ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程
ng机器学习视频笔记(十六)
——从图像处理谈机器学习项目流程
(转载请附上本文链接——linhxx)
一、概述
这里简单讨论图像处理的机器学习过程,主要讨论的是机器学习的项目流程。采用的业务示例是OCR(photo optical character recognition,照片光学字符识别),通过一张照片,识别出上面所有带字符的内容。
二、机器学习流水线
对于一个业务项目,通常机器学习是其中一部分的内容,对于整个项目而言,相当于一个流水线(pipeline)。
对于OCR,主要流水线为:1-获取照片->2-字符串区域识别->3-字符串分割->4字符辨认->5-输出结果。其中2~4步都是对结果非常重要的步骤。如下图所示:

三、滑动窗口
滑动窗口(sliding windows),通过指定大小的方框,从图片左上角开始,扫描全图,旨在最终识别出需要的内容,如字符串,并用明显的颜色标出。
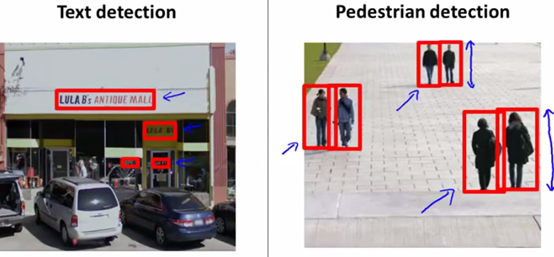
1、行人识别
下面先讨论行人识别。
1)监督学习
下面进行监督学习,指定图像的像素是82*36,给出一些这样大小的图片且里面有行人的,标记为分类结果是1;再给一些这样大小的图片,里面没有行人,分类结果标记为0。将这些数据进行监督学习,让机器懂得判断82*36像素的图片,是否有行人。

2)滑动窗口
首先,用82*36像素,从图像左上角开始,扫描全图,每次右移的位置是一个参数,这个参数设置太小虽然很精确,但是会很慢,通常设置为2~5像素。到达最右边后,会回到最左边,并稍稍往下,再进行第二行的扫描,同样,往下的像素也是一个参数。
接着,用比82*36大一些的像素,进行扫描全图(大多少同样是参数设定)。但是这里要注意的是,每次取到一块图,要压缩到82*36像素,给前面步骤训练好的分类器进行判别。

2、字符识别
1)监督学习
同样,选一些有字符的标记为1,没字符的标记为0,进行监督学习。

2)滑动窗口
同样使用滑动窗口进行检测,区别之处在于,把识别的结果重新生成一幅灰白黑图,颜色越白表示该区域是字符的概率越大,白色表示肯定是字符,黑色表示肯定不是,灰色的深浅表示可能性(如果旁边还有白色,则可能判定为也是字符)。
接着,输出结果乘以一个膨胀算子(expand operator),这样可以放大结果,让白色更白,黑色更黑,以便于识别结果。
最后再抛弃一些不规则的矩形,剩下的就认为是识别到的字符。
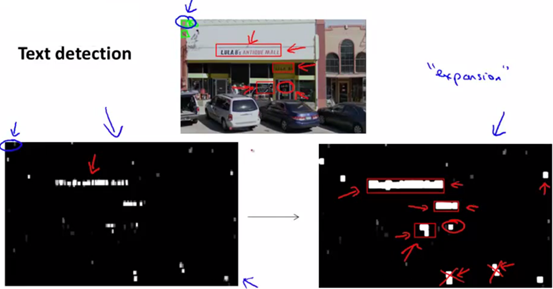
3、字符分割
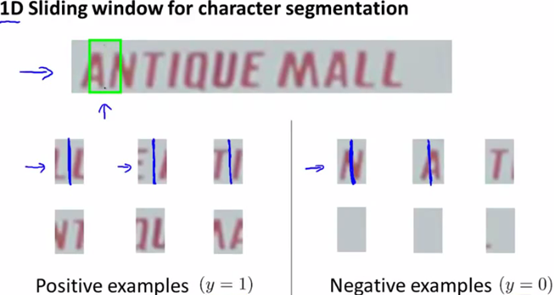
字符分割,也用到滑动窗口技术,但是这里称为一维滑动窗口,因为固定了长宽,就一次性扫描一行内容(每次移动的边界还是需要设定的参数)。
这里的监督学习,用到的是学习判断图的正中间是否是字符的边界,对于是边界的则画上一条竖线,标记分割完成。如下图所示:
四、人工数据合成
对于机器学习,如果数据不够多,可以考虑使用人工数据合成(artificial data synthesis),即可以理解为“造数据”。但是,造数据也不是随意造的,主要做的工作有以下几点。
1、取各种字体
字体多种多样,在一些网站有开源的字体,里面每个字符都有大量的样式,这就需要对机器进行训练,以便其识别到各种样式的字体,如下图所示:

2、字符扭曲
由于照片上的字未必是方方正正的,因此字符扭曲很重要,让机器识别出各种扭曲的字符,其也是正确的字符,这样有助于提高识别率,如下图所示:

3、注意事项
这里的造数据,要考虑到造数据的有效性,即需要的是模拟出各种有可能的情况,而不是仅仅加入一些无意义的噪声。例如下图的第一个内容,字符扭曲,对于识别就有好处;而第二个内容,只是对字符加入一些随机的小噪声,这样对于识别就没有太大用处。

五、上限分析
当一个机器学习流水线项目完成,评估后发现正确率不符合预期要求,此时需要考虑对流水线的内容进行优化。但是,流水线的步骤繁多,不可能全盘优化,因此,就需要用到上限分析(ceiling analysis)的分析方案。
上限分析类似生物学到的控制变量法,通过逐个控制流水线的不确定因素,来衡量如果将某个步骤优化到100%精确度,对于整个系统精确度的提升会有多少。
1、串行流水线
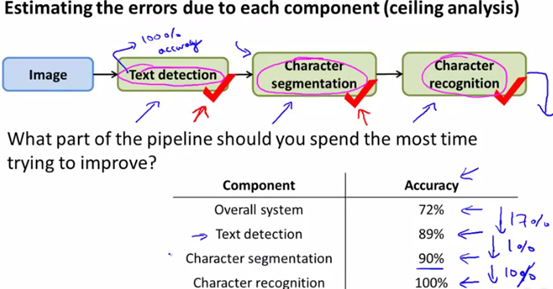
考虑到串行流水线,假设最终的算法结果的精确度是72%。
做法:
1)对于流水线的每个步骤,从第一个步骤开始,不使用算法,而是直接人工给出第一步应该有的、100%正确的结果,此时再看整个系统的精确度。通过计算此时系统精确度与原始系统精确度的差,可以判断出如果将第一步优化到完美,对整个系统精确度的提升能有多少。
注意:衡量精确度要用同样的计算方式。
2)接着,在第一步的基础上,将第二个步骤也直接给出应有的结果,查看此时的精确度,减去第一步的系统精确度,得出将第二步优化到最佳,对系统精确度的提升的贡献度。
3)以此类推,直到计算出每一步的精确度的改进范围,将最需要改进的步骤着重进行优化改进。
如下图所示:
2、并行流水线
对于机器学习,某些步骤需要并行完成,此时同样可以计算精确度,而且用的方式和串行完全一样,不赘述,如下图所示:

六、总结

这里是对整个视频课程的总结,在视频课程中,主要分为监督学习、无监督学习、机器学习应用、机器学习技巧四个部分内容,在学习过程中,我认为最有难度的部分,在于BP算法、SVM算法这两个算法的数学推导论证过程,目前我觉得我只达到基本明白的程度,后续还要加强学习。
机器学习的算法很巧妙,而且非常有趣,拓宽了我的思维,另外也让我更有信心继续后面的学习。
七、感悟
到此为止,学完吴恩达的coursera的机器学习课程,113集,大致20个小时的课程,历时32天(其间我同时完成《机器学习实战》前六章的课程编程与学习),有种终于要正式开始了的感觉。
这里仅仅是入门,可能甚至只是还在门边初探机器学习的内容。
接下来,视频课程部分,我计划学习吴恩达的深度学习微专业;书籍部分,我会先学完《机器学习实战》,接着开始周志华的《机器学习》(俗称西瓜书),巩固机器学习的内容。至于TF框架、机器学习的具体方向、深度学习花书以及其他各种视频、书籍等内容,后续会持续进行。
2018,加油~
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。
ng机器学习视频笔记(十六) ——从图像处理谈机器学习项目流程的更多相关文章
- ng机器学习视频笔记(一)——线性回归、代价函数、梯度下降基础
ng机器学习视频笔记(一) --线性回归.代价函数.梯度下降基础 (转载请附上本文链接--linhxx) 一.线性回归 线性回归是监督学习中的重要算法,其主要目的在于用一个函数表示一组数据,其中横轴是 ...
- ng机器学习视频笔记(二) ——梯度下降算法解释以及求解θ
ng机器学习视频笔记(二) --梯度下降算法解释以及求解θ (转载请附上本文链接--linhxx) 一.解释梯度算法 梯度算法公式以及简化的代价函数图,如上图所示. 1)偏导数 由上图可知,在a点 ...
- Andrew Ng机器学习课程笔记(六)之 机器学习系统的设计
Andrew Ng机器学习课程笔记(六)之 机器学习系统的设计 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7392408.h ...
- Andrew Ng机器学习课程笔记(五)之应用机器学习的建议
Andrew Ng机器学习课程笔记(五)之 应用机器学习的建议 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7368472.h ...
- python3.4学习笔记(十六) windows下面安装easy_install和pip教程
python3.4学习笔记(十六) windows下面安装easy_install和pip教程 easy_install和pip都是用来下载安装Python一个公共资源库PyPI的相关资源包的 首先安 ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- (C/C++学习笔记) 十六. 预处理
十六. 预处理 ● 关键字typeof 作用: 为一个已有的数据类型起一个或多个别名(alias), 从而增加了代码的可读性. typedef known_type_name new_type_nam ...
随机推荐
- iOS 开发 右滑返回上一级控制器
#import <objc/runtime.h> @interface UINavigationController (Transition)<UIGestureRecognizer ...
- 工作整理: python报表系统常见错误整理
1.一般收不到邮件是因为配置文件邮箱写错 2.如果报表数据不对,看数据插入的时候是否再次写入产生冲突 3.如果收不到报表某些组别的excel查看组别名称是否匹配正确,是否匹配成功,不成功无法发送
- 关于soapui简介与入门
SoapUI简介 SoapUI是一个开源测试工具,通过soap/http来检查.调用.实现Web Service的功能/负载/符合性测试.该工具既可作为一个单独的测试软件使用,也可利用插件集成到Ecl ...
- jsp+servlet登录框架模板
一.建立一个名叫jsp_servlet的工程 二.建立一个AcountBean类和CheckAccount类 1.AcountBean类包含登录名(username)和登录密码(password) p ...
- 初识DJango——MTV模型
一.Django—MTV模型 Django的MTV分别代表: Model(模型):负责业务对象与数据库的对象(ORM) Template(模版):负责如何把页面展示给用户 View(视图):负责业务逻 ...
- mvc中传入字典的模型项的类型问题
刚项目一直报这个错,找了一会发现忘了给他模型项了,我把这个小问题纪录下来,希望你们别犯这个小错
- 一步一步创建ASP.NET MVC5程序[Repository+Autofac+Automapper+SqlSugar](一)
前言 大家好,我是Rector 从今天开始,Rector将为大家推出一个关于创建ASP.NET MVC5程序[Repository+Autofac+Automapper+SqlSugar]的文章系列, ...
- RequireJS模块化后JS压缩合并
使用RequireJS模块化后代码被拆分成多个JS文件了,在部署生产环境需要压缩合并,RequireJS提供了一个打包压缩工具r.js来对模块进行合并压缩.r.js非常强大,不但可以压缩js,css, ...
- 一步一步从原理跟我学邮件收取及发送 3.telnet命令行发一封信
首先要感谢博客园管理员的及时回复,本系列的第二篇文章得以恢复到首页,这是对作者的莫大鼓励.说实在的本来我真的挺受打击的.好在管理员说只是排版上有些问题,要用代码块修饰下相关的信息.说来惭愧因为常年编码 ...
- Java技术分享:如何编写servlet程序
身为计算机专业的我,从接触java至今,已经有七年之久,从最开始的小白到现在的大白,这是一个漫长而曲折的历程. 大学刚接触Java这个学科时,一点儿都不理解java是要干嘛的,只知道学起来肯定不容易, ...