在公司的项目中,需要实现一个上传升级包到服务器的功能: 在往服务器发送文件的时候,需要确保 文件从开始发送,到存入服务器磁盘的整个传输的过程 ...
- 好程序员打造核心教培天团,着力培养IT高级研发人才
随着数字化进程加快,各行各业数字化转型迫在眉睫,技术人才战略成为企业发力重点,IT高级研发人才已经成为企业的"核心资产",对企业发展起关键性作用,然而市场上高级研发人才极为稀缺.据 ...
- Codeforces Round #747 (Div. 2) Editorial
Codeforces Round #747 (Div. 2) A. Consecutive Sum Riddle 思路分析: 一开始想起了那个公式\(l + (l + 1) + - + (r − 1) ...
- Noip模拟33垫底反思 2021.8.8
T1 Hunter 考场上没写$%p$挂了25分.也是很牛皮,以后打完过了样例一定要检查 因为样例太小了......很容易忘记%%%% 正解随便手模就出来了. 1 #include<bits/s ...
- 2021.8.4考试总结[NOIP模拟30]
T1 毛衣衬 将合法子集分为两个和相等的集合. 暴力枚举每个元素是否被选,放在哪种集合,复杂度$O(3^n)$.考虑$\textit{meet in the middle}$. 将全集等分分为两部分分 ...
- 常用JAVA API :String 、StringBuilder、StringBuffer的常用方法和区别
摘要 本文将介绍String.StringBuilder类的常用方法. 在java中String类不可变的,创建一个String对象后不能更改它的值.所以如果需要对原字符串进行一些改动操作,就需要用S ...