高并发场景下JVM调优实践之路
一、背景
2021年2月,收到反馈,视频APP某核心接口高峰期响应慢,影响用户体验。
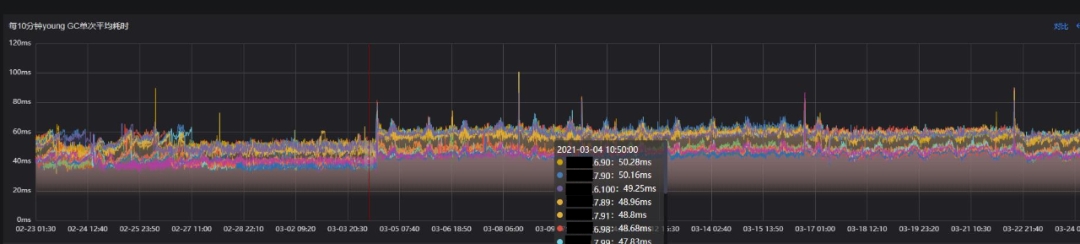
通过监控发现,接口响应慢主要是P99耗时高引起的,怀疑与该服务的GC有关,该服务典型的一个实例GC表现如下图:
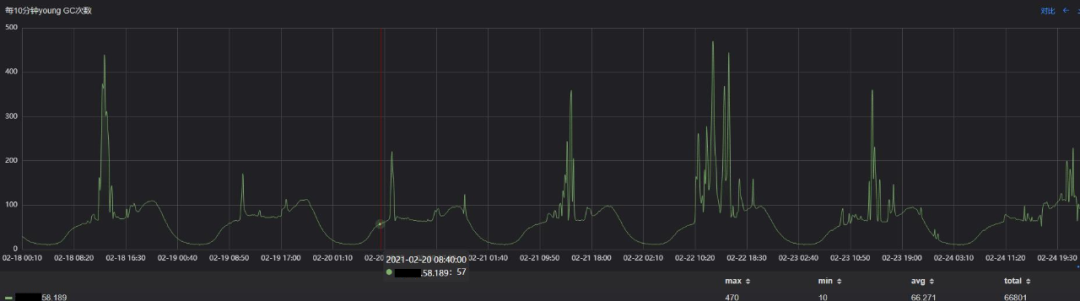
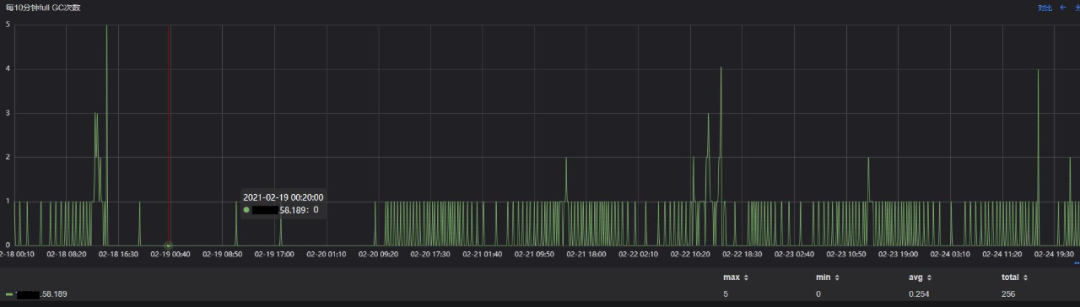
可以看出,在观察周期里:
平均每10分钟Young GC次数66次,峰值为470次;
平均每10分钟Full GC次数0.25次,峰值5次;
可见Full GC非常频繁,Young GC在特定的时段也比较频繁,存在较大的优化空间。由于对GC停顿的优化是降低接口的P99时延一个有效的手段,所以决定对该核心服务进行JVM调优。
二、优化目标
接口P99时延降低30%
减少Young GC和Full GC次数、停顿时长、单次停顿时长
由于GC的行为与并发有关,例如当并发比较高时,不管如何调优,Young GC总会很频繁,总会有不该晋升的对象晋升触发Full GC,因此优化的目标根据负载分别制定:
目标1:高负载(单机1000 QPS以上)
Young GC次数减少20%-30% ,Young GC累积耗时不恶化;
Full GC次数减少50%以上,单次、累积Full GC耗时减少50%以上,服务发布不触发Full GC。
目标2:中负载(单机500-600)
Young GC次数减少20%-30% ,Young GC累积耗时减少20%;
Full GC次数不高于4次/天,服务发布不触发Full GC。
目标3:低负载(单机200 QPS以下)
Young GC次数减少20%-30% ,Young GC累积耗时减少20%;
Full GC次数不高于1次/天,服务发布不触发Full GC。
三、当前存在的问题
当前服务的JVM配置参数如下:
-Xms4096M -Xmx4096M -Xmn1024M
-XX:PermSize=512M
-XX:MaxPermSize=512M
单纯从参数上分析,存在以下问题:
**未显示指定收集器 **
JDK 8默认搜集器为ParrallelGC,即Young区采用Parallel Scavenge,老年代采用Parallel Old进行收集,这套配置的特点是吞吐量优先,一般适用于后台任务型服务器。
比如批量订单处理、科学计算等对吞吐量敏感,对时延不敏感的场景,当前服务是视频与用户交互的门户,对时延非常敏感,因此不适合使用默认收集器ParrallelGC,应选择更合适的收集器。

Young区配比不合理
当前服务主要提供API,这类服务的特点是常驻对象会比较少,绝大多数对象的生命周期都比较短,经过一次或两次Young GC就会消亡。
再看下当前JVM配置:
整个堆为4G,Young区总共1G,默认-XX:SurvivorRatio=8,即有效大小为0.9G,老年代常驻对象大小约400M。
这就意味着,当服务负载较高,请求并发较大时,Young区中Eden + S0区域会迅速填满,进而Young GC会比较频繁。
另外会引起本应被Young GC回收的对象过早晋升,增加Full GC的频率,同时单次收集的区域也会增大,由于Old区使用的是ParralellOld,无法与用户线程并发执行,导致服务长时间停顿,可用性下降, P99响应时间上升。
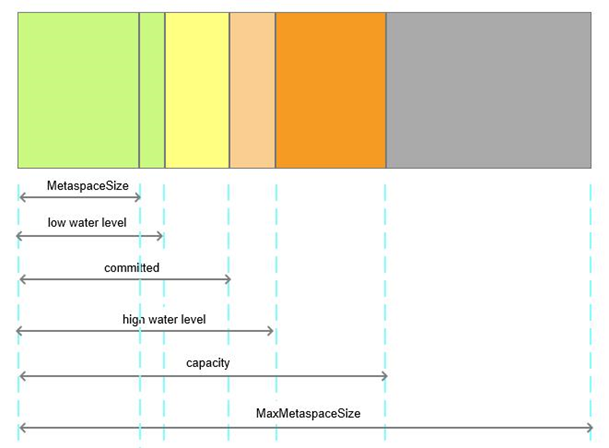
未设置
-XX:MetaspaceSize和-XX:MaxMetaspaceSize
Perm区在jdk 1.8已经过时,被Meta区取代,
因此-XX:PermSize=512M -XX:MaxPermSize=512M配置会被忽略,
真正控制Meta区GC的参数为
-XX:MetaspaceSize:
Metaspace初始大小,64位机器默认为21M左右
-XX:MaxMetaspaceSize:
Metaspace的最大值,64位机器默认为18446744073709551615Byte,
可以理解为无上限
-XX:MaxMetaspaceExpansion:
增大触发metaspace GC阈值的最大要求
-XX:MinMetaspaceExpansion:
增大触发metaspace GC阈值的最小要求,默认为340784Byte
这样服务在启动和发布的过程中,元数据区域达到21M时会触发一次Full GC (Metadata GC Threshold),随后随着元数据区域的扩张,会夹杂若干次Full GC (Metadata GC Threshold),使服务发布稳定性和效率下降。
此外如果服务使用了大量动态类生成技术的话,也会因为这个机制产生不必要的Full GC (Metadata GC Threshold)。
四、优化方案/验证方案
上面已分析出当前配置存在的较为明显的不足,下面优化方案主要先针对性解决这些问题,之后再结合效果决定是否继续深入优化。
当前主流/优秀的搜集器包含:
Parrallel Scavenge + Parrallel Old:吞吐量优先,后台任务型服务适合;
ParNew + CMS:经典的低停顿搜集器,绝大多数商用、延时敏感的服务在使用;
G1:JDK 9默认搜集器,堆内存比较大(6G-8G以上)的时候表现出比较高吞吐量和短暂的停顿时间;
ZGC:JDK 11中推出的一款低延迟垃圾回收器,目前处在实验阶段;
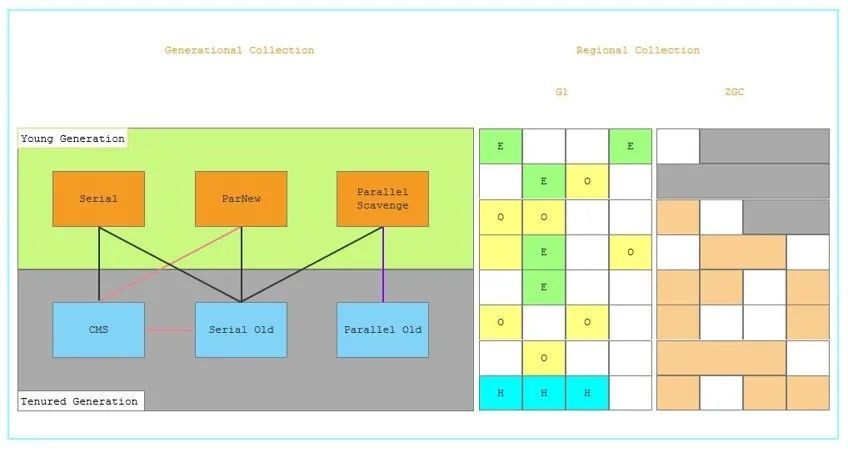
结合当前服务的实际情况(堆大小,可维护性),我们选择ParNew + CMS方案是比较合适的。
参数选择的原则如下:
1)Meta区域的大小一定要指定,且MetaspaceSize和MaxMetaspaceSize大小应设置一致,具体多大要结合线上实例的情况,通过jstat -gc可以获取该服务线上实例的情况。
# jstat -gc 31247
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
37888.0 37888.0 0.0 32438.5 972800.0 403063.5 3145728.0 2700882.3 167320.0 152285.0 18856.0 16442.4 15189 597.209 65 70.447 667.655
可以看出MU在150M左右,因此-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M是比较合理的。
2)Young区也不是越大越好。
当堆大小一定时,Young区越大,Young GC的频率一定越小,但Old区域就会变小,如果太小,稍微晋升一些对象就会触发Full GC得不偿失。
如果Young区过小,Young GC就会比较频繁,这样Old区就会比较大,单次Full GC的停顿就会比较大。因此Young区的大小需要结合服务情况,分几种场景进行比较,最终获得最合适的配置。
基于以上原则,以下为4种参数组合:
1.ParNew +CMS,Young区扩大1倍
-Xms4096M -Xmx4096M -Xmn2048M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
2.ParNew +CMS,Young区扩大1倍,
去除-XX:+CMSScavengeBeforeRemark(使用【-XX:CMSScavengeBeforeRemark】参数可以做到在重新标记前先执行一次新生代GC)。
因为老年代和年轻代之间的对象存在跨代引用,因此老年代进行GC Roots追踪时,同样也会扫描年轻代,而如果能够在重新标记前先执行一次新生代GC,那么就可以少扫描一些对象,重新标记阶段的性能也能因此提升。)
-Xms4096M -Xmx4096M -Xmn2048M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
3.ParNew +CMS,Young区扩大0.5倍
-Xms4096M -Xmx4096M -Xmn1536M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
4.ParNew +CMS,Young区不变
-Xms4096M -Xmx4096M -Xmn1024M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
下面,我们需要在压测环境,对不同负载下4种方案的实际表现进行比较,分析,验证。
4.1 压测环境验证/分析
高负载场景(1100 QPS)GC表现

可以看出,在高负载场景,4种ParNew + CMS的各项指标表现均远好于Parrallel Scavenge + Parrallel Old。其中:
方案4(Young区扩大0.5倍)表现最佳,接口P95,P99延时相对当前方案降低50%,Full GC累积耗时减少88%, Young GC次数减少23%,Young GC累积耗时减少4%,Young区调大后,虽然次数减少了,但Young区大了,单次Young GC的耗时也大概率会上升,这是符合预期的。
Young区扩大1倍的两种方案,即方案2和方案3,表现接近,接口P95,P99延时相对当前方案降低40%,Full GC累积耗时减少81%, Young GC次数减少43%,Young GC累积耗时减少17%,略逊于Young区扩大0.5倍,总体表现不错,这两个方案进行合并,不再区分。
Young区不变的方案在新方案里,表现最差,淘汰。所以在中负载场景,我们只需要对比方案2和方案4。
中负载场景(600 QPS)GC表现

可以看出,在中负载场景,2种ParNew + CMS(方案2和方案4)的各项指标表现也均远好于Parrallel Scavenge + Parrallel Old。
Young区扩大1倍的方案表现最佳,接口P95,P99延时相对当前方案降低32%,Full GC累积耗时减少93%, Young GC次数减少42%,Young GC累积耗时减少44%;
Young区扩大0.5倍的方案稍逊一些。
综合来看,两个方案表现十分接近,原则上两种方案都可以,只是Young区扩大0.5倍的方案在业务高峰期的表现更佳,为尽量保证高峰期服务的稳定和性能,目前更倾向于选择ParNew + CMS,Young区扩大0.5倍方案。
4.2 灰度方案/分析
为保证覆盖业务的高峰期,选择周五、周六、周日分别从两个机房随机选择一台线上实例,线上实例的指标符合预期后,再进行全量升级。
目标组 xx.xxx.60.6
采用方案2,即目标方案
-Xms4096M -Xmx4096M -Xmn1536M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
对照组1 xx.xxx.15.215
采用原始方案
-Xms4096M -Xmx4096M -Xmn1024M
-XX:PermSize=512M
-XX:MaxPermSize=512M
对照组2 xx.xxx.40.87
采用方案4,即候选目标方案
-Xms4096M -Xmx4096M -Xmn2048M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
灰度3台机器。
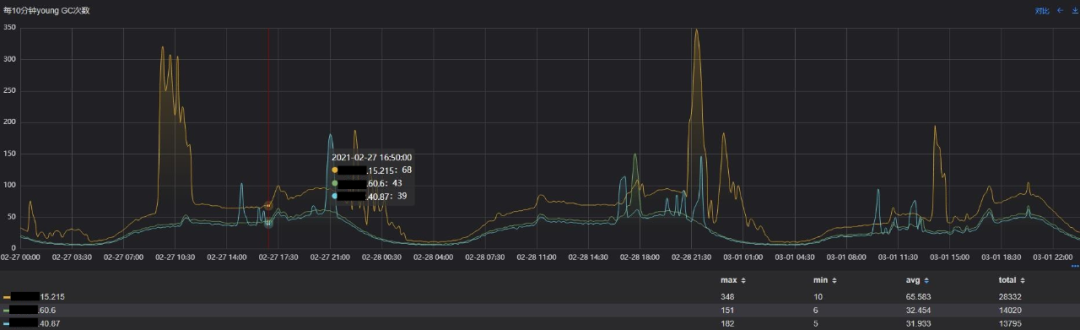
我们先分析下Young GC相关指标:
Young GC次数
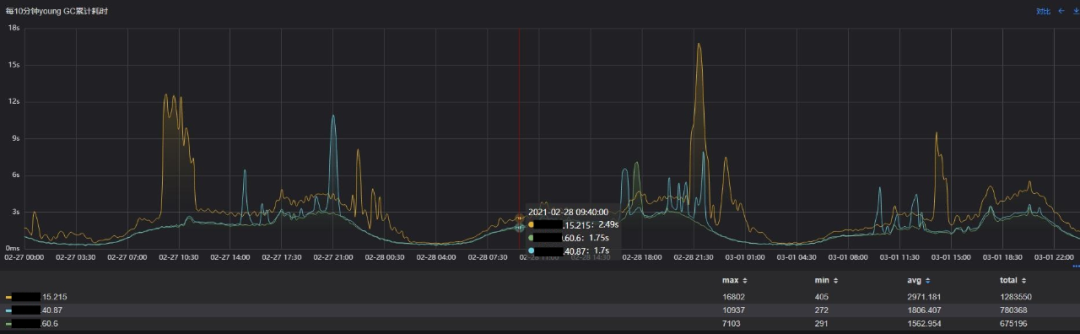
Young GC累计耗时
Young GC单次耗时
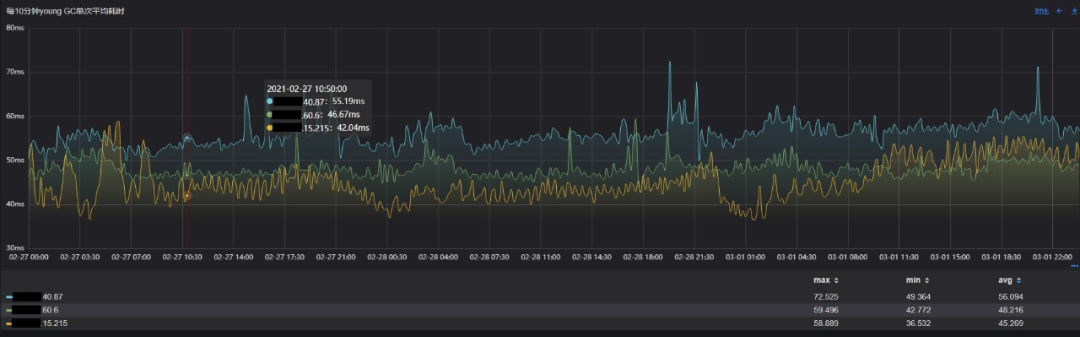
可以看出,与原始方案相比,目标方案的YGC次数减少50%,累积耗时减少47%,吞吐量提升的同时,服务停顿的频率大大降低,而代价是单次Young GC的耗时增长3ms,收益是非常高的。
对照方案2即Young区2G的方案整体表现稍逊与目标方案,再分析Full GC指标。
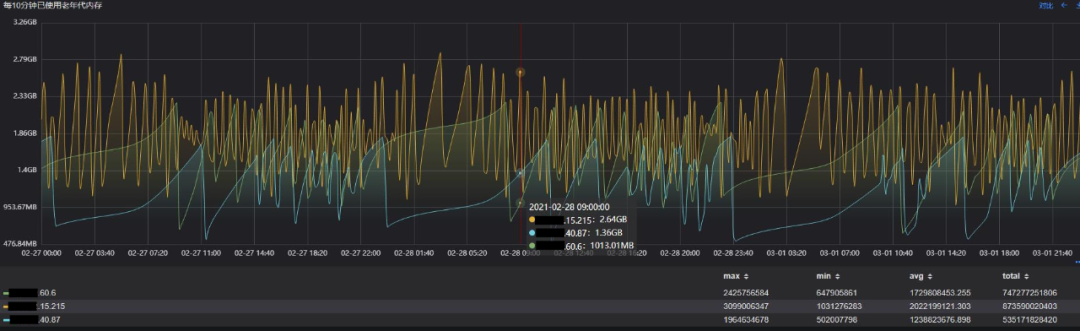
老年代内存增长情况
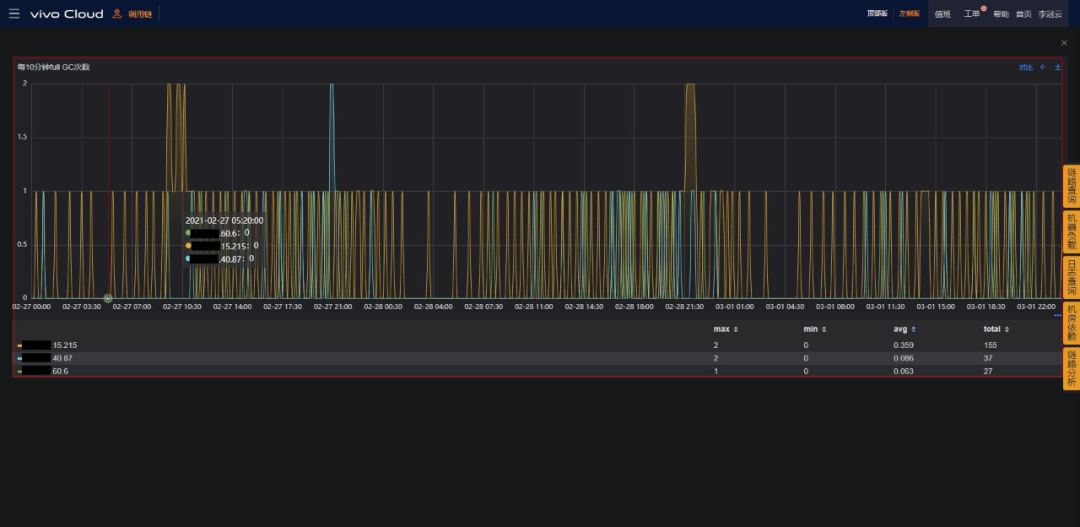
Full GC次数
Full GC累计/单次耗时
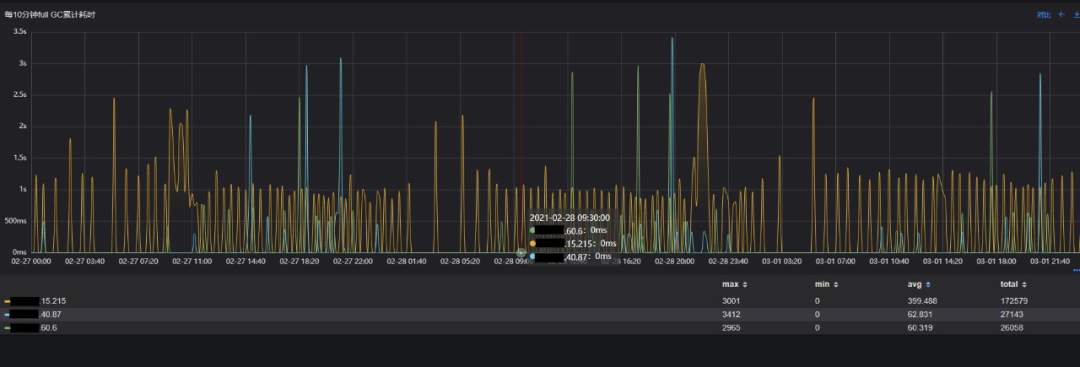
与原始方案相比,使用目标方案时,老年代增长的速度要缓慢很多,基本在观测周期内Full GC发生的次数从155次减少至27次,减少82%,停顿时间均值从399ms减少至60ms,减少85%,毛刺也非常少。
对照方案2即Young区2G的方案整体表现逊于目标方案。到这里,可以看出,目标方案从各个维度均远优于原始方案,调优目标也基本达成。
但细心的同学会发现,目标方案相对原始方案,"Full GC"(实际上是CMS Background GC)耗时更加平稳,但每个若干次"Full GC"后会有一个耗时很高的毛刺出现,这意味这个用户请求在这个时刻会停顿2-3s,能否进一步优化,给用户一个更加极致的体验呢?
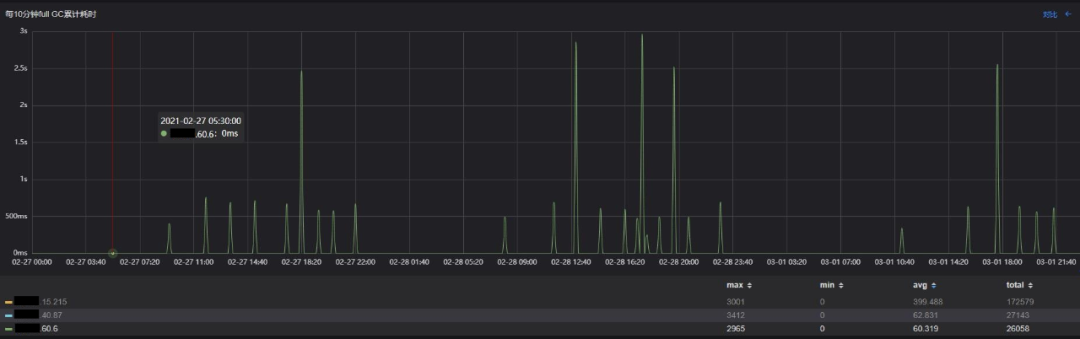
4.3 再次优化
这里首先要分析这现象背后的逻辑。
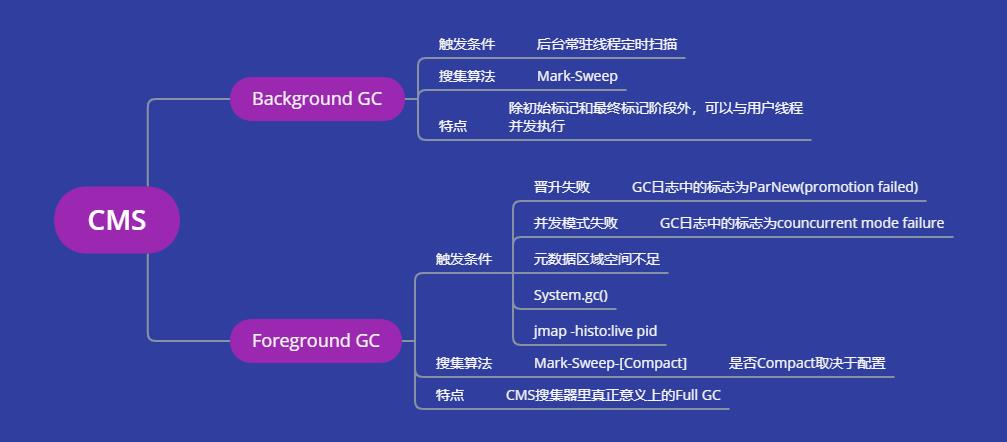
对于CMS搜集器,采用的搜集算法为Mark-Sweep-[Compact]。
CMS搜集器GC的种类:
CMS Background GC
这种GC是CMS最常见的一类,是周期性的,由JVM的常驻线程定时扫描老年代的使用率,当使用率超过阈值时触发,采用的是Mark-Sweep方式,由于没有Compact这种耗时操作,且可以与用户进程并行,所以CMS的停顿会比较低,GC日志中出现GC (CMS Initial Mark)字样就代表发生了一次CMS Background GC。
Background GC由于采用的是Mark-Sweep,会导致老年代内存碎片,这也是CMS最大的弱点。
CMS Foreground GC
这种GC是CMS搜集器里真正意义上的Full GC,采用Serial Old或Parralel Old进行收集,出现的频率就较低,当往往出现后就会造成较大的停顿。
触发CMS Foreground GC的场景有很多,场景的如下:
System.gc();
jmap -histo:live pid;
元数据区域空间不足;
晋升失败,GC日志中的标志为ParNew(promotion failed);
并发模式失败,GC日志中的标志为councurrent mode failure字样。
不难推断,目标方案中的毛刺是晋升失败或并发模式失败造成的,由于线上没有开启打印gc日志,但也无妨,因为这两种场景的根因是一致的,就是若干次CMS Backgroud GC后造成的老年代内存碎片。
我们只需要尽可能减少由于老年代碎片触发晋升失败、并发模式失败即可。
CMS Background GC由JVM的常驻线程定时扫描老年代的使用率,当使用率超过阈值时触发,该阈值由-XX:CMSInitiatingOccupancyFraction; -XX:+UseCMSInitiatingOccupancyOnly两个参数控制,不设置,默认首次为92%,后续会根据历史情况进行预测,动态调整。
如果我们固定阈值的大小,将该阈值设置为一个相对合理的值,既不使GC过于频繁,又可以降低晋升失败或并发模式失败的概率,就可以大大缓解毛刺产生的频率。
目标方案的堆分布如下:
Young区 1.5G
Old区 2.5G
Old区常驻对象 约400M
按经验数据,75%,80%是比较折中的,因此我们选择-XX:CMSInitiatingOccupancyFraction=75 -
XX:+UseCMSInitiatingOccupancyOnly进行灰度观察(我们也对80%的场景做了对照实验,75%优于80%)。
最终目标方案的配置为:
-Xms4096M -Xmx4096M -Xmn1536M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
如上配置,灰度 xx.xxx.60.6 一台机器;
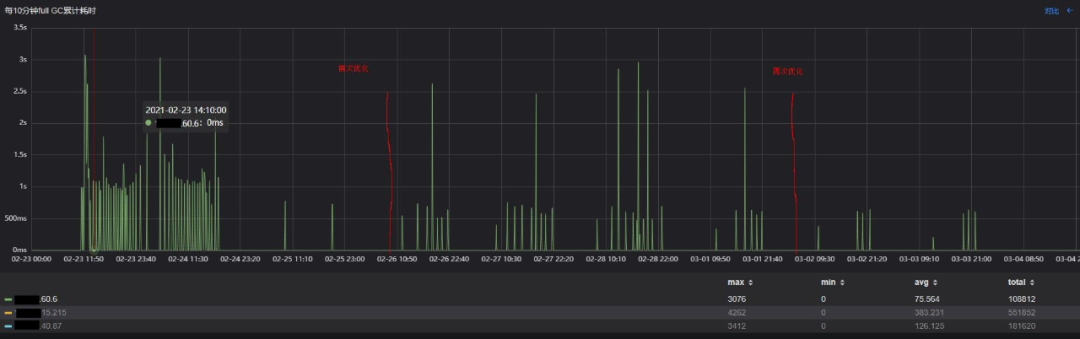
从再次优化的结果上看,CMS Foreground GC引起的毛刺基本消失,符合预期。
因此,视频服务最终目标方案的配置为;
-Xms4096M -Xmx4096M -Xmn1536M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSScavengeBeforeRemark
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
五、结果验收
灰度持续7天左右,覆盖工作日与周末,结果符合预期,因此符合在线上开启全量的条件,下面对全量后的结果进行评估。
Young GC次数
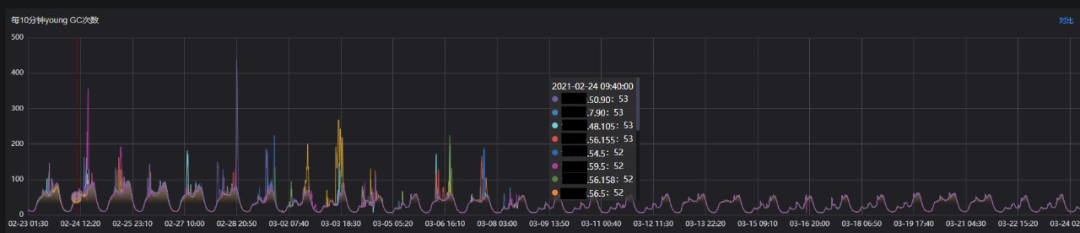
Young GC累计耗时
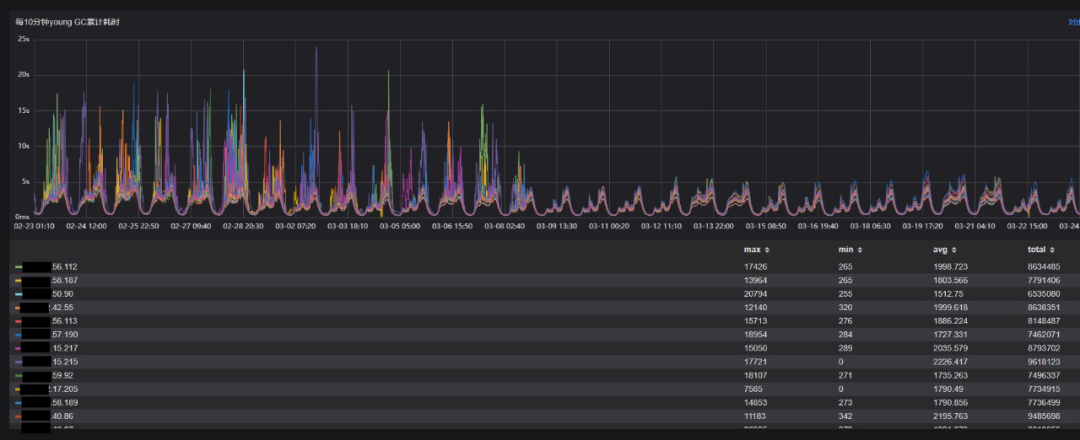
单次Young GC耗时
从Young GC指标上看,调整后Young GC次数平均减少30%,Young GC累积耗时平均减少17%,Young GC单次耗时平均增加约7ms,Young GC的表现符合预期。
除了技术手段,我们也在业务上做了一些优化,调优前实例的Young GC会出现明显的、不规律的(定时任务不一定分配到当前实例)毛刺,这里是业务上的一个定时任务,会加载大量数据,调优过程中将该任务进行分片,分摊到多个实例上,进而使Young GC更加平滑。
Full GC单次/累积耗时
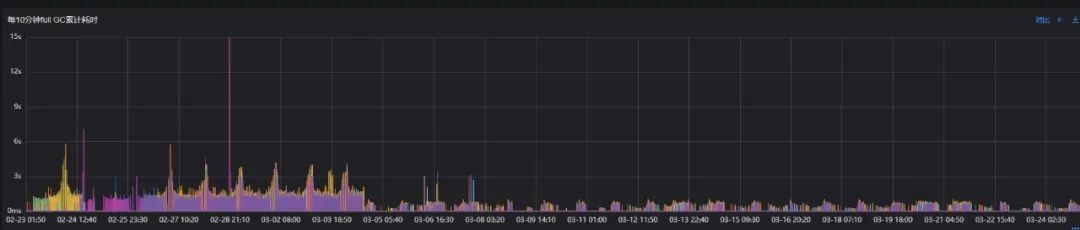
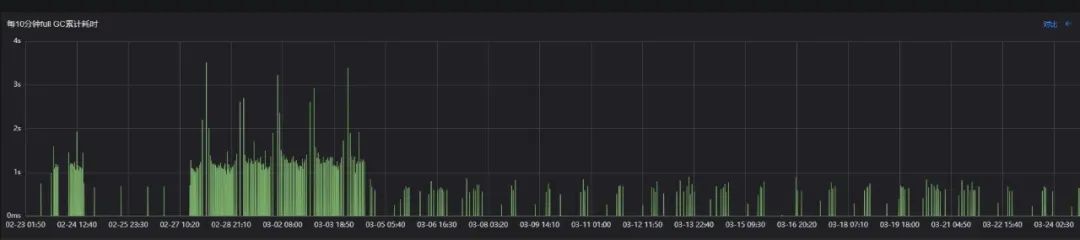
从"Full GC"的指标上看,"Full GC"的频率、停顿极大减少,可以说基本上没有真正意义上的Full GC了。
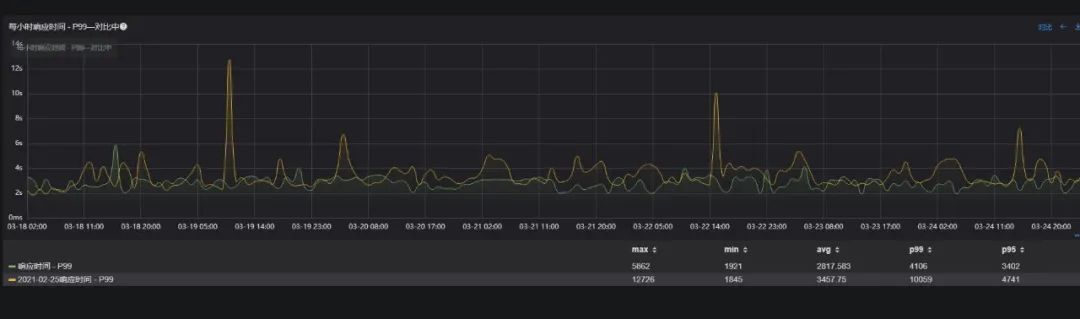
核心接口-A (下游依赖较多) P99响应时间,减少19%(从 3457 ms下降至 2817 ms);
核心接口-B (下游依赖中等) P99响应时间,减少41%(从 1647ms下降至 973ms);
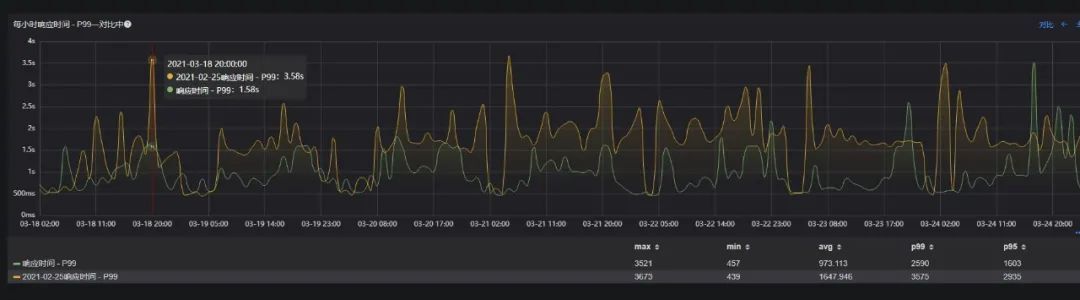
核心接口-C (下游依赖最少) P99响应时间,减少80%(从 628ms下降至 127ms);
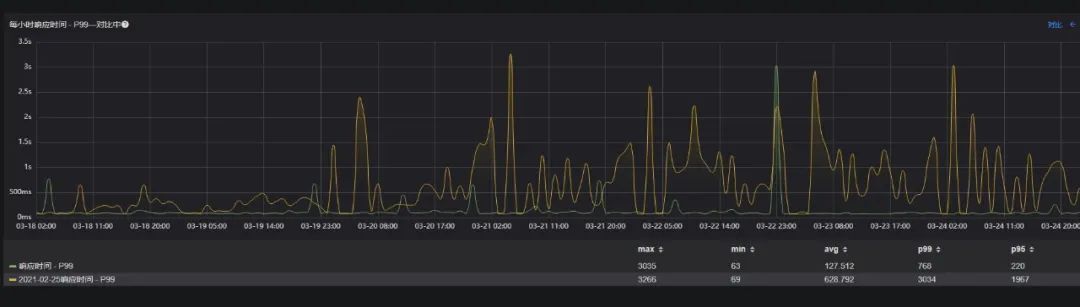
综合来看,整个结果是超出预期的。Young GC表现与设定的目标非常吻合,基本上没有真正意义上的Full GC,接口P99的优化效果取决于下游依赖的多少,依赖越少,效果越明显。
六、写在最后
由于GC算法复杂,影响GC性能的参数众多,并且具体参数的设置又取决于服务的特点,这些因素都很大程度增加了JVM调优的难度。
本文结合视频服务的调优经验,着重介绍调优的思路和落地过程,同时总结出一些通用的调优流程,希望能给大家提供一些参考。
作者:vivo互联网技术团队Li Guanyun、 Jessica Chen
高并发场景下JVM调优实践之路的更多相关文章
- 高并发场景下System.currentTimeMillis()的性能问题的优化 以及SnowFlakeIdWorker高性能ID生成器
package xxx; import java.sql.Timestamp; import java.util.concurrent.*; import java.util.concurrent.a ...
- 高并发场景下System.currentTimeMillis()的性能问题的优化
高并发场景下System.currentTimeMillis()的性能问题的优化 package cn.ucaner.alpaca.common.util.key; import java.sql.T ...
- C++高并发场景下读多写少的解决方案
C++高并发场景下读多写少的解决方案 概述 一谈到高并发的解决方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也 ...
- C++高并发场景下读多写少的优化方案
概述 一谈到高并发的优化方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读 ...
- Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%。再往后,每提高0.1%,优化难度成指数级增长了。哪怕是千分之一,也直接影响用户体验,影响每天上万张机票的销售额。 在高并发场景下,提供了保证线程安全的对象、方法。比如经典的ConcurrentHashMap,它比起HashMap,有更小粒度的锁,并发读写性能更好。线程安全的StringBuilder取代S
Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%.再往后,每提高0.1%,优化难度成指数级增长了.哪怕是千分之一,也直接影响用户体验,影响每天上万张机 ...
- 【转】记录PHP、MySQL在高并发场景下产生的一次事故
看了一篇网友日志,感觉工作中值得借鉴,原文如下: 事故描述 在一次项目中,上线了一新功能之后,陆陆续续的有客服向我们反应,有用户的个别道具数量高达42亿,但是当时一直没有到证据表示这是,确实存在,并且 ...
- HttpClient在高并发场景下的优化实战
在项目中使用HttpClient可能是很普遍,尤其在当下微服务大火形势下,如果服务之间是http调用就少不了跟http客户端找交道.由于项目用户规模不同以及应用场景不同,很多时候可能不需要特别处理也. ...
- 软件性能测试分析与调优实践之路-Web中间件的性能分析与调优总结
本文主要阐述软件性能测试中的一些调优思想和技术,节选自作者新书<软件性能测试分析与调优实践之路>部分章节归纳. 在国内互联网公司中,Web中间件用的最多的就是Apache和Nginx这两款 ...
- 软件性能测试分析与调优实践之路-Java应用程序的性能分析与调优-手稿节选
Java编程语言自从诞生起,就成为了一门非常流行的编程语言,覆盖了互联网.安卓应用.后端应用.大数据等很多技术领域,因此Java应用程序的性能分析和调优也是一门非常重要的课题.Java应用程序的性能直 ...
随机推荐
- Android实现自动登录和记住密码
效果图: 在勾选自动登录后下次打开软件会直接跳过登录界面 代码: protected void onCreate(Bundle savedInstanceState) { super.onCreate ...
- 让PHP能够调用C的函数-FFI扩展
在大型公司中,一般会有很我编程语言的配合.比如说让 Java 来做微服务层,用 C++ 来进行底层运算,用 PHP 来做中间层,最后使用 JS 展现效果.这些语言间的配合大部分都是通过 RPC 来完成 ...
- Centos6.8阿里云linux系统下配置LAMP运行环境-mysql5.6
1.Apache #安装apache软件 yum -y install httpd #启动httpd服务 service httpd start #设置开机启动chkconfig --list htt ...
- Java面向对象系列(4)- 类与对象的创建
类与对象的关系 类是一种抽象的数据类型,它是对某一类事物整体描述/定义,但是不能代表某一个具体的事物 动物.植物.手机-- Person类.Pet类.Car类等,这些类都是用来描述/定义某一类具体的事 ...
- Java面试总结 Boss沟通过:500+,面试:20,已投简历130+
1 概述 1 介绍 最近换工作,对最近面试的过程进行总结,总结每个公司的面试流程和问到的面试题,记录自己,也供大家参考. 我是一名Java开发,工作经验10年,所以面试一名高级Java开发工程师. 简 ...
- TI AM335x ARM Cortex-A8工业级核心板,工业网关、工业HMI等用户首选
创龙科技近期推出了ti AM335x ARM Cortex-A8工业级核心板,它拥有高性能.低功耗.低成本.接口丰富等优势,成为了工业网关.工业HMI等用户的首要选择.另外,核心板采用邮票孔连接方式, ...
- 用Fiddler抓不到https的包?因为你姿势不对!往这看!
前言 刚入行测试的小伙伴可能不知道,Fiddler默认抓http的包,如果要抓https的包,是需要装证书的!什么鬼证书?不明白的话继续往下看. Fiddler 抓取 https 数据 第一步:下载 ...
- Linux 清空日志的五种方法
VIM 是linux下一款优秀的编辑器,但是上手难度略大,网络上可以找到的教程很多,快捷键也非常多,一时很难记住. 本文换一种思路,就是根据平时自己的常用需要,去反查VIM如何操作的,再记录下来,这样 ...
- Dapr逐渐被点燃
Dapr被点燃 Dapr的热度个人认为才刚刚热起来,9月份我写了Dapr + .NET Core实战一共10篇,从基础概念到简单的实战,但是有很多人感兴趣,具体表现在我个人维护的QQ群,人数从80人左 ...
- Java(44)JDK新特性之函数式接口
作者:季沐测试笔记 原文地址:https://www.cnblogs.com/testero/p/15201667.html 博客主页:https://www.cnblogs.com/testero ...