统计学习:线性支持向量机(SVM)
学习策略
软间隔最大化
上一章我们所定义的“线性可分支持向量机”要求训练数据是线性可分的。然而在实际中,训练数据往往包括异常值(outlier),故而常是线性不可分的。这就要求我们要对上一章的算法做出一定的修改,即放宽条件,将原始的硬间隔最大化转换为软间隔最大化。
给定训练集
D = \{\{\bm{x}^{(1)}, y^{(1)}\}, \{\bm{x}^{(2)}, y^{(2)}\},..., \{\bm{x}^{(m)}, y^{(m)}\}\}
\end{aligned}\tag{1}
\]
其中\(\bm{x}^{(i)} \in \mathcal{X} \subseteq \mathbb{R}^n\),\(y^{(i)} \in \mathcal{Y} = \{+1, -1\}\)。
如果训练集是线性可分的,则线性可分支持向量机等价于求解以下凸优化问题:
\underset{\bm{w}, b}{\max} \quad \frac{1}{2} || \bm{w}||^2\\
\text{s.t.} \quad y^{(i)} (\bm{w}^T \bm{x}^{(i)} + b) \geqslant 1 \\
\quad (i = 1, 2, ..., m)
\end{aligned} \tag{2}
\]
其中\(y^{(i)} (\bm{w}^T \bm{x}^{(i)} + b) -1 \geq 0\)表示样本点\((\bm{x}^{(i)}, y^{(i)})\)满足函数间隔大于等于1。现在我们对每个样本点\((\bm{x}^{(i)}, y^{(i)})\)放宽条件,引入一个松弛变量\(\xi_{i} \geqslant 0\),使约束条件变为\(y^{(i)} (\bm{w}^T \bm{x}^{(i)} + b) \geq 1-\xi_{i}\)。并对每个松弛变量进行一个大小为\(\xi_{i}\)的代价惩罚,目标函数转变为:\(\frac{1}{2} || \bm{w}||^2+C\sum_{i=1}^{m}\xi_{i}\),此处\(C>0\)称为惩罚系数。此时优化函数即要使间隔尽量大(使\(\frac{1}{2} || \bm{w}||^2\)尽量小),又要使误分类点个数尽量少。这称之为软间隔化。
线性支持向量机
就这样,线性支持向量机变为如下凸二次规划问题(原始问题):
\underset{\bm{w}, b}{\max} \quad \frac{1}{2} || \bm{w}||^2 + C\sum_{i=1}^{m}\xi_{i}\\
\text{s.t.} \quad y^{(i)} (\bm{w}^T \bm{x}^{(i)} + b) \geqslant 1-\xi_{i} \\
\xi_{i} \geqslant 0 \\
\quad (i = 1, 2, ..., m)
\end{aligned} \tag{3}
\]
因为是凸二次规划,因此关于\((\bm{w}, b, \bm{\xi})\)的解一定存在,可以证明\(\bm{w}\)的解唯一,但\(b\)的解可能不唯一,而是存在于一个区间。
设\((2)\)的解为\(\bm{w}^{*}, b^*\),这样可得到分离超平面\(\{\bm{x} | \bm{w}^{*T}\bm{x}+b=0\}\)和分类决策函数\(f(\bm{x})=\text{sign}(\bm{w}^{*T}\bm{x}+b^*)\)
算法
常规的带约束优化算法
和上一章一样,我们将原始问题\((2)\)转换为对偶问题进行求解,原始问题的对偶问题如下(推导和上一章一样):
\underset{\bm{\alpha}}{\max} -\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy^{(i)}y^{(j)}\langle \bm{x}^{(i)}, \bm{x}^{(j)}\rangle + \sum_{i=1}^{m}\alpha_i \\
s.t. \sum_{i=1}^{m}\alpha_iy^{(i)} = 0 \\
C - \alpha_i - \mu_i = 0\\
\alpha_i \geq 0 \\
\mu_i \geq 0 \\
i=1, 2,...,m
\end{aligned}
\tag{4}
\]
接下来我们消去\(\mu_i\),只留下\(\alpha_i\),将约束条件转换为:\(0 \leqslant \alpha_i \leqslant C\) ,并对目标函数求极大转换为求极小,这样对\((4)\)进行进一步变换得到:
\underset{\bm{\alpha}}{\max} -\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy^{(i)}y^{(j)}\langle \bm{x}^{(i)}, \bm{x}^{(j)}\rangle + \sum_{i=1}^{m}\alpha_i \\
s.t. \sum_{i=1}^{m}\alpha_iy^{(i)} = 0 \\
0 \leqslant \alpha_i \leqslant C \\
i=1, 2,...,m
\end{aligned}
\tag{5}
\]
这就是原始优化问题\((3)\)的对偶形式。
这样,我们得到对偶问题的解为\(\bm{\alpha}^*=(\alpha_1^*, \alpha_2^*, ..., \alpha_m^*)^T\)。
此时情况要比完全线性可分时要复杂,比如正例不再仅仅分布于软间隔平面上和正例那一侧,还可能分布于负例对应的那一侧(由于误分);对于负例亦然。如下图所示:
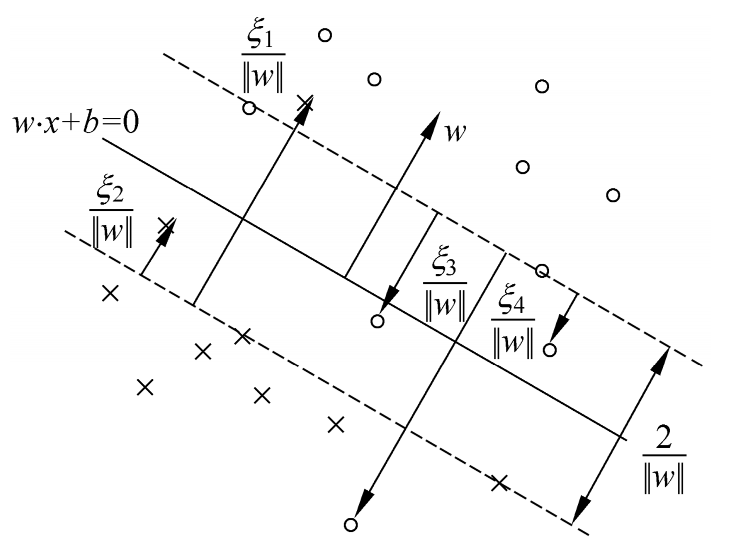
图中实线为超平面,虚线为间隔边界,“\(\circ\)”为正例点,“\(\times\)”为负例点,\(\frac{\xi_i}{||\bm{w}||}\)为实例\(\bm{x}^{(i)}\)到间隔边界的距离。
此时类比上一章,我们将\(\alpha_i^* > 0\)(注意,不要求一定有\(\alpha_i^*<C\))对应样本点\((\bm{x}^{(i)}, y^{(i)})\)的实例\(\bm{x}^{(i)}\)称为支持向量(软间隔支持向量)。它的分布比硬间隔情况下要复杂得多:可以在间隔边界上,也可以在间隔边界和分离超平面之间,甚至可以在间隔超平面误分类的一侧。若\(0<\alpha_i^*<C\),则\(\xi_i =0\),支持向量恰好落在间隔边界上;若\(\alpha_i = C, 0<\xi_i<1\),则分类正确且\(\bm{x}^{(i)}\)在间隔边界和分离超平面之间;若\(\alpha_i^*=C, \xi_i=1\),则\(\bm{x}^i\)在分离超平面上;若\(\alpha_i^*=C, \xi_i>1\)则分类错误,\(\bm{x}^{(i)}\)分离超平面误分类的那一侧。
接下来我们需要将对偶问题的解转换为原始问题的解。
对于对偶问题的解\(\bm{\alpha}^*=(\alpha_1^*, \alpha_2^*, ..., \alpha_m^*)^T\),若存在\(\alpha^*\)的一个分量\(0 <\alpha_s^* < C\),则原始问题的解\(w^*\)和\(b^*\)可以按下式求得:
\bm{w}^{*} = \sum_{i=1}^{m}\alpha_i^{*}y^{(i)}\bm{x}^{(i)} \\
b^{*} = y^{(s)} - \sum_{i=1}^{m}\alpha_i^*y^{(i)}\langle \bm{x}^{(s)}, \bm{x}^{(i)} \rangle
\end{aligned}
\tag{6}
\]
式 \((11)\) 的推导方法和上一章类似,由原始问题(凸二次规划问题)的解满足KKT条件导出。
这样,我们就可以得到分离超平面如下:
\tag{7}
\]
分类决策函数如下:
\tag{8}
\]
(同样地,之所以写成\(\langle \bm{x}^{(i)}, \bm{x} \rangle\)的内积形式是为了方便我们后面引入核函数)
综上,按照式\((3)\)的策略求解线性可分支持向量机的算法如下:

可以看到在算法的步骤\((2)\)中,是对随机采的一个\(\alpha_s^*\)计算出\(b^*\),故按照式\((3)\)的策略(原始问题)求解出的\(b\)可能不唯一。
基于合页损失函数的的无约束优化算法
其实,问题\((3)\)还可以写成无约束优化的形式,目标函数如下:
\tag{9}
\]
式\((8)\)的第一项为经验风险或经验损失(加上正则项整体作为结构风险)。函数
\tag{10}
\]
称为合页损失函数(hinge loss function)。s
合页损失函数意味着:如果样本\((\bm{x}^{(i)}, y^{(i)})\)被正确分类且函数间隔(确信度)大于1(即\(y^{(i)}(\bm{w}^{T}\bm{x}^{(i)} + b)>0\)),则损失是0,否则损失是\(1-y^{(i)}(\bm{w}^{T}\bm{x}^{(i)} + b)\)。像上面提到的分类图中,\(\bm{x}^{(4)}\)被正确分类,但函数间隔不大于1,损失不是0。
0-1损失函数、合页损失函数、感知机损失函数归纳如下:
0-1损失函数:\quad \quad \text{I}(y(\bm{w}^{T}\bm{x}+b)<0) \\
合页损失函数:\quad \quad\max(0, 1-y(\bm{w}^{T}\bm{x} + b)) \\
感知机损失函数:\quad \quad\max(0, -y(\bm{w}^{T}\bm{x} + b))
\end{aligned}
\tag{11}
\]
这三个函数的图像对比如下图所示:
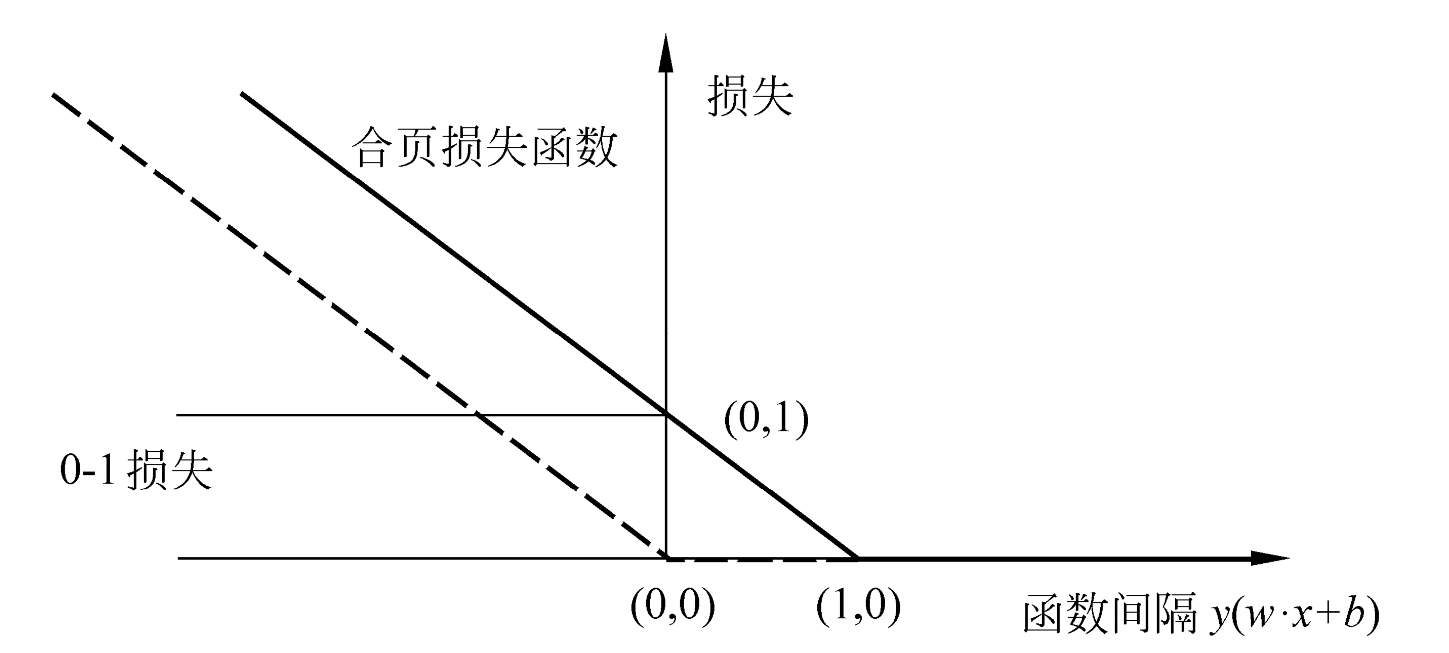
可以看到合页损失函数形似合页,故而得名。而0-1损失函数虽然是二分类问题真正的损失函数,但它不是连续可导的,对其进行优化是NP困难的,所以我们转而优化其上界(合页损失函数)构成的目标函数,这时上界损失函数又称为代理损失函数(surrogate loss function)。而对于感知机损失函数,直观理解为:当\((\bm{x}^{(i)}, y^{(i)})\)被正确分类时,损失是0,否则是\(-y(\bm{w}^{T}\bm{x} + b)\)。相比之下,合页损失函数不仅要求要正确分类,而且要确信度足够大时损失才是0,也就是说合页损失函数对学习效果有更高的要求。
合页损失函数处处连续,此时可以采用基于梯度的数值优化算法求解(梯度下降法、牛顿法等),在此不再赘述。不过,此时的目标函数非凸,不一定保证收敛到最优解。
算法
上一章我们尝试过在不借助SMO算法的情况下求解问题\((3)\)这一凸二次规划问题,结果发现收敛速度过慢。现在我们试试采用基于合页损失函数的梯度下降算法来直接求解参数\(\bm{w}\)和\(b\)。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from scipy.optimize import minimize
import numpy as np
import math
from copy import deepcopy
import torch
from random import choice
# 数据预处理
def preprocess(X, y):
# 对X进行min max标准化
for i in range(X.shape[1]):
field = X[:, i]
X[:, i] = (field - field.min()) / (field.max() - field.min())
# 标签统一转化为1和-1
y = np.where(y==1, y, -1)
return X, y
class SVM():
def __init__(self, lamb=0.01, input_dim=256):
self.lamb = lamb
self.w, self.b = np.random.rand(
input_dim), 0.0
# 注意一个批量的loss可并行化计算
def objective_func(self, X, y):
loss_vec = torch.mul(y, torch.matmul(X, self.w) + self.b)
loss_vec = torch.where(loss_vec > 0, loss_vec, 0.)
return 1/self.m * loss_vec.sum() + self.lamb * torch.norm(self.w)**2
def train_data_loader(self, X_train, y_train):
# 每轮迭代随机采一个batch
data = np.concatenate((X_train, y_train.reshape(-1, 1)), axis=1)
np.random.shuffle(data)
X_train, y_train = data[:, :-1], data[:, -1]
for ep in range(self.epoch):
for bz in range(math.ceil(self.m/self.batch_size)):
start = bz * self.batch_size
yield (
torch.tensor(X_train[start: start+self.batch_size], dtype=torch.float64),
torch.tensor(y_train[start: start+self.batch_size],dtype=torch.float64))
def test_data_loader(self, X_test):
# 每轮迭代随机采一个batch
for bz in range(math.ceil(self.m_t/self.test_batch_size)):
start = bz * self.test_batch_size
yield X_test[start: start+self.test_batch_size]
def compile(self, **kwargs):
self.batch_size = kwargs['batch_size']
self.test_batch_size = kwargs['test_batch_size']
self.eta = kwargs['eta'] # 学习率
self.epoch = kwargs['epoch'] # 遍历多少次训练集
def sgd(self, params):
with torch.no_grad():
for param in params:
param -= self.eta*param.grad
param.grad.zero_()
def fit(self, X_train, y_train):
self.m = X_train.shape[0] #样本个数
# 主义w初始化为随机数,不能初始化为0
self.w, self.b = torch.tensor(
self.w, dtype=torch.float64, requires_grad=True), torch.tensor(self.b, requires_grad=True)
for X, y in self.train_data_loader(X_train, y_train):
loss_v = self.objective_func(X, y)
loss_v.backward()
# b有梯度,w没有梯度?
self.sgd([self.w, self.b])
# print(self.w, self.b)
self.w = self.w.detach().numpy()
self.b = self.b.detach().numpy()
def pred(self, X_test):
# 遍历测试集中的每一个样本
self.m_t = X_test.shape[0]
pred_list = []
for x in self.test_data_loader(X_test):
pred_list.append(np.sign(np.matmul(x, self.w) + self.b))
return np.concatenate(pred_list, axis=0)
if __name__ == "__main__":
X, y = load_breast_cancer(return_X_y=True)
X, y = preprocess(X, y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
clf = SVM(lamb=0.01, input_dim=X_train.shape[1])
clf.compile(batch_size=256, test_batch_size=1024, eta=0.001, epoch=1000) #定义训练参数
clf.fit(X_train, y_train)
y_pred = clf.pred(X_test)
acc_score = accuracy_score(y_test, y_pred)
print("The accuracy is: %.1f" % acc_score)
可以看到,效果不太好,哈哈,目前还在debug
The accuracy is: 0.6
统计学习:线性支持向量机(SVM)的更多相关文章
- coursera机器学习-支持向量机SVM
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 复习支持向量机(SVM)没空看书时,掌握下面的知识就够了
支持向量机(support vector machines, SVM)是一种二类分类模型.它的基本模型是定义在特征空间上的间隔最大的线性分类器:支持向量机还包括核技巧,这使它成为实质上的非线性分类器. ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- 统计学习3:线性支持向量机(Pytorch实现)
学习策略 软间隔最大化 上一章我们所定义的"线性可分支持向量机"要求训练数据是线性可分的.然而在实际中,训练数据往往包括异常值(outlier),故而常是线性不可分的.这就要求我们 ...
- 文本分类学习 (七)支持向量机SVM 的前奏 结构风险最小化和VC维度理论
前言: 经历过文本的特征提取,使用LibSvm工具包进行了测试,Svm算法的效果还是很好的.于是开始逐一的去了解SVM的原理. SVM 是在建立在结构风险最小化和VC维理论的基础上.所以这篇只介绍关于 ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
- 线性可分支持向量机--SVM(1)
线性可分支持向量机--SVM (1) 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 线性可分支持向量机的定义: ...
- 支持向量机SVM——专治线性不可分
SVM原理 线性可分与线性不可分 线性可分 线性不可分-------[无论用哪条直线都无法将女生情绪正确分类] SVM的核函数可以帮助我们: 假设‘开心’是轻飘飘的,“不开心”是沉重的 将三维视图还原 ...
- OpenCV支持向量机SVM对线性不可分数据的处理
支持向量机对线性不可分数据的处理 目标 本文档尝试解答如下问题: 在训练数据线性不可分时,如何定义此情形下支持向量机的最优化问题. 如何设置 CvSVMParams 中的参数来解决此类问题. 动机 为 ...
随机推荐
- linux 常用命令(五)——(centos7-centos6.8)JDK安装
1.安装jdk前先检测系统是否带有OpenJDK:若存在则删除 查看: java -version 查询出OpenJDK相关的文件:rpm -qa | grep java 删除OpenJDK相关的文件 ...
- 战胜了所有对手,却输给了时代。MVVM--jQuery永远的痛。
前言 第二次浏览器战争中,随着以 Firefox 和 Opera 为首的 W3C 阵营与 IE 对抗程度的加剧,浏览器碎片化问题越来越严重,不同的浏览器执行不同的标准,对于开发人员来说这是一个恶梦.为 ...
- React事件处理、收集表单数据、高阶函数
3.React事件处理.收集表单数据.高阶函数 3.1事件处理 class Demo extends React.Component { /* 1. 通过onXxx属性指定事件处理函数(注意大小写) ...
- 开源的 Web 框架哪个快?我在 GitHub 找到了答案
在开源这片自由的土地上,孕育了太多开源 Web 框架.我在 GitHub 上搜了一下"web framework"关键字显示有 56000+ 匹配的开源项目,它们百花齐放各有特色, ...
- Linux下sed找出IP中第四位
ip addr|sed -n '9p'|egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'|sed -nr 's#^.*inet (.*) b ...
- 基于Vue+Vuex+Vue-Router+axios+mint-ui的移动端电商项目
第一步:安装Node 1.打开NodeJS的官网,下载和自己系统相配的NodeJS的安装程序,包括32位还是64位一定要选择好,否则会出现安装问题. 下载地址:https://nodejs.org/e ...
- 性能测试必备命令(3)- lscpu
性能测试必备的 Linux 命令系列,可以看下面链接的文章哦 https://www.cnblogs.com/poloyy/category/1819490.html 介绍 显示有关CPU架构的信息 ...
- web安全性测试——XSS跨站攻击
1.跨站攻击含义 XSS:(Cross-site scripting)全称"跨站脚本",是注入攻击的一种.其特点是不对服务器端造成任何伤害,而是通过一些正常的站内交互途径,例如发布 ...
- CSS004. 自定义滚动条样式(webkit)
CSS /* 滚动条宽度 */ ::-webkit-scrollbar { width: 6px; } /* 轨道样式 */ ::-webkit-scrollbar-track { backgroun ...
- linux 下 I/O 多路复用初探
本文内容整理自B站up主 free-coder 发布的视频:[并发]IO多路复用select/poll/epoll介绍 引入 一般来讲,服务器在处理IO请求(一般指的是socket编程)时,需要对so ...