python 回归分析
一、线性回归
1 绘制散点图
import matplotlib.pyplot as plt x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
y = [99,86,87,88,111,86,103,87,94,78,77,85,86] plt.scatter(x, y)
plt.show()
结果:
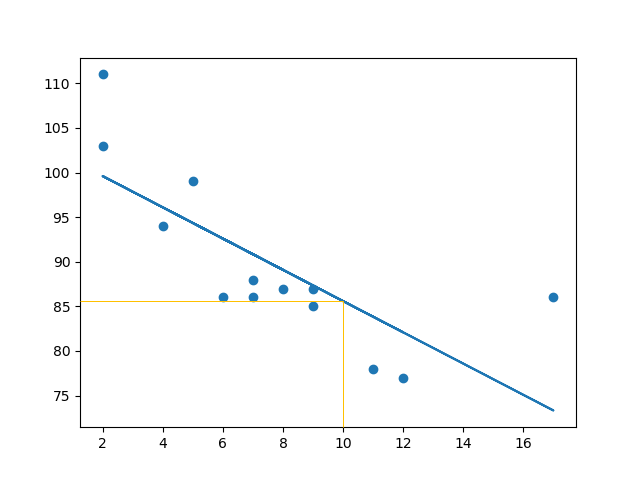
2 导入 scipy 并绘制线性回归线:
import matplotlib.pyplot as plt
from scipy import stats x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
y = [99,86,87,88,111,86,103,87,94,78,77,85,86] slope, intercept, r, p, std_err = stats.linregress(x, y) def myfunc(x):
return slope * x + intercept mymodel = list(map(myfunc, x)) plt.scatter(x, y)
plt.plot(x, mymodel)
plt.show()
结果:
二、多项式回归
如果数据点显然不适合线性回归(穿过数据点之间的直线),那么多项式回归可能是理想的选择。像线性回归一样,多项式回归使用变量 x 和 y 之间的关系来找到绘制数据点线的最佳方法。
1 绘制散点图
import matplotlib.pyplot as plt x = [1,2,3,5,6,7,8,9,10,12,13,14,15,16,18,19,21,22]
y = [100,90,80,60,60,55,60,65,70,70,75,76,78,79,90,99,99,100] plt.scatter(x, y)
plt.show()
结果:
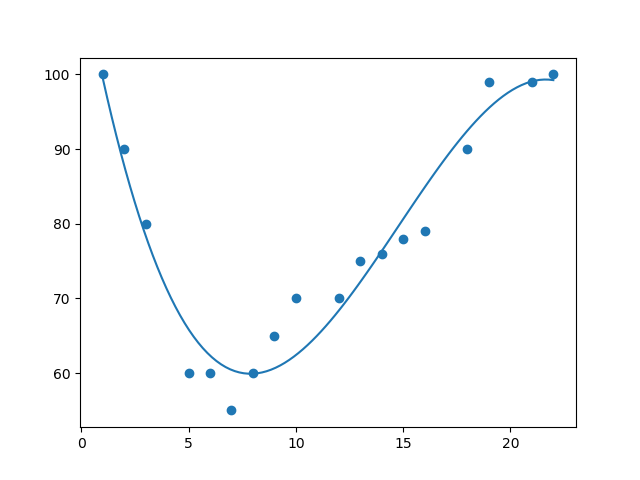
2 导入 numpy 和 matplotlib,然后画出多项式回归线:
import numpy
import matplotlib.pyplot as plt x = [1,2,3,5,6,7,8,9,10,12,13,14,15,16,18,19,21,22]
y = [100,90,80,60,60,55,60,65,70,70,75,76,78,79,90,99,99,100] mymodel = numpy.poly1d(numpy.polyfit(x, y, 3)) myline = numpy.linspace(1, 22, 100) plt.scatter(x, y)
plt.plot(myline, mymodel(myline))
plt.show()
结果
R-Squared
重要的是要知道 x 轴和 y 轴的值之间的关系有多好,如果没有关系,则多项式回归不能用于预测任何东西。
该关系用一个称为 r 平方( r-squared)的值来度量。
r 平方值的范围是 0 到 1,其中 0 表示不相关,而 1 表示 100% 相关。
Python 和 Sklearn 模块将为您计算该值,您所要做的就是将 x 和 y 数组输入:
import numpy
from sklearn.metrics import r2_score x = [1,2,3,5,6,7,8,9,10,12,13,14,15,16,18,19,21,22]
y = [100,90,80,60,60,55,60,65,70,70,75,76,78,79,90,99,99,100] mymodel = numpy.poly1d(numpy.polyfit(x, y, 3)) print(r2_score(y, mymodel(x)))
三、多元回归
多元回归就像线性回归一样,但是具有多个独立值,这意味着我们试图基于两个或多个变量来预测一个值。
在 Python 中,我们拥有可以完成这项工作的模块。首先导入 Pandas 模块:
import pandas
Pandas 模块允许我们读取 csv 文件并返回一个 DataFrame 对象。
此文件仅用于测试目的,您可以在此处下载:cars.csv
df = pandas.read_csv("cars.csv")
然后列出独立值,并将这个变量命名为 X。
将相关值放入名为 y 的变量中。
X = df[['Weight', 'Volume']]
y = df['CO2']
提示:通常,将独立值列表命名为大写 X,将相关值列表命名为小写 y。
我们将使用 sklearn 模块中的一些方法,因此我们也必须导入该模块:
from sklearn import linear_model
在 sklearn 模块中,我们将使用 LinearRegression() 方法创建一个线性回归对象。
该对象有一个名为 fit() 的方法,该方法将独立值和从属值作为参数,并用描述这种关系的数据填充回归对象:
regr = linear_model.LinearRegression()
regr.fit(X, y)
现在,我们有了一个回归对象,可以根据汽车的重量和排量预测 CO2 值:
# 预测重量为 2300kg、排量为 1300ccm 的汽车的二氧化碳排放量: predictedCO2 = regr.predict([[2300, 1300]])
完整实例:
import pandas
from sklearn import linear_model df = pandas.read_csv("cars.csv") X = df[['Weight', 'Volume']]
y = df['CO2'] regr = linear_model.LinearRegression()
regr.fit(X, y) # 预测重量为 2300kg、排量为 1300ccm 的汽车的二氧化碳排放量: predictedCO2 = regr.predict([[2300, 1300]]) print(predictedCO2)
打印回归对象系数值
import pandas
from sklearn import linear_model df = pandas.read_csv("cars.csv") X = df[['Weight', 'Volume']]
y = df['CO2'] regr = linear_model.LinearRegression()
regr.fit(X, y) print(regr.coef_)
python 回归分析的更多相关文章
- python回归分析五部曲
Python回归分析五部曲(一)—简单线性回归 https://blog.csdn.net/jacky_zhuyuanlu/article/details/78878405?ref=myread Py ...
- Python回归分析五部曲(二)—多重线性回归
基础铺垫 多重线性回归(Multiple Linear Regression) 研究一个因变量与多个自变量间线性关系的方法 在实际工作中,因变量的变化往往受几个重要因素的影响,此时就需要用2个或2个以 ...
- Python回归分析五部曲(一)—简单线性回归
回归最初是遗传学中的一个名词,是由英国生物学家兼统计学家高尔顿首先提出来的,他在研究人类身高的时候发现:高个子回归人类的平均身高,而矮个子则从另一方向回归人类的平均身高: 回归分析整体逻辑 回归分析( ...
- Python回归分析五部曲(三)—一元非线性回归
(一)基础铺垫 一元非线性回归分析(Univariate Nonlinear Regression) 在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条曲线近似表示,则称为一元非线性回归 ...
- python回归分析
假设原函数由一个三角函数和一个线性项组成 import numpy as np import matplotlib.pyplot as plt %matplotlib inline def f(x): ...
- 个股与指数的回归分析(自带python ols 参数解读)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- 利用Spark-mllab进行聚类,分类,回归分析的代码实现(python)
Spark作为一种开源集群计算环境,具有分布式的快速数据处理能力.而Spark中的Mllib定义了各种各样用于机器学习的数据结构以及算法.Python具有Spark的API.需要注意的是,Spark中 ...
- $用python玩点有趣的数据分析——一元线性回归分析实例
Refer:http://python.jobbole.com/81215/ 本文参考了博乐在线的这篇文章,在其基础上加了一些自己的理解.其原文是一篇英文的博客,讲的通俗易懂. 本文通过一个简单的例子 ...
- 回归分析特征选择(包括Stepwise算法) python 实现
# -*- coding: utf-8 -*-"""Created on Sat Aug 18 16:23:17 2018 @author: acadsoc"& ...
随机推荐
- PDMan使用
场景: 这几天项目要完结交付,需要补很多文档.此时发现甲方要求提供数据库设计文档,尽管我觉得他们不会看,但是人家要求,还是补一下吧!时间紧迫,要赶出整个项目的数据库设计文档比较麻烦,每个两三天不行.于 ...
- AWS 安全信息泄露-----21天烧了27万
安全问题一直都是个老生常谈的话题,对于我们做IT的来说,是更为重视的.从使用开发工具的是否授权合规,到从事的工作内容是否合法.我们都应该认真的思考一下这些问题,毕竟我们要靠IT这门手艺吃饭. 2021 ...
- Azure安装完postgresql遇到:psql: error: could not connect to server: FATAL: no pg_hba.conf entry for host
进入创建好的Azure Database for PostgreSQL server 点击connection security 在Firewall rules中 Add 0.0.0.0-255.2 ...
- Wireshark过滤器详解
Wireshark过滤器详解 1.Wireshark主要提供两种主要的过滤器 捕获过滤器:当进行数据包捕获时,只有那些满足给定的包含/排除表达式的数据包会被捕获 显示过滤器:该过滤器根据指定的表达式用 ...
- 手动实现instanceof函数
instanceof 功能 a instanceof b 官方解释为检查构造函数b的prototype 有没有出现在a的原型链上.比如: function A() { } function B() { ...
- 我,Android开发5年,32岁失业,现实给我狠狠上了一课!
如今的职场,风险是越来越高,不管你是应届生或者你是否中年,遇到好点的企业,红火那么做个三五年,运气不好,半年甚至2.3个月也就玩完了. 所以,即使你希望工作能稳定,但也会让你大失所望,职场寿命就那么几 ...
- 使用 Service Worker 缓解网站 DDOS 攻击
前言 传统的 DDOS 防御开销很大,而且有时效果并不好. 例如使用 DNS 切换故障 IP 的方案,由于域名会受到缓存等因素的影响通常有分钟级延时,前端难以快速生效.例如使用 CDN 服务,虽可抵挡 ...
- Subversion Backup and Restore
Backup Specified Revision Backup specified revision (here is 20): $ cd /opt/svnRepo $ svnadmin dump ...
- vue3 自己做一个轻量级状态管理,带跟踪功能,知道是谁改的,还能定位代码。
上一篇 https://www.cnblogs.com/jyk/p/14706005.html 介绍了一个自己做的轻量级的状态管理,好多网友说,状态最重要的是跟踪功能,不能跟踪算啥状态管理? 因为vu ...
- 分享一份【饿了么】Java面试专家岗面试题,欢迎留言交流哦!
前段时间有小伙伴去饿了么面试Java专家岗,记录了一面技术相关的问题,大家可以看看. 基础问题 1.数据库事务的隔离级别? 2.事务的几大特性,并谈一下实现原理 3.如何用redis实现消息的发布订阅 ...