沟谷网络的提取及沟壑密度的计算(ArcPy实现)
一、背景
沟壑密度是描述地面被水道切割破碎程度的一个指标。沟壑密度是气候、地形、岩性、植被等因素综合影响的反映。沟壑密度越大,地面越破碎,平均坡度增大,地表物质稳定性降低,且易形成地表径流,土壤侵蚀加剧。因此,沟壑密度的测定,对于了解区域地形发育特征,水土流失监测、水土保持规划有着重要的意义。
沟壑密度也称沟谷密度或沟道密度,指单位面积内沟壑的总长度。以公里/平方公里为单位。数学表达为

Ds为沟壑密度﹔>L为研究区域内的沟壑总长度(单位:公里);A为特定研究区域的面积(单位:平方公里)。
二、目的
掌握利用水文分析工具提取沟谷网络的原理及方法。
三、要求
(1)利用水文分析工具提取研究区域的沟谷网络。
(2)计算出该研究区域的沟壑密度。
四、数据
25m分辨率的DEM数据,区域面积约有59km²(\ChP11 \Ex3)。
五、模型构建器

六、ArcPy实现
# -*- coding: utf-8 -*-
# ---------------------------------------------------------------------------
# 11-3 沟谷网络的提取及沟壑密度的计算.py
# Created on: 2021-10-12 09:38:51.00000
# (generated by ArcGIS/ModelBuilder)
# Description:
# ---------------------------------------------------------------------------
# Import arcpy module
import arcpy
from arcpy.sa import Test
import os
import shutil
import time
print time.asctime()
path = raw_input("请输入数据所在文件夹的绝对路径:").decode("utf-8")
# 开始计时
time_start = time.time()
paths = path + "\\result"
if not os.path.exists(paths):
os.mkdir(paths)
else:
shutil.rmtree(paths)
os.mkdir(paths)
# Local variables:
dem = path + "\\dem"
Output_descent_rate_raster_data1 = "Descent_data1"
FlowDir = "FlowDir"
Sink = "Sink"
Fill_dem = "Fill_dem"
Output_descent_rate_raster_data2 = "Descent_data2"
COLUMNCOUNT = "696"
ROWCOUNT = "622"
CELLSIZEX = "25"
CELLSIZEY = "25"
FlowDir_Fill = "FlowDir_Fill"
FlowAcc = "FlowAcc"
rastercalc = "rastercalc"
Reclass_rast1 = "Reclass_rast1"
StreamT1 = "StreamT1.shp"
StreamT1_Statistics = "StreamT1_Statistics"
# Set Geoprocessing environments
print "Set Geoprocessing environments"
arcpy.env.scratchWorkspace = paths # 临时工作空间
arcpy.env.workspace = paths # 工作空间
arcpy.env.extent = dem # 处理范围
arcpy.env.cellSize = dem # 像元大小
arcpy.env.mask = dem # 掩膜
# Process: 流向
print "Process: 流向"
arcpy.gp.FlowDirection_sa(dem, FlowDir, "NORMAL", Output_descent_rate_raster_data1, "D8")
# Process: 汇
print "Process: 汇"
arcpy.gp.Sink_sa(FlowDir, Sink)
# Process: 填洼
print "Process: 填洼"
arcpy.gp.Fill_sa(dem, Fill_dem, "")
# Process: 流向 (2)
print "Process: 流向 (2)"
arcpy.gp.FlowDirection_sa(Fill_dem, FlowDir_Fill, "NORMAL", Output_descent_rate_raster_data2, "D8")
# Process: 流量
print "Process: 流量"
arcpy.gp.FlowAccumulation_sa(FlowDir_Fill, FlowAcc, "", "FLOAT", "D8")
# Process: 栅格计算器
# print "Process: 栅格计算器"
# arcpy.gp.RasterCalculator_sa("\"%FlowAcc%\" > 100", rastercalc)
# Process: 条件测试
print "Process: 条件测试"
arcpy.gp.Test_sa(FlowAcc, "value>100", rastercalc)
# Process: 重分类
print "Process: 重分类"
arcpy.gp.Reclassify_sa(rastercalc, "Value", "0 NODATA;1 1", Reclass_rast1, "DATA")
# Process: 栅格河网矢量化
print "Process: 栅格河网矢量化"
arcpy.gp.StreamToFeature_sa(Reclass_rast1, FlowDir_Fill, StreamT1, "SIMPLIFY")
# Process: 添加几何属性
print "Process: 添加几何属性"
arcpy.AddGeometryAttributes_management(StreamT1, "LENGTH", "KILOMETERS", "", "")
# Process: 汇总统计数据
print "Process: 汇总统计数据"
arcpy.Statistics_analysis(StreamT1, StreamT1_Statistics, "Length SUM", "")
# Process: 获取栅格属性
print "Process: 获取栅格属性COLUMNCOUNT"
arcpy.GetRasterProperties_management(dem, "COLUMNCOUNT", "")
# Process: 获取栅格属性 (2)
print "Process: 获取栅格属性ROWCOUNT"
arcpy.GetRasterProperties_management(dem, "ROWCOUNT", "")
# Process: 获取栅格属性 (3)
print "Process: 获取栅格属性CELLSIZEX"
arcpy.GetRasterProperties_management(dem, "CELLSIZEX", "")
# Process: 获取栅格属性 (4)
print "Process: 获取栅格属性CELLSIZEY"
arcpy.GetRasterProperties_management(dem, "CELLSIZEY", "")
# Process: 添加字段
print "Process: 添加字段"
arcpy.AddField_management(StreamT1_Statistics, "area", "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: 计算字段
print "Process: 计算字段,计算面积,除以1000000,是转换单位,将m²转为km²"
# arcgisscripting.ExecuteError: ERROR 999999: 执行函数时出错。无效字符
# arcpy.CalculateField_management(StreamT1_Statistics, "area", "%CELLSIZEY%*%CELLSIZEX%*%ROWCOUNT%*%COLUMNCOUNT% /1000000", "VB", "")
arcpy.CalculateField_management(StreamT1_Statistics, "area", "{}*{}*{}*{} /1000000".format(CELLSIZEY,CELLSIZEX,ROWCOUNT,COLUMNCOUNT), "VB", "")
# Process: 添加字段 (2)
print "Process: 添加字段 (2)"
arcpy.AddField_management(StreamT1_Statistics, "ds", "DOUBLE", "", "", "", "", "NULLABLE", "NON_REQUIRED", "")
# Process: 计算字段 (2)
print "Process: 计算字段 单位为km/km²"
arcpy.CalculateField_management(StreamT1_Statistics, "ds", "[SUM_Length] / [area]", "VB", "")
save = ["streamt1", "streamt1_statistics"]
rasters = arcpy.ListRasters()
for raster in rasters:
if raster.lower() not in save:
print u"正在删除{}图层".format(raster)
arcpy.Delete_management(raster)
# 结束计时
time_end = time.time()
# 计算所用时间
time_all = time_end - time_start
print time.asctime()
print "执行完毕!>>><<< 共耗时{:.0f}分{:.2f}秒".format(time_all // 60, time_all % 60)
注意:
下图是模型构建器生成的表,它会自动生成几何长度字段;

而ArcPy生成的表是不会自动生成几何长度字段的;

所以,我们得自己添加几何字段,注意这里已经把单位设置成了km。

七、结果
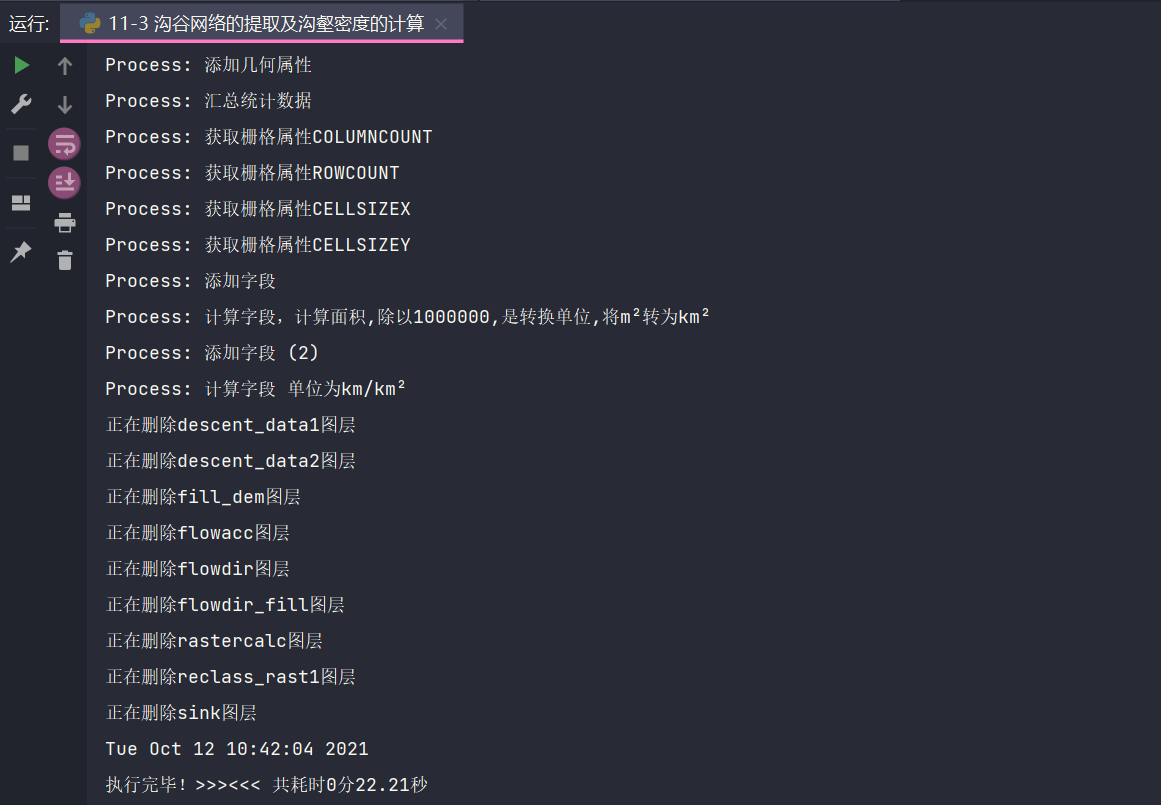




这节实验,用的时间有点多o(╥﹏╥)o
实验结束啦 byebye~~
沟谷网络的提取及沟壑密度的计算(ArcPy实现)的更多相关文章
- VLC接收网络串流缓冲时间的计算 (转)
原帖地址:http://blog.csdn.net/coroutines/article/details/7472743 VLC版本2.0.1 最近研究IP-STB音视频同步问题,发现方案自带的自动S ...
- 实现网络数据提取你需要哪些java知识
本篇对一些常用的java知识做一个整合,三大特性.IO操作.线程处理.类集处理,目的在于能用这些只是实现一个网页爬虫的功能. Ⅰ 首先对于一个java开发的项目有一个整体性的了解认知,项目开发流程: ...
- CSAGAN:LinesToFacePhoto: Face Photo Generation from Lines with Conditional Self-Attention Generative Adversarial Network - 1 - 论文学习
ABSTRACT 在本文中,我们探讨了从线条生成逼真的人脸图像的任务.先前的基于条件生成对抗网络(cGANs)的方法已经证明,当条件图像和输出图像共享对齐良好的结构时,它们能够生成视觉上可信的图像.然 ...
- 孪生网络(Siamese Network)在句子语义相似度计算中的应用
1,概述 在NLP中孪生网络基本是用来计算句子间的语义相似度的.其结构如下 在计算句子语义相似度的时候,都是以句子对的形式输入到网络中,孪生网络就是定义两个网络结构分别来表征句子对中的句子,然后通过曼 ...
- CNN基础二:使用预训练网络提取图像特征
上一节中,我们采用了一个自定义的网络结构,从头开始训练猫狗大战分类器,最终在使用图像增强的方式下得到了82%的验证准确率.但是,想要将深度学习应用于小型图像数据集,通常不会贸然采用复杂网络并且从头开始 ...
- 如何从Linux系统中获取带宽、流量网络数据
引入 国外的云主机厂商,例如AWS提供的网络数据是以流量为单位的,例如下面的图片: 从上图来看,其取值方式为 每隔5分钟取值1次,(每次)每个点显示为1分钟内的流量字节数(Bytes) 带宽与流量 我 ...
- AlexNet 网络详解及Tensorflow实现源码
版权声明:本文为博主原创文章,未经博主允许不得转载. 1. 图片数据处理 2. 卷积神经网络 2.1. 卷积层 2.2. 池化层 2.3. 全链层 3. AlexNet 4. 用Tensorflow搭 ...
- CNN中减少网络的参数的三个思想
CNN中减少网络的参数的三个思想: 1) 局部连接(Local Connectivity) 2) 权值共享(Shared Weights) 3) 池化(Pooling) 局部连接 局部连接是相对于全连 ...
- python学习笔记(十 三)、网络编程
最近心情有点儿浮躁,难以静下心来 Python提供了强大的网络编程支持,很多库实现了常见的网络协议以及基于这些协议的抽象层,让你能够专注于程序的逻辑,而无需关心通过线路来传输比特的问题. 1 几个网络 ...
随机推荐
- VSCode添加某个插件后,Python 运行时出现Segmentation fault (core dumped) 解决办法
在VSCode添加某个插件后,Debug出现Segmentation fault (core dumped) 解决方案,在当前environment下运行: conda update --all
- Python - 面向对象编程 - 三大特性之继承
继承 继承也是面向对象编程三大特性之一 继承是类与类的一种关系 定义一个新的 class 时,可以从某个现有的 class 继承 新的 class 类就叫子类(Subclass) 被继承的类一般称为父 ...
- Java基础之SPI机制
SPI 机制,全称为 Service Provider Interface,是一种服务发现机制.它通过在 ClassPath 路径下的 META-INF/services 文件夹查找文件,自动加载文件 ...
- Python之win32模块
如果想在Windows操作系统上使用Python去做一些自动化工作,pywin32模块常常会被用到,它方便了我们调用Windows API. 安装及使用 通过命令pip install pywin32 ...
- openswan一条隧道多保护子网配置
Author : Email : vip_13031075266@163.com Date : 2021.01.22 Copyright : 未经同意不得 ...
- dubbo 2.7应用级服务发现踩坑小记
本文已收录 https://github.com/lkxiaolou/lkxiaolou 欢迎star. 背景 本文记录最近一位读者反馈的dubbo 2.7.x中应用级服务发现的问题,关于dubbo应 ...
- utittest和pytest中mock的使用详细介绍
头号玩家 模拟世界 单元测试库介绍 mock Mock是Python中一个用于支持单元测试的库,它的主要功能是使用mock对象替代掉指定的Python对象,以达到模拟对象的行为. python3.3 ...
- 前端框架VUE——安装及初始化
本篇文章适合,想要学习 vue,但对 vue 又没有接触过的同学阅读,是非常基础的内容.告诉大家使用 vue 时的安装方式,及如何创建实例,展示内容. 一.安装方式 vue 是一种前端框架,所以使用前 ...
- vue2.0 前端框架
在正式开始先复习一下js基础.因为vue最通终也要操作这些元素,vue和以前学的js并不挂勾,他和传统的jquert 设计理念相反 ## js 数据类型 1 基本类型 number string ...
- Linux之crontab命令
简介 通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell 脚本.时间间隔的单位可以 是分钟.小时.日.月.周及以上的任意组合.这个命令非常适合周期性的日志分析或数据备份 ...