pipeline 结构设计
一.pipeline步骤
当团队开始设计第一个pipeline时,该如何下手呢?以下是笔者的设计步骤,仅供参考。
第1步:了解网站的整体架构。这个过程就是了解系统是如何服务用户的。其间,还可以识别出哪些是关键系统。
第2步:找到服务之间、服务与组件之间、组件之间的依赖关系。第3步:找到对外依赖最少的组件,将其构建、打包、制品管理自动化。
第4步:重复第3步,直到所有(不是绝对)的组件都使用制品库管理起来。
第5步:了解当前架构中所有的服务是如何从源码到最终部署上线的。
第6步:找出第一个相对不那么重要的服务,将在第5步中了解到的手动操作自动化。但是,通常不会直接照搬手动操作进行自动化,而是会进行一些改动,让pipeline更符合《持续交付》第5章中所介绍的“部署流水线相关实践”内容。
另外,之所以先从一个不那么重要的服务下手,是因为即使自动化脚本出现错误,也不至于让大家对自动化失去信心。这个过程也是让团队适应自动化的过程。
第7步:重复第6步,直到所有服务的所有阶段都自动化。这一步不是绝对的,也可以先自动化一部分服务,然后开始第8步。
第8步:加入自动化集成测试的阶段。
在现实项目中,远没有这么简单。而且,整个过程并不一定是顺序进行的,而是需要几个来回。
如果当前服务没有日志收集和监控,那么在第3步时就要开始准备了,免得后期返工。在第8步以后就要看团队的具体需求了。
二.案例
假设存在一个X网站,我们需要使用上一节介绍的步骤来设计其pipeline。
通过与X网站的团队进行沟通(通常不止一次沟通),总结出它的(不是严格意义的)架构
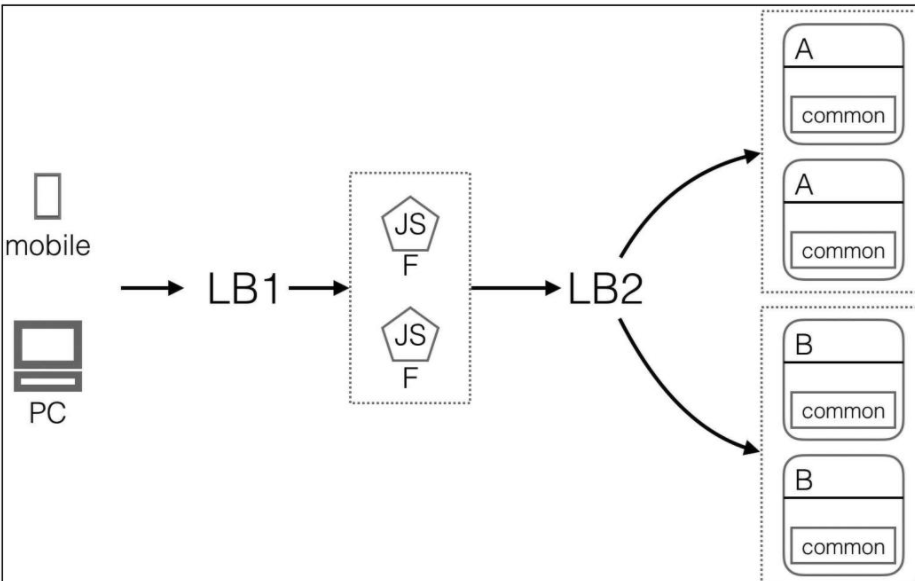
A和B都是后端服务,它们共同依赖于common组件。F是一个Node.js服务。LB1和LB2分别负责前端的负载和后端的负载。
现在我们已经完成第1、2步。
第3步,很容易就能找出依赖最少的组件:common。它的pipeline非常简单,只需要编译打包并上传到制品库即可。读者参考第2、3章就可以独立完成。
第4步,省略。
第5步,A服务承载的业务相对不那么重要,我们就从它开始。那么,之前A服务是怎么从源代码到最终部署上线的,笔者了解到×网站的成员都是自己打包自己所负责的服务的,然后把制品以邮件的方式发给运维人员,运维人员再把制品复制到目标服务器,然后逐台机器更新服务。
第6步,开始设计A服务的pipeline。这个过程不是一次就能做到相对完善的,而是需要多次迭代调整才能实现。我们跳过这个演进过程,为A服务设置了以下几个阶段

A服务的Jenkinsfile内容如下:
//引入zpipelinelib共享库
@Library('zpipelinelib@master') _
pipeline {
agent any
tools{ amven 'maven-3.5.2' }
parameters {
string(name: 'DEPLOY_ENV', defaultValue: 'staging', description: '')
}
environment{
_service_name = 'a-service'
、、zGetVersion方法用于生成版本号
_version = zGetVersion("${BUILD_NUMBER}", "${env.GIT_COMMIT}")
//配置的版本
_dev_config_version = 'latest'
_staging_config_version = 'abcd'
_prod_config_version = 'cdefg'
}
triggers{
gitlab(triggerOnPush:true, triggerOnMergeRequest:true, branchFilterType:'all', secretToken:"abcef")
}
stages {
//因为编译完成后,通常制品就在编译的那个Jenkins agent上
//编译打包和上传制品,放在一个阶段就可以了
stage("构建"){
steps {
zMvn("${_version}")
zCodeAnalysis("${_version}")
zUploadArtifactory("${_version}","${_service_name}")
}
post {
//这时失败了,只发送消息给导致失败的相关人员
// currentBuild变量代表当前的构建,是pipeline中的内置变量
failure { zNotify( "${_service_name}", "${_version}", ['culprits'], currentBuild)}
}
}
stage("发布到开发环境"){
steps{
zDeployService("${__service_name}", "${__version}", "${__dev_config_version}", 'dev')
input message: "开发环境部署完成,是否发布到预发布环境?"
}
post {
failure { zNotify( "${__service_name}", "${__version}", ['culprits'], currentBuild)}
}
}
stage("发布到预发布环境"){
when { branch 'release-*'}
steps{
zDeployService("${__service_name}", "${__version}", "${__staging_config_version}", 'staging')
}
post {
//发布消息给团队中所有的人
always { zNotify( "${__service_name}", "${__version}", ['team'], currentBuild)}
}
}
stage("自动化集成测试"){
when { branch 'release-*' }
steps{ zSitTest('staging') }
post {
always { zNotify( "${__service_name}", "${__version}", ['team'], currentBuild)}
}
}
stage("手动测试"){
when { branch 'release-*' }
steps{ input message:"手动测试是否通过? " }
post {
failure { zNotify( "${__service_name}", "${__version}", ['team'], currentBuild)}
}
}
stage("发布到生产环境")
when { branch 'release-*' }
steps{
script{
def approvalMap = zInputDeployProdPassword()
withCredentials(
[string(currentBuild:'secretText', variable:'varName')]) {
if("${approvalMap['deployPassword']}" == "$${varName}"){
zDeployService("${__service_name}",
"${__version}",
"${_prod_config_version}", 'prod')
} //end if
} //end withCredentials
}
}
post {
always { zNotify( "${__service_name}", "${__version}", ['team'], currentBuild)}
}
stage("生产环境自检"){
when { branch 'release-*' }
steps{ zVerify('prod') }
post {
always { zNotfiy( "${__service_name}". "${__version}". ['team'], currentBuild) }
}
}
} //stages
post {
always { cleanWs() }
}
} //pipeline
pipeline详解
在×网站pipeline 中,凡是以“z”字母开头的步骤都是zpipelinelib共享库提供的步骤,如zMvn、zCodeAnalysis。换句话说,我们将pipeline的具体操作隐藏在zpipelinelib共享库中。这就像在编程语言中接口与具体实现类的关系。pipeline只负责调用接口,表达意图;共享库则负责实现接口。为什么这样做呢?有以下几个理由。
- pipeline的设计者可以更关注设计。
- pipeline的各阶段意图更清晰。
- 可维护性更好。只需要修改zpipelinelib共享库,所有引用了该共享库的pipeline都会被修改。
只生成一次制品
只生成一次制品,这是《持续交付》中提到的一个非常重要的实践。
在environment指令中,我们使用zGetVersion步骤获得版本号并赋值给变量_version。在构建阶段,我们使用_version的值生成制品,并上传到制品库。之后所有的阶段,都使用此版本号从制品库中获取制品。
不同环境部署
对不同环境采用同一种部署方式,这也是《持续交付》中提到的另一个非常重要的实践。
X网站有三个环境:开发环境( dev)、预发布环境( staging )和生产环境( prod )。对于这三个环境,我们都使用同一个步骤完成——zDeployService。zDeployService步骤的关键参数是版本号及目标部署环境。
实现这一步并不简单,因为要实现将同一制品部署到不同的环境,就必须做到制品与配置的分离。本例中A服务是基于Springboot框架实现的,配置使用了Springboot的Profiles特性,代码结构如下∶
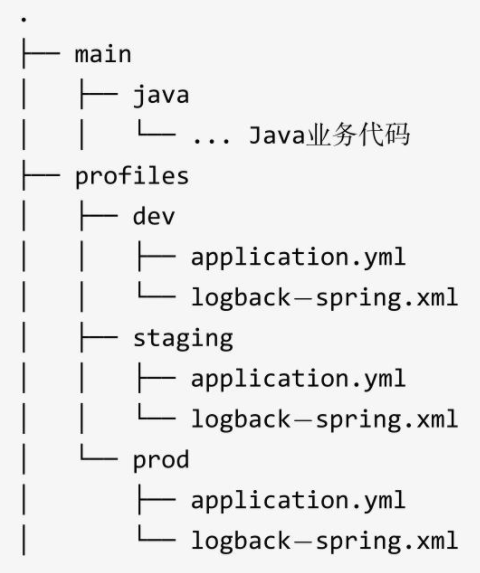
那怎么分离呢?其实,制品与配置分离不是最终目的,最终目的是将配置项与配置值分离。部署脚本只存放配置项,配置值应该由类似于配置中心的地方提供。比如在部署脚本中,配置文件application.yml只存储配置项。
thread.pool.num={{a.service.threadPoolNum}}
在配置中心中,配置值以缓解维度进行区分,比如在开发环境下:
a.serverice.threadPoolNum:64
而在预发布环境下,该配置值又变成了:
a.serverice.threadPoolNum:128
实现配置项与配置值分离后,不同环境使用同一种部署方式就完成80%了。
配置也是需要版本化的。environment指令中的三个__**config version变量用于指定不同环境的配置的版本
系统集成测试
虽然A服务的单元测试覆盖率达到了100%,但是这也不能代表A服务与其他系统集成后,整个环境是可以正常工作的。因此,还要进行集成测试。
也就是说,在部署A服务完成后执行集成测试。在A服务的pipeline,zSitTest步骤的左右,它会触发集成测试pipeline。
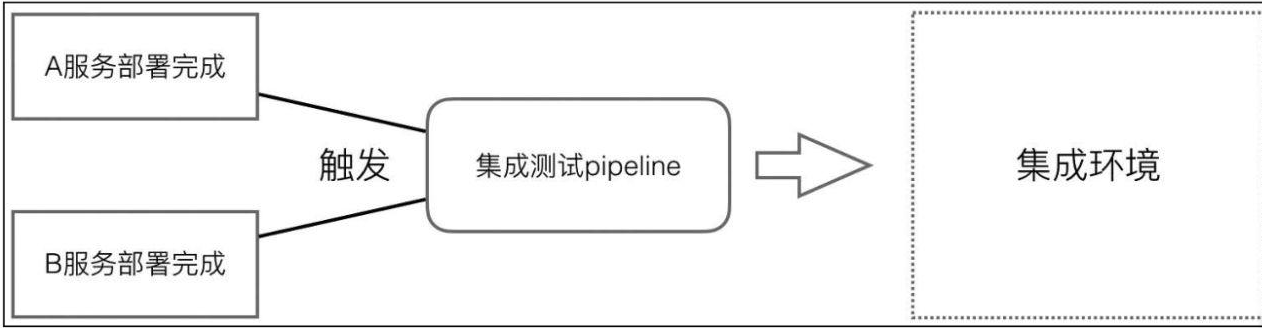
集成测试pipeline通常是一个独立的代码仓库。
指定版本部署
可以看出,目前A服务是无法指定版本部署的,pipeline执行的代码始终是代码仓库中最新版本的代码。
我们可以在A服务的pipeline中加入入参参数,用于指定部署版本。然后再pipeline中加入判断,当有指定版本参数传入时,就跳过构建阶段,而在其他阶段使用指定版本的制品。
pipeline的设计还与代码的分支管理策略有关。由于X网站上线频繁,所以采用主干开发、发布分支的策略。在发布到开发环境后的所有阶段都只对release-*分支有效。
pipeline 结构设计的更多相关文章
- Netty 对通讯协议结构设计的启发和总结
Netty 通讯协议结构设计的总结 key words: 通信,协议,结构设计,netty,解码器,LengthFieldBasedFrameDecoder 原创 包含与机器/设备的通讯协议结构的设计 ...
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...
- Building the Testing Pipeline
This essay is a part of my knowledge sharing session slides which are shared for development and qua ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- 数据库表结构设计方法及原则(li)
数据库设计的三大范式:为了建立冗余较小.结构合理的数据库,设计数据库时必须遵循一定的规则.在关系型数据库中这种规则就称为范式.范式是符合某一种设计要求的总结.要想设计一个结构合理的关系型数据库,必须满 ...
- 图解Netty之Pipeline、channel、Context之间的数据流向。
声明:本文为原创博文,禁止转载. 以下所绘制图形均基于Netty4.0.28版本. 一.connect(outbound类型事件) 当用户调用channel的connect时,会发起一个 ...
- 初识pipeline
1.pipeline的产生 从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面 ...
- 分布式数据库的四分结构设计 BCDE
首先,对关系型数据库的表进行四种分类定义: Basis 根基,Content 内容, Description 说明, Extension 扩展. Basis:Baisis 表是唯一的,为了实现标准而得 ...
- MongoDB 聚合管道(Aggregation Pipeline)
管道概念 POSIX多线程的使用方式中, 有一种很重要的方式-----流水线(亦称为"管道")方式,"数据元素"流串行地被一组线程按顺序执行.它的使用架构可参考 ...
随机推荐
- 大爽Python入门教程 1-1 简单的数学运算
大爽Python入门公开课教案 点击查看教程总目录 1 使用pycharm建立我们的第一个项目 打开pycharm,点击菜单栏,File->New Project 在Location(项目地址) ...
- java中static关键字的解析
静态的特点: A:随着类的加载而加载 B:优先于对象而存在 C:静态是被所有对象共享的数据 这也是我们来判断是否使用静态的标准 D:静态的出现,让我们的调用方式多了一种 类名.静态的内容 非静态的内容 ...
- [cf1486F]Pairs of Paths
以1为根建树,先将所有路径挂在lca上,再分两类讨论: 1.lca相同,此时我们仅关心于lca上不经过第$a$和$b$个儿子路径数,容斥一下,即所有路径-经过$a$的-经过$b$的+经过$a$和$b$ ...
- 二、JAVA API实现HDFS
目录 前文 hdfsdemo通过HDFS上传下载文件 windows环境下需要使用uitls.exe 为pom.xml增加依赖 新建java文件HDFS_CRUD GitHub下载地址 前文 一.Ce ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- 解决:ElasticsearchException[X-Pack is not supported and Machine Learning is not available for
解决:在config/elasticsearch.yml添加一条配置: xpack.ml.enabled: false 能启动了就. 在docker安装出现这个问题,目前还没解决. 算了用win10得 ...
- vue-if和show
<template> <div> <div v-if="flag">今晚要上课</div> <div v-else> 今 ...
- C/C++转义字符表
转义字符 意义 ASCII码值(十进制) \a 响铃(BEL) 007 \b 退格(BS) ,将当前位置移到前一列 008 \f 换页(FF),将当前位置移到下页开头 012 \n 换行(LF) ,将 ...
- 统计学习3:线性支持向量机(Pytorch实现)
学习策略 软间隔最大化 上一章我们所定义的"线性可分支持向量机"要求训练数据是线性可分的.然而在实际中,训练数据往往包括异常值(outlier),故而常是线性不可分的.这就要求我们 ...
- CF1444C Team-Building
考虑我们判定二分图染色的经典算法: 染色. 我们把所有不同颜色块之间的边都保存下来. 只在图中保留相同颜块之间的边,并对其染色. 我们考虑记\(g_i\)为一个点的所在联通块编号,\(f_i\)为他在 ...