Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比
Flink介绍
截止2021年10月Flink最新的稳定版本已经发展到1.14.0
Flink起源于一个名为Stratosphere的研究项目主要是为了构建下一代大数据分析平台,在2014年成为Apache孵化器项目。2019 年 1 月,阿里巴巴实时计算团队宣布将经过双十一历练和集团内部业务打 磨的 Blink 引擎进行开源并向 Apache Flink 贡献代码,为Flink迎来了一次高速发展,此后的一年中,阿里巴巴实时计算团队与 Apache Flink 社区密切合作,持续推进 Flink 对 Blink 的整合。 2 月 12 日Apache Flink 1.10.0 正式发布,在 Flink 的第一个双位数版本中正 式完成了 Blink 向 Flink 的合并。在此基础之上,Flink 1.10 版本在生产可用性、 功能、性能上都有大幅提升。 Flink 1.10 是迄今为止规模最大的一次版本升级,除标志着 Blink 的合并完成 外,还实现了 Flink 作业的整体性能及稳定性的显著优化、还包括对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化等。
Apache Flink 是一个计算框架和分布式处理引擎,用于在无边界数据流和有边界的数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。目前Flink 也是 Apache 软件基金会和 GitHub 社区最为活跃的项目之一也是公认的新一代开源大数据计算引擎,可以支持流处理、 批处理和机器学习等多种计算形态。
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种数据流。在Flink上数据可以被作为 无界 或者 有界 流来处理。
- 无界数据流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界数据流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流的处理通常被称为批处理。
我们知道大数据起源于批处理,随着发展大数据的计算模式随后主要分为批量计算(batch computing)、流式计算(stream computing)、交互计算(interactive computing)、图计算(graph computing)等。其中,流式计算和批量计算是两种主要的大数据计算模式,分别适用于不同的大数据应用场景。在批处理上,Spark有很深的积累。为了应对全球大量业务的实时需求,Spark也推出了流计算解决方案——SparkStreaming。但Spark毕竟不是一款纯流式计算引擎,所以在时效性等问题上,始终无法提供极致的流批一体体验。另外一个流计算方案是Storm,Storm和Flink这两者在概念上更相近。这也是目前主流的三种流式计算框架。
Apache Spark
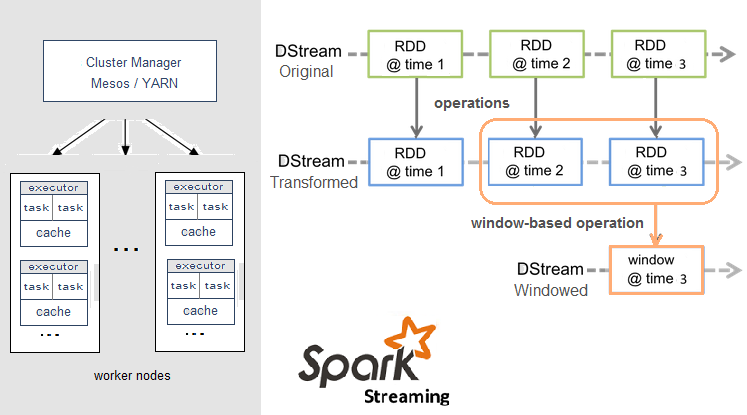
Spark Streaming,即核心Spark API的扩展,不像Storm那样一次处理一个数据流。相反,它在处理数据流之前,会按照时间间隔对数据流进行分段切分。Spark针对连续数据流的抽象,我们称为DStream(Discretized Stream)。 DStream是小批处理的RDD(弹性分布式数据集), RDD则是分布式数据集,可以通过任意函数和滑动数据窗口(窗口计算)进行转换,实现并行操作。
Apache Storm
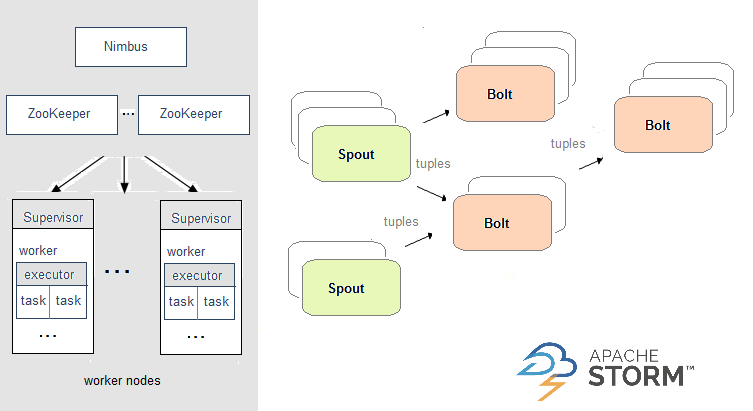
在Storm中,需要先设计一个实时计算结构,我们称之为拓扑(topology)。之后,这个拓扑结构会被提交给集群,其中主节点(master node)负责给工作节点(worker node)分配代码,工作节点负责执行代码。在一个拓扑结构中,包含spout和bolt两种角色。数据在spouts之间传递,这些spouts将数据流以tuple元组的形式发送;而bolt则负责转换数据流。
Apache Flink
后起新秀 Flink 的基本数据模型则是数据流,以及事件(Event)的序列。数据流作为数据的基本模型,可以是无边界的无限“流”,即一般意义上的流处理;也可以是有边界的有限“流”,也就同时兼顾了批处理。Flink在实现流式处理和批量处理时,与传统方案完全不同,他从另一个视角看待流式处理和批量处理,将二者统一起来,把批量处理视作一种特殊的流式处理,只是输入数据流被定义为有界的。
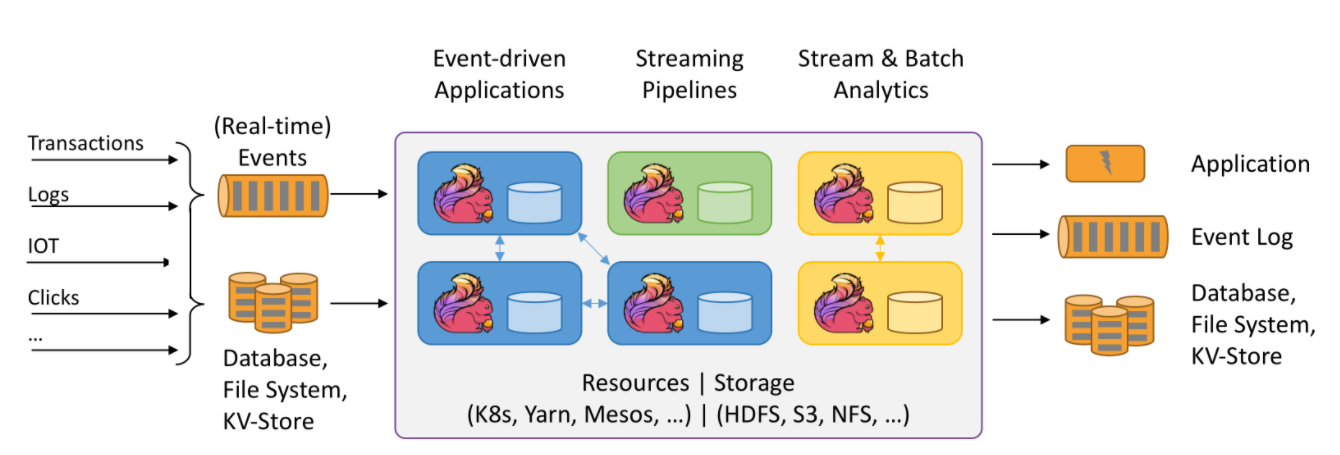
Apache Flink是一个统一流处理与批处理的框架。由于流水线数据在并行任务之间进行传输(包括数据的洗牌shuffles),flink在运行时支持流处理与批处理。数据被立刻的传输从生产数据的任务到接受数据的任务(在网络传输中被收集在一个缓存中,然后发送)之后,批处理的任务可以被选择来处理这些阻塞的数据。以下为这三种流计算框架的对比:
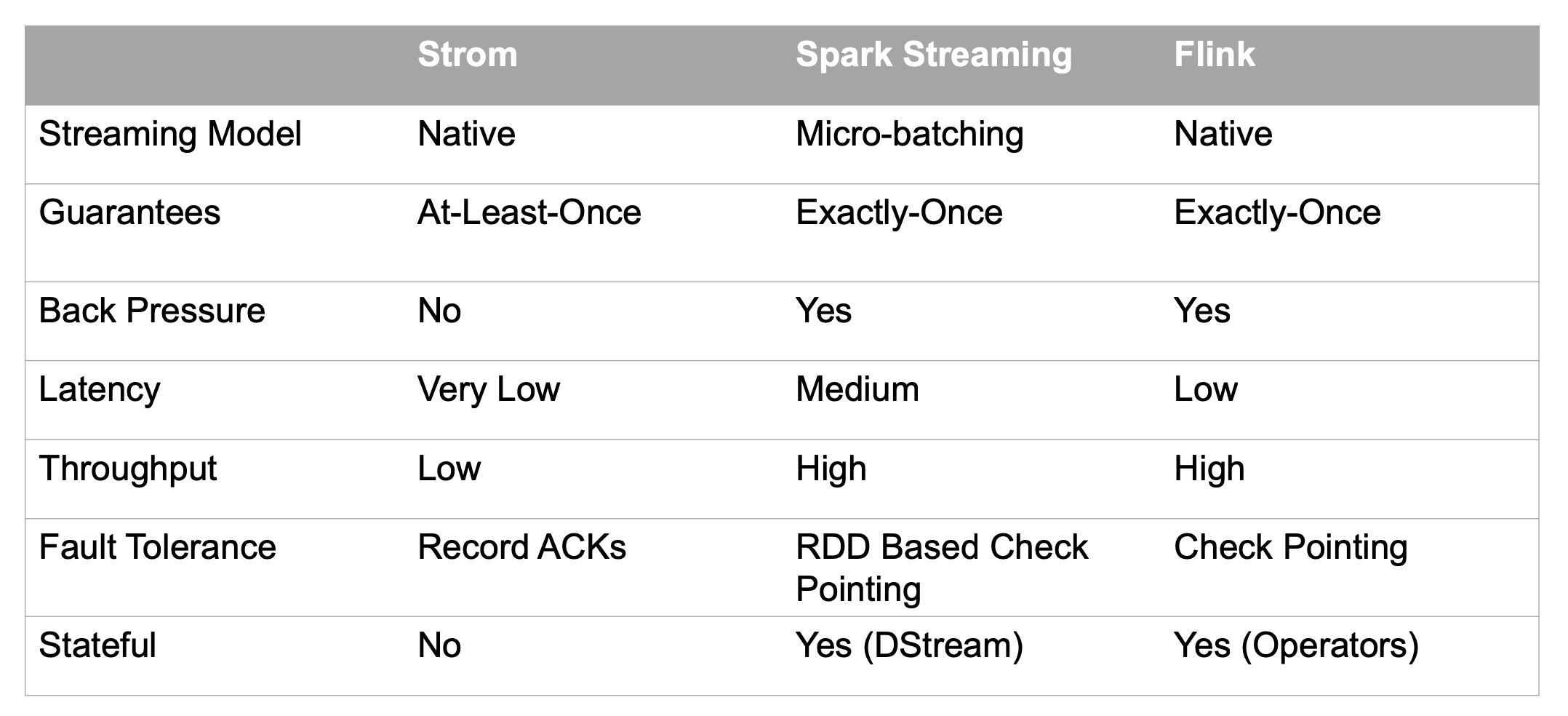
Flink 的批处理api用法案列和Spark 非常相似,但是内部实现不一样。对于处理流来说,两种框架采用了不同的实现使得他们适合于不同场景的应用(Spark 微批处理 vs Flink 流计算),我可以说Spark与Flink的比较是有用有效的。然而Spark却和Flink 不是最相似的流处理引擎。
Apache Storm 只能处理流数据,没有批处理的能力。事实上,Flink的流式处理引擎和Storm很相似,比如 Flink的并行任务和Storm的bolt很相似。他俩都是通过流水线数据的传输来降低数据延时。然而Flink 提供了很多跟高级的api ,Flink的DataStream提供了Map、GroupBy、Window和Join等api来代替storm的bolt在一个或多个readers 和collectors的功能,而Storm在实现这些功能的时候都需要程序员自己实现。另外的不同在于处理语义。Storm提供了"at-least-once "而Flink提供了"exactly-once",两个框架给与语义不同的保证在实现上也就相当的不同。Storm 采用 record-level ack,Flink采用Chandy-Lamport的轻微变种。简言之,在数据源中周期性的注入marker,然后放入数据流中,无论何时只要任务执行器接受到一个marker,执行器检查他的内部状态。当一个marker被所有的数据输出sink给接收到,证明这个marker被提交(在这个marker之前的所有执行的数据,到上一个被提交的marker之后的所以数据)。万一有一个sink没有接受到marker,所有的源操作器将从置他们的处理数据到最近一次确认提交的marker然后继续执行。这种检查标记点的方法比record-level ack更加的轻量级。
Storm也提供了 exactly-once 以及高级api ,但是被称为Trident ,然而Trident 是在微批处理的基础上实现的,就很像Spark了而不是Flink,Flink比Storm的改进还有以下几点:
- 背压:Flink流计算当不同操作器在速度不同的时候表现的很好。因为低速流操作器背压高速流操作器很好,虽然网络层管理控制缓存池。
- 用户定义状态:Flink允许用户在操作器中自定义状态。这个自定义状态可以参与在检查点的容错处理,也提供exactly-once语义支持。在一个操作器中用户自定义机器状态,该状态始终与数据流一起参与checkpoint。
- 流窗口:流窗口和窗口聚合是数据流分析的重要组成部分。Flink配备了一个非常强大的窗口系统,支持多种类型的窗口。
Flink特性
作为新一代大数据计算框架,其各种新特性让开发者在处理实时计算技术选型上眼前一亮。
- 有状态计算的exactly-once语义。状态是指Flink能够维护数据在时序上的聚类和聚合,同时它的检查点(checkpoint)机制可以方便、快速地做出失败重试;
- 支持带有事件时间(event time)语义的流式处理和窗口 ( window)处理。事件时间的语义使流计算的结果更加精确,尤其是在事件无序或者延迟的情况下;
- 支持高度灵活的窗口可以方便、快速地做出失败重试操作。包括基于time、count、session,以及 data-driven 的窗口操作,能很好地对现实环境中创建的数据进行建模;
- 轻量的容错处理(fault tolerance)。它使得系统既能保持高吞吐率又能保证exactly-once的一致性,通过轻量的state snapshots实现;
- 支持高吞吐、低延迟、高性能的流式处理;
- 支持保存点(savepoint)机制(一般为手动触发)。即可以将应用的运行状态保存下来,在升级应用或者处理历史数据时能够做到无状态丢失和停机时间最小;
- 支持大规模的集群模式。支持YARN、Mesos,k8s可运行在成千上万的节点上;
- 支持具有背压( backpressure)功能的持续流模型;
- 支持迭代计算;
- JVM内部实现了自己的内存管理。它支持程序自动优化,例如能避免特定情况下的Shuffle、排序等昂贵操作,能对中间结果进行缓存;
- 支持Java、Python、Scala;
- 支持复杂事件处理(CEP);
- 支持以SQL的方式开发流式应用;
Flink编程模型
Flink 为流式/批式处理应用程序的开发提供了不同级别的抽象。

Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态。此外,用户可以在此层抽象中注册事件时间(event time)和处理时间(processing time)回调方法,从而允许程序可以实现复杂计算。
Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)和 DataSet API(应用于有界数据集场景)两部分。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
Process Function 这类底层抽象和 DataStream API 的相互集成使得用户可以选择使用更底层的抽象 API 来实现自己的需求。DataSet API 还额外提供了一些原语,比如循环/迭代(loop/iteration)操作。
Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。Table API 遵循(扩展)关系模型:即表拥有 schema(类似于关系型数据库中的 schema),并且 Table API 也提供了类似于关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以声明的方式定义应执行的逻辑操作,而不是确切地指定程序应该执行的代码。尽管 Table API 使用起来很简洁并且可以由各种类型的用户自定义函数扩展功能,但还是比 Core API 的表达能力差。此外,Table API 程序在执行之前还会使用优化器中的优化规则对用户编写的表达式进行优化。
表和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。
Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。
参考:
https://stackoverflow.com/questions/30699119/what-is-are-the-main-differences-between-flink-and-storm
https://www.javacodegeeks.com/2015/02/streaming-big-data-storm-spark-samza.html
福小嗨
Flink入门-第一篇:Flink基础概念以及竞品对比的更多相关文章
- 【Kafka入门】Kafka入门第一篇:基础概念篇
Kafka简介 Kafka是一个消息系统服务框架,它以提交日志的形式存储消息,并且消息的存储是分布式的,为了提供并行性和容错保障,消息的存储是分区冗余形式存在的. Kafka的架构 Kafka中包含以 ...
- LWJGL3的内存管理,第一篇,基础知识
LWJGL3的内存管理,第一篇,基础知识 为了讨论LWJGL在内存分配方面的设计,我将会分为数篇随笔分开介绍,本篇将主要介绍一些大方向的问题和一些必备的知识. 何为"绑定(binding)& ...
- 【UML】NO.70.EBook.9.UML.4.001-【PowerDesigner 16 从入门到精通】- 基础概念
1.0.0 Summary Tittle:[UML]NO.70.EBook.9.UML.4.001-[PowerDesigner 16 从入门到精通]- 基础概念 Style:DesignPatte ...
- ElasticSearch入门 第一篇:Windows下安装ElasticSearch
这是ElasticSearch 2.4 版本系列的第一篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- 新一代分布式实时流处理引擎Flink入门实战操作篇
@ 目录 安装部署 安装方式 Local(Standalone 单机部署) Standalone部署 Standalone HA部署 Flink On Yarn演示案例 概述 会话(Session)模 ...
- Python【第一篇】基础介绍
一.本节主要内容 Python介绍 发展史 Python 2 or 3? 安装 Hello World程序 变量 用户输入 模块初识 .pyc文件 数据类型初识 数据运算 表达式if ...else语 ...
- Zookeeper 入门第一篇
转载原文地址: ZooKeeper学习总结 第一篇:ZooKeeper快速入门 ZooKeeper学习总结 第二篇:ZooKeeper深入探讨 ZooKeeper学习第一期---Zookeeper简单 ...
- oracle系列--第一篇 数据库基础
第一章 数据库基础 1.1 数据管理概述 1.1.1 什么是数据管理 与我们人类相比,计算机的最大优势就是能够高速.精准地运行,其运行的过程就是执行程序代码和操作指令.处理数据的过程.可以说,数据处理 ...
- excel的宏与VBA入门(一)——基础概念
一.概述 "记录宏"其实就是将工作的一系列操作结果录制下来,并命名存储(相当于VB中一个子程序). 宏其实就是VBA写的,但是可以通过录制的方法制作宏,做好的宏你可以查看相应的VB ...
随机推荐
- 查看Win10商店应用更新日期
查看Win10商店应用更新日期 需要用到一个工具--WP Snitch,网址 https://wpsnitch.appspot.com/ 打开网址后他会给出一个示例,比如给出的是 https://ww ...
- 我下载了python所有包,用以备份,有需要的自提
1.背景 我最近准备把1985年-2019年的全国30m分辨率土地利用数据按照地级市进行裁剪与归纳,这需要用到Geopandas对shp数据进行批量操作.在安装Geopandas的python包时,遇 ...
- 做PPT总是很难找到好看、有质感的图片,怎么办?
1.制作PPT时,要想提升整体质感,就需要插入一些图片.当你进入到这个阶段,就意味着你剩下用来做PPT的时间,可能比较紧张了.所以,你的重中之重是,在最短的时间内找到合适的照片. 2.想快速找到好看. ...
- Visual Studio Code (VSCode) 配置 C/C++ 开发编译环境
前言 工作多年,突然发现很多C++的基础都忘记了,加之C++不断更新换代后的各种新特性,于是想重拾C++的基础学习.虽然现在工作都是Linux平台,但考虑到个人方便,自己也仅仅想重温语法,家里家外都可 ...
- 关于docker复现vulhub环境的搭建
原本想用docker复现一下vul的漏洞. 装docker过程中遇到了很多问题, 昨天熬夜到凌晨三点都没弄完. 中午又找了找原因,终于全部解决了, 小结一下. 0x01 镜像 去官方下载了centos ...
- python-docx 页面设置
初识word文档-节-的概念 编辑一篇word文档,往往首先从页面设置开始,从下图可以看出,页面设置常操作的有页边距.纸张方向.纸张大小4个,而在word中是以节(section)来分大的块,每一节的 ...
- SAE助力南瓜电影7天内全面Severless
作者:李刚(寻如),阿里云解决方案架构师 南瓜电影APP是国内领先的专注于影视精品化运营的垂直类视频产品,在移动互联网.IPTV.OTT等客户端,面向广大中产阶级精英群体,提供有异于院线及其他视频平台 ...
- Winfrom窗体初始化和窗体Load方法前后
运行结果为 [窗体初始化之前!]>[窗体初始化!]>[窗体Load!]
- pip 命令总结
建议和 Conda 命令一起看,pip 和conda命令有点相似.<Conda 命令> 1 查看帮助文档 pip --help 使用该命令将告诉你 pip 的常用命令. 使用时,输入pip ...
- 2020.5.17--牛客小白月赛25 F.疯狂的自我检索者
F.疯狂的自我检索者 链接:https://ac.nowcoder.com/acm/contest/5600/F来源:牛客网 牛妹作为偶像乐队的主唱,对自己的知名度很关心.她平时最爱做的事就是去搜索引 ...