hudi clustering 数据聚集(三 zorder使用)
目前最新的 hudi 版本为 0.9,暂时还不支持 zorder 功能,但 master 分支已经合入了(RFC-28),所以可以自己编译 master 分支,提前体验下 zorder 效果。
环境
1、直接下载 master 分支进行编译,本地使用 spark3,所以使用编译命令:
mvn clean package -DskipTests -Dspark3
2、启动 spark-shell,需要指定编译出来的 jar 路径:
spark-shell --jars /<path-to-hudi>/packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.10.0-SNAPSHOT.jar --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
zorder commit 代码简略分析
相关配置
在 HoodieClusteringConfig.java 中添加了 zorder 相关的配置,主要包括:
- 该功能的使能(默认关闭)
- 该功能使用的曲线类型(目前只实现 z-order,后续会实现 hilbert)
- 曲线生成方式(包括 direct 和 sample,默认为 direct)
- 数据跳过功能(默认开启)。
相关依赖
1、该配置在 HoodieClusteringConfig 定义,所以该功能的运行需要依赖 clustering ,会在聚集操作后对数据进行重新排序、写入。
2、该功能会生成自己的索引,索引记录的位置在 .hooie/.zindex 下,在 HoodieTableMetaClient.java 中定义: public static final String ZINDEX_NAME = ".zindex";
3、该功能的索引列,由 hoodie.clustering.plan.strategy.sort.columns 决定,可指定多列,不同列用英文逗号分割,具体可参考 updateOptimizeOperationStatistics 函数。
相关限制
1、该功能目前支持 spark,暂时没有提供 Flink 和 Java 的实现。
2、在 zindex 中,只记录了最大值、最小值 和 null 值个数,具体可参见 saveStatisticsInfo 函数。
3、该功能支持的数据类型,具体可参见 createZIndexedDataFrameByMapValue 函数。
zvalue实现
1、direct 的 zvalue 生成: ZCurveOptimizeHelper.java。
2、sample 的 zvalue 生成: RangeSample.scala。
spark-shell 代码
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.config.HoodieClusteringConfig._
val t1 = "t1"
val t2 = "t2"
val basePath = "file:///tmp/hudi_data/"
val dataGen = new DataGenerator(Array("2020/03/11"))
// 生成数据
var a = 0;
var ups = new Array[java.util.ArrayList[String]](8)
var ups = new Array[java.util.List[String]](8)
for (a <- 0 to 7) {
ups(a) = convertToStringList(dataGen.generateInserts(10000));
}
for (a <- 0 to 7) {
val df = spark.read.json(spark.sparkContext.parallelize(ups(a), 1));
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t1).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
mode(Append).
save(basePath+t1);
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, t2).
// 每次写入的数据都生成一个新的文件
option("hoodie.parquet.small.file.limit", "0").
// 每次操作之后都会进行clustering操作
option("hoodie.clustering.inline", "true").
// 每4次提交就做一次clustering操作
option("hoodie.clustering.inline.max.commits", "8").
// 指定生成文件最大大小
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1400000").
// 指定小文件大小限制,当文件小于该值时,可用于被 clustering 操作
option("hoodie.clustering.plan.strategy.small.file.limit", "1400000").
// 指定排序的列
option("hoodie.clustering.plan.strategy.sort.columns", "begin_lat,end_lat").
// 使能zorder
option(LAYOUT_OPTIMIZE_ENABLE.key(), true).
mode(Append).
save(basePath+t2);
}
// 创建临时视图
spark.read.format("hudi").load(basePath+t1).createOrReplaceTempView("t1_table")
spark.read.format("hudi").load(basePath+t2).createOrReplaceTempView("t2_table")
这里建立了2张表t1和t2,其中t1是普通的表,t2是使用了zorder排序的表。
共生成8组数据,总共80000条数据,生成对应8个数据文件(t2表修改文件的最大最小值,使其在数据合并之后仍然是8个文件,对应的配置是)hoodie.clustering.plan.strategy.target.file.max.bytes 和 hoodie.clustering.plan.strategy.small.file.limit。
针对 begin_lat 和 end_lat 列进行排序,使用默认的 direct 方式。
使用 inline 方式触发 clustering,在每 8 次提交进行一次 clustering。
现象及分析
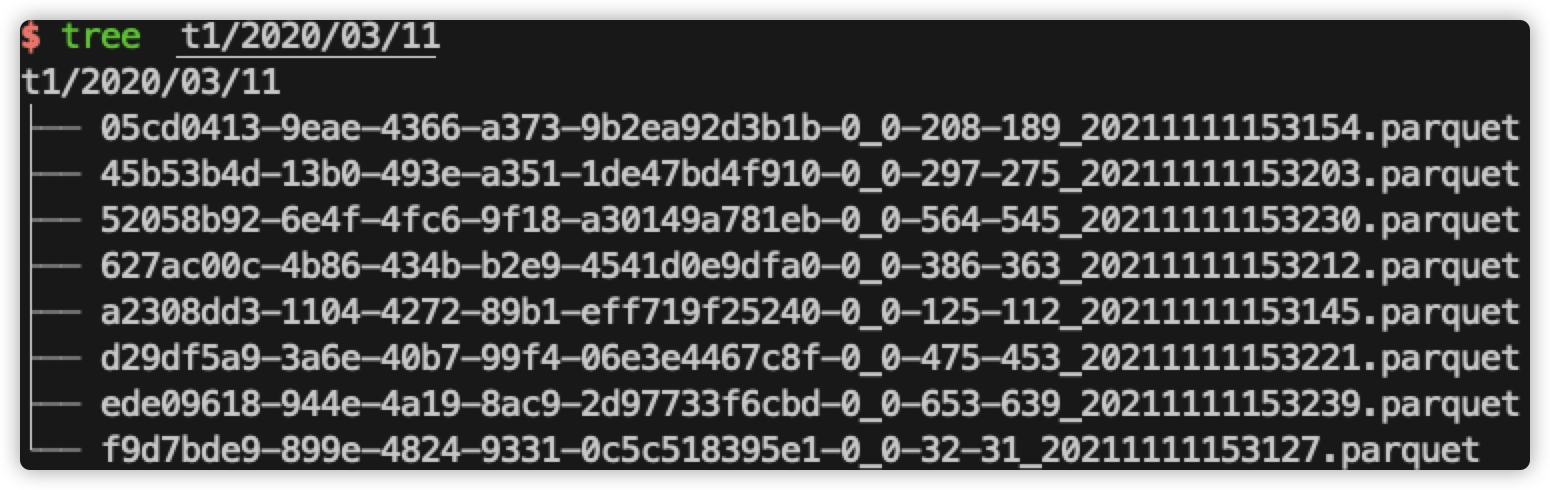
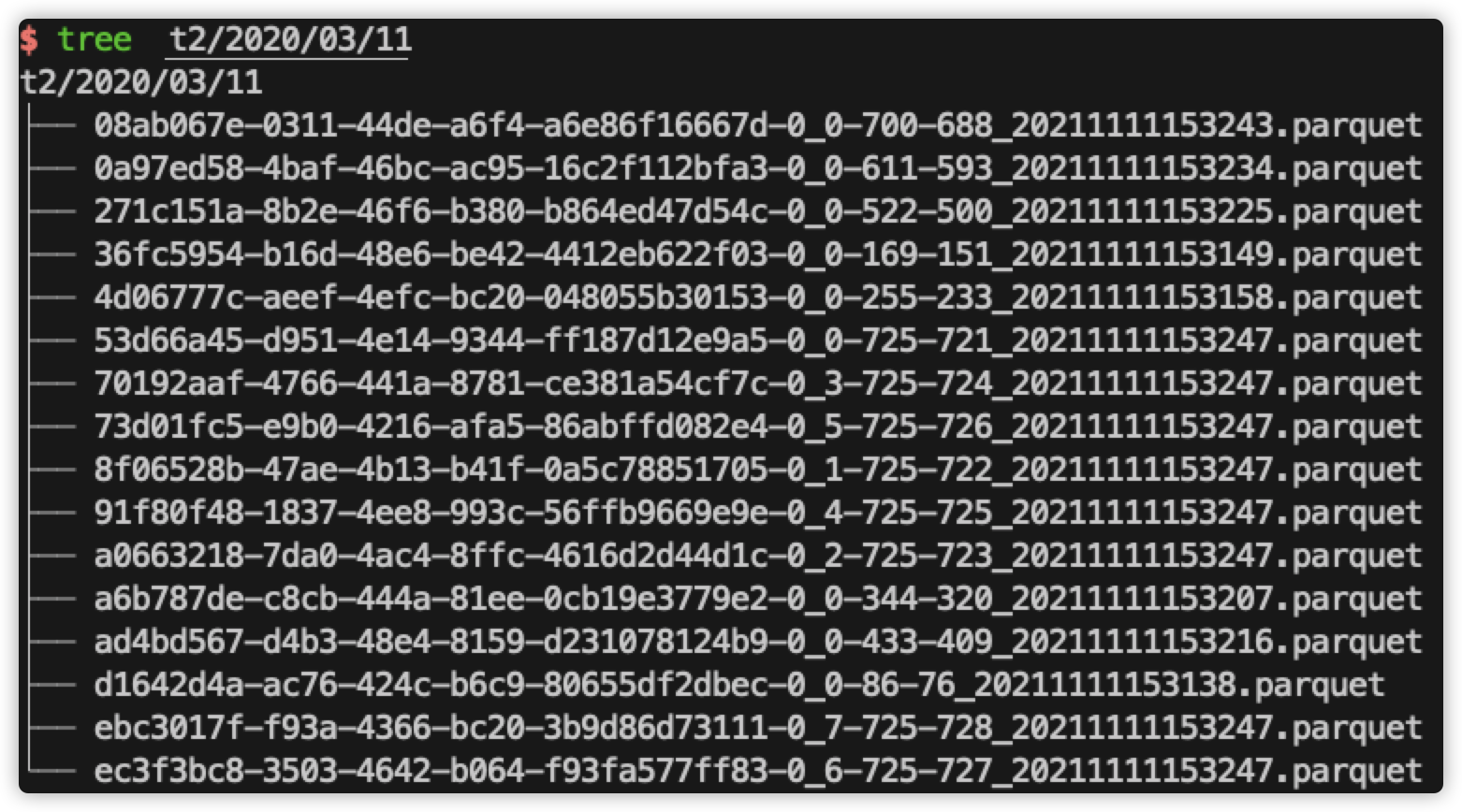
1、在 t1 目录下,只有对应的 8 个 parquet 数据文件,在 t2 目录下,有 16 个 parquet 数据文件,其中 8 个是原始的数据文件,另外 8 个是 clustering 后新生成的数据文件。
2、在 t2 的 .hoodie 下 生成了 .zindex 目录:

可以使用 parquet-tool.jar 对该文件进行查看:
file = 8f06528b-47ae-4b13-b41f-0a5c78851705-0_1-725-722_20211111153247.parquet
begin_lat_minValue = 0.08211371450402716
begin_lat_maxValue = 0.9997316799855066
begin_lat_num_nulls = 0
end_lat_minValue = 0.007866719050410031
end_lat_maxValue = 0.9999245980998445
end_lat_num_nulls = 0
file = 53d66a45-d951-4e14-9344-ff187d12e9a5-0_0-725-721_20211111153247.parquet
begin_lat_minValue = 5.235437913420071E-6
begin_lat_maxValue = 0.9998301829548436
begin_lat_num_nulls = 0
end_lat_minValue = 7.622934875439746E-6
end_lat_maxValue = 0.9999316614851375
end_lat_num_nulls = 0
file = a0663218-7da0-4ac4-8ffc-4616d2d44d1c-0_2-725-723_20211111153247.parquet
begin_lat_minValue = 0.12506873541740904
begin_lat_maxValue = 0.999128795187336
begin_lat_num_nulls = 0
end_lat_minValue = 0.09383249599535315
end_lat_maxValue = 0.49995210011578595
end_lat_num_nulls = 0
file = 70192aaf-4766-441a-8781-ce381a54cf7c-0_3-725-724_20211111153247.parquet
begin_lat_minValue = 0.12503208286353262
begin_lat_maxValue = 0.4999482257584935
begin_lat_num_nulls = 0
end_lat_minValue = 0.25026158207678606
end_lat_maxValue = 0.9998244932648992
end_lat_num_nulls = 0
file = ebc3017f-f93a-4366-bc20-3b9d86d73111-0_7-725-728_20211111153247.parquet
begin_lat_minValue = 0.6250154203734088
begin_lat_maxValue = 0.9999920463384483
begin_lat_num_nulls = 0
end_lat_minValue = 0.5000295773327517
end_lat_maxValue = 0.9999604245270753
end_lat_num_nulls = 0
file = ec3f3bc8-3503-4642-b064-f93fa577ff83-0_6-725-727_20211111153247.parquet
begin_lat_minValue = 0.5000433340037777
begin_lat_maxValue = 0.9999933816913421
begin_lat_num_nulls = 0
end_lat_minValue = 0.3751232553589945
end_lat_maxValue = 0.9997198848519347
end_lat_num_nulls = 0
file = 91f80f48-1837-4ee8-993c-56ffb9669e9e-0_4-725-725_20211111153247.parquet
begin_lat_minValue = 0.25005205774731387
begin_lat_maxValue = 0.9999255937189415
begin_lat_num_nulls = 0
end_lat_minValue = 0.12500497130106802
end_lat_maxValue = 0.9999928793510746
end_lat_num_nulls = 0
file = 73d01fc5-e9b0-4216-afa5-86abffd082e4-0_5-725-726_20211111153247.parquet
begin_lat_minValue = 0.5000222416743727
begin_lat_maxValue = 0.9999855548910661
begin_lat_num_nulls = 0
end_lat_minValue = 0.18757377058575975
end_lat_maxValue = 0.49997508767465637
end_lat_num_nulls = 0
以上只截取前两个数据。在该文件中,会对所有的 parquet 文件进行统计,统计的数据包括最大值、最小值和null个数,统计的列就是使用 hoodie.clustering.plan.strategy.sort.columns 指定的列。当 spark 进行查询时,就会使用这些条件来判断是否要读取该数据文件。
3、这里可以使用 begin_lat 和 end_lat 看下过滤效果:
a、sql("select count(*) from t2_table where begin_lat < 0.2 and end_lat < 0.5").show()

总共80000条数据,查询了37420条数据,最终得到数据:7951。
b、sql("select count(*) from t2_table where begin_lat < 0.2 and end_lat > 0.8").show()
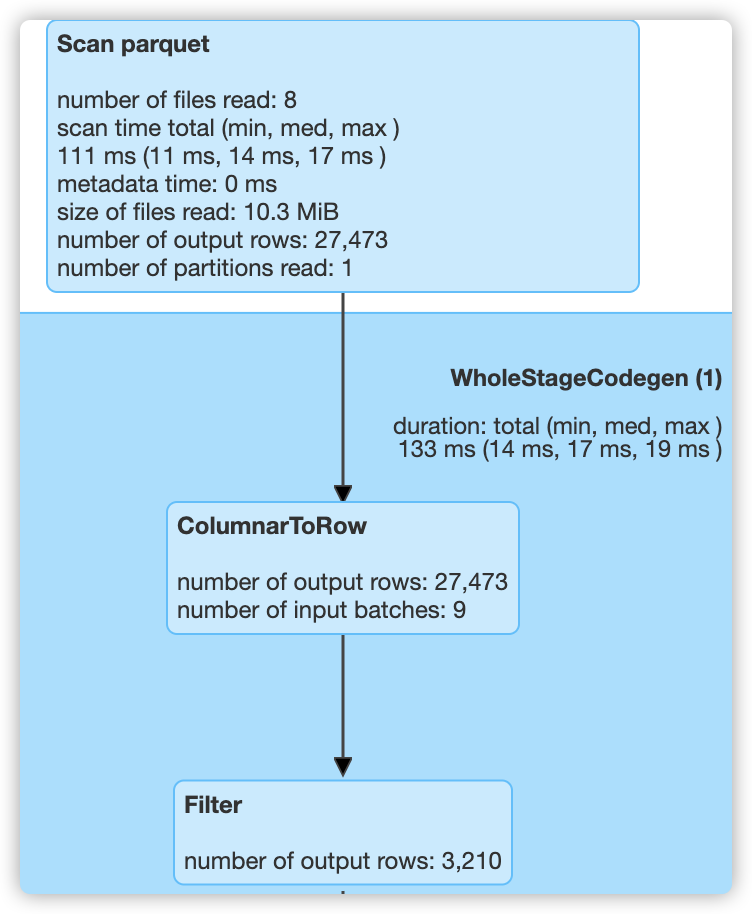
总共80000条数据,查询了27473条数据,最终得到数据:3210。
c、sql("select count(*) from t2_table where begin_lat > 0.9 and end_lat < 0.2").show()
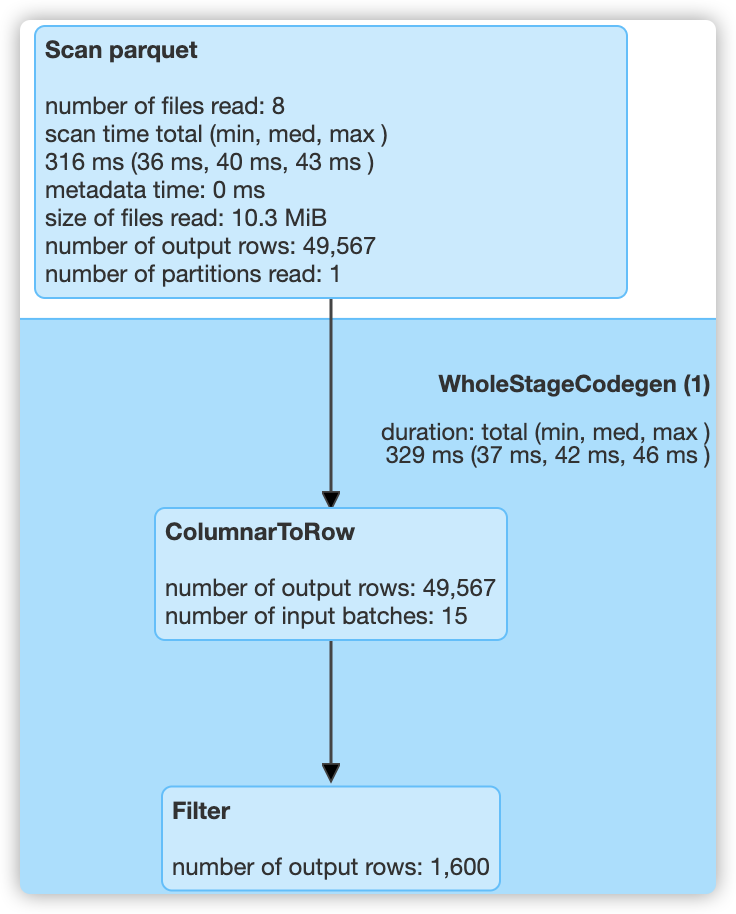
总共80000条数据,查询了49567条数据,最终得到数据:1600。
d、sql("select count(*) from t2_table where begin_lat > 0.95 and end_lat < 0.02").show()
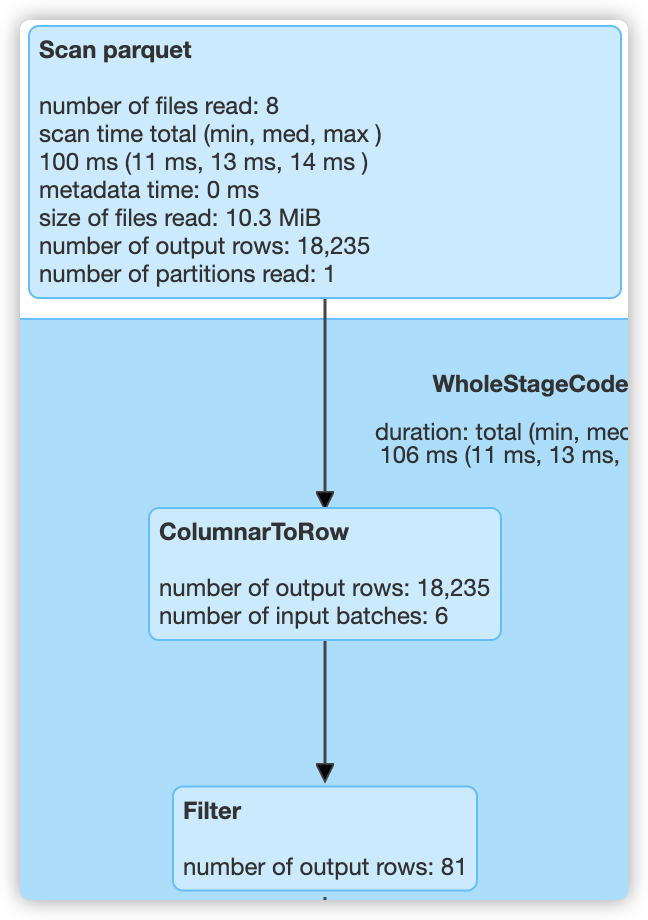
总共80000条数据,查询了18235条数据,最终得到数据:81。
4、在 t1 表中,由于没有对 begin_lat 和 end_lat 做任何处理,所以同样查询以上4条 sql 时,都会读取 80000 条数据,而使用 zorder 之后,只分别读取了 37420,27473,49567,18235 条数据,过滤效果提升明显。
其实,不使能 zorder 功能,而只使用 clustering 的排序功能,也能做一些过滤,但由于本次实验中使用的数据分布较为均匀,所以虽然也可以对两个字段做排序,但基本上只会对第一个字段有较好的过滤效果,有兴趣的可以自己尝试一下。
hudi clustering 数据聚集(三 zorder使用)的更多相关文章
- hudi clustering 数据聚集(二)
小文件合并解析 执行代码: import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ imp ...
- hudi clustering 数据聚集(一)
概要 数据湖的业务场景主要包括对数据库.日志.文件的分析,而管理数据湖有两点比较重要:写入的吞吐量和查询性能,这里主要说明以下问题: 1.为了获得更好的写入吞吐量,通常把数据直接写入文件中,这种情况下 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- ios网络学习------4 UIWebView的加载本地数据的三种方式
ios网络学习------4 UIWebView的加载本地数据的三种方式 分类: IOS2014-06-27 12:56 959人阅读 评论(0) 收藏 举报 UIWebView是IOS内置的浏览器, ...
- Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式
Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式 P703 Linux读写内存数据的三种方式 1.read ,write方式会在用户空间和内核空间不断拷贝数据, ...
- Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync.fsync与fdatasync Linux中的内存大页面huge page/large page David Cut ...
- [数据清洗]- Pandas 清洗“脏”数据(三)
预览数据 这次我们使用 Artworks.csv ,我们选取 100 行数据来完成本次内容.具体步骤: 导入 Pandas 读取 csv 数据到 DataFrame(要确保数据已经下载到指定路径) D ...
- MATLAB 显示输出数据的三种方式
MATLAB 显示输出数据的三种方式 ,转载 https://blog.csdn.net/qq_35318838/article/details/78780412 1.改变数据格式 当数据重复再命令行 ...
随机推荐
- CentOS7 Docker容器无法ping通宿主机ip问题解决记录
Docker服务部署启动容器发现docker容器内访问宿主机IP不通,于是进入容器内ping宿主机IP,发现无法ping通,容器IP为172.17.0.2,于是继续ping172.17.0.1也不通, ...
- Redis事件机制
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件: 文件事件:Redis通过套接字与客户端连接,文件事件是服务器对套接字操作的抽象. 时间事件:Redis服务器中的一些操作需要给定的时间 ...
- oracle dg failover灾难切换
oracle dg failover灾难切换SQL> alter database recover managed standby database finish force;SQL> a ...
- transformers---BERT
transformers---BERT BERT模型主要包括两个部分,encoder和decoder,encoder可以理解为一个加强版的word2vec模型,以下是对于encoder部分的内容 预训 ...
- 实现前后端分离,最好的方案就是SPA(Single Page Application)
从通常意义来讲,说到必须,就是指最佳实践上,实现前后端分离,最好的方案就是SPA.所以才会有 前后端分离=SPA 的近似,忽视了其中的差别.但是,既然有疑问了,我们就来看一下,为什么SPA是实现前后端 ...
- 内网渗透DC-5靶场通关
个人博客地址:点我 DC系列共9个靶场,本次来试玩一下一个 DC-5,只有一个flag,下载地址. 下载下来后是 .ova 格式,建议使用vitualbox进行搭建,vmware可能存在兼容性问题.靶 ...
- dubbo注册中心占位符无法解析问题
dubbo注册中心占位符无法解析问题 1.背景 最近搞了2个老项目,想把他们融合到一起.这俩项目情况简介如下: 项目一:基于SpringMVC + dubbo,配置读取本地properties文件,少 ...
- HttpRunner3.X - 实现参数化驱动
一.前言 HttpRunner3.X支持三种方式的参数化,参数名称的定义分为两种情况: 独立参数单独进行定义: 多个参数具有关联性的参数需要将其定义在一起,采用短横线(-)进行连接. 数据源指定支持三 ...
- Unity 制作不规则形状button
在游戏开发中,我们有时需要制作不规则形状的按键. Unity3d中使用UGUI的Button控件只能实现规则的长方形按钮.而通过给Button的Image组件添加对应的贴图(sprite)我们可以实现 ...
- git常用的一些简单命令
1.如果一个文件被修改了,但是还没有使用 git add 命令,此时想取消这次修改,需要执行的命令如下: git checkout -- 文件名 2.如果一个文件执行了 git add ,此时想取消这 ...