FP-growth算法思想和其python实现
第十二章 使用FP-growth算法高效的发现频繁项集
一.导语
FP-growth算法是用于发现频繁项集的算法,它不能够用于发现关联规则。FP-growth算法的特殊之处在于它是通过构建一棵Fp树,然后从FP树上发现频繁项集。
FP-growth算法它比Apriori算法的速度更快,一般能够提高两个数量级,因为它只需要遍历两遍数据库,它的过程分为两步:
1.构建FP树
2.利用FP树发现频繁项集
二.FP树
FP树它的形状与普通的树类似,树中的节点记录了一个项和在此路径上该项出现的频率。FP树允许项重复出现,但是它的频率可能是不同的。重复出现的项就是相似项,相似项之间的连接称之为节点连接,沿着节点连接我们可以快速的发现相似的项。
FP树中的项必须是频繁项,也就是它必须要满足Apriori算法。FP树的构建过程需要遍历两边数据库,第一遍的时候我们统计出所有项的频率,过滤掉不满足最小支持度的项;第二遍的时候我们统计出每个项集的频率。
三.构建FP树
1.要创建一棵树,首先我们需要定义树的数据结构。
这个数据结构有五个数据项,其中的parent表示父节点, children表示孩子节点, similar表示的相似项。
2.创建一棵Fp树
def createTree(dataSet, minSup=1):
headerTable = {}
# in order to catch the all the item and it's frequent
for transaction in dataSet:
for item in transaction:
headerTable[item] = headerTable.get(item, 0) + dataSet[transaction]
# delete the item which is not frequent item
for key in headerTable.keys():
if headerTable[key] < minSup:
del(headerTable[key])
frequentSet = headerTable.keys()
# if the frequentSet is empty, then we can finish the program early
if len(frequentSet) == 0:
return None, None
# initialize the begin link of headerTable is None
for key in headerTable.keys():
headerTable[key] = [headerTable[key], None]
# initialize the fp-tree
retTree = treeNode("RootNode", 1, None)
# rearrange the transaction and add the transaction into the tree
for transData, times in dataSet.items():
arrangeTrans = {}
for item in transData:
if item in frequentSet:
arrangeTrans[item] = headerTable[item][0]
if len(arrangeTrans)>0:
sortTrans = [v[0] for v in sorted(arrangeTrans.items(), key=lambda p:p[1], reverse=True)]
updateTree(sortTrans, retTree, headerTable, times)
return headerTable, retTree
def updateTree(sortTrans, retTree, headerTable, times):
if sortTrans[0] in retTree.children:
retTree.children[sortTrans[0]].inc(times)
else:
retTree.children[sortTrans[0]] = treeNode(sortTrans[0], times, retTree)
if headerTable[sortTrans[0]][1] == None:
headerTable[sortTrans[0]][1] = retTree.children[sortTrans[0]]
else:
updateHeader(headerTable[sortTrans[0]][1], retTree.children[sortTrans[0]])
if len(sortTrans) > 1:
updateTree(sortTrans[1::], retTree.children[sortTrans[0]], headerTable, times)
def updateHeader(nodeToTest, targetNode):
while nodeToTest.similarNode != None:
nodeToTest = nodeToTest.similarNode
nodeToTest.similarNode = targetNode
四.从一棵FP树中挖掘频繁项集
从一棵FP树中挖掘频繁项集需要三个步骤,首先我们需要找到所有的条件模式基,其次是根据条件模式基创建一棵条件FP树,最后我们不断的重复前两个步骤直到树只包含一个元素项为止
首先我们要寻找条件模式基,那么什么是条件模式基呢?所谓的条件模式基就是以查找元素结尾的所有路径的集合。我们可以根据headertable中的nodelink来找到某一个元素在树中的所有位置,然后根据这些位置进行前缀路径的搜索。以下是它的python代码:
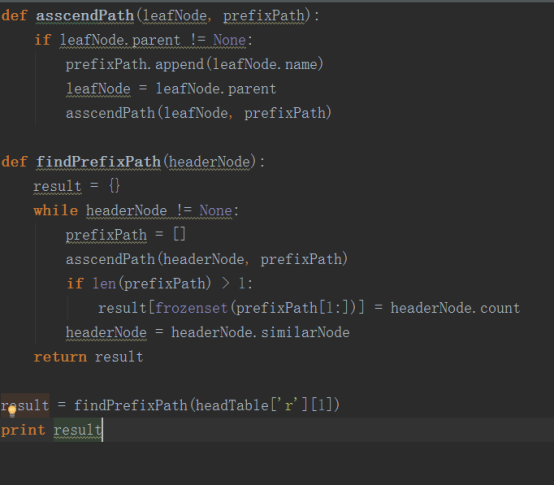
现在我们知道了如何找条件模式基,接下来就是创建一个FP条件树。在创建树之前我们首先要知道什么是FP条件树,所谓的FP条件树就是将针对某一个条件的条件模式基构建的一棵FP树。以下是python代码
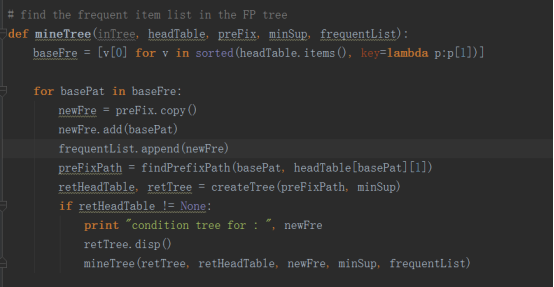
五.一个浏览新闻共现的例子
korasa.dat中有100万条数据,我们需要从这一百万条数据中知道最小支持度为100000的频繁项集。如果采用Apriori算法时间非常的长,我等了好几分钟还没出结果,就不等了。
然后采用本节的FP-growth算法只用了11秒多就算完了。以下是具体的代码
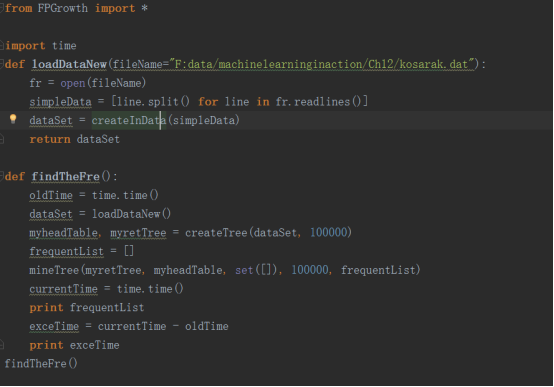
六.总结
FP-growth算法作为一种专门发现频繁项集的算法,比Apriori算法的执行效率更高。它只需要扫描数据库两遍,第一遍是为了找到headerTable,也就是找到所有单个的频繁项。第二遍的时候是为了将每一个事务融入到树中。
发现频繁项集是非常有用的操作,经常需要用到,我们可以将其用于搜索,购物交易等多种场景。
FP-growth算法思想和其python实现的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- Apriori算法思想和其python实现
第十一章 使用Apriori算法进行关联分析 一.导语 "啤酒和尿布"问题属于经典的关联分析.在零售业,医药业等我们经常需要是要关联分析.我们之所以要使用关联分析,其目的是为了从大 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- paper 17 : 机器学习算法思想简单梳理
前言: 本文总结的常见机器学习算法(主要是一些常规分类器)大概流程和主要思想. 朴素贝叶斯: 有以下几个地方需要注意: 1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分 ...
随机推荐
- JAVA之旅(十五)——多线程的生产者和消费者,停止线程,守护线程,线程的优先级,setPriority设置优先级,yield临时停止
JAVA之旅(十五)--多线程的生产者和消费者,停止线程,守护线程,线程的优先级,setPriority设置优先级,yield临时停止 我们接着多线程讲 一.生产者和消费者 什么是生产者和消费者?我们 ...
- 第三方ProgressHUD进度条 技术分享
创建一个进度辅助视图: 初始化: - (void)viewDidLoad { [super viewDidLoad]; <span style="color: rgb(255, 0, ...
- 【UI 设计】PhotoShop基础工具 -- 移动工具
还是学点美工的东西吧, 业余爱好 比学编程还难 PS版本 : PhotoShop CS6 1. 移动工具 (1) 工具栏和属性栏 工具栏 和 属性栏 : 左侧的是工具栏, 每选中一个工具, 在菜单 ...
- OJ题:句子逆转
将一个英文语句以单词为单位逆序排放.例如"I am a boy",逆序排放后为"boy a am I"所有单词之间用一个空格隔开,语句中除了英文字母外,不再包含 ...
- UVa - 1618 - Weak Key
Cheolsoo is a cryptographer in ICPC(International Cryptographic Program Company). Recently, Cheolsoo ...
- 幂次法则power law
幂次法则分布和高斯分布是两种广泛存在的数学分布.可以预测和统计相关数据. pig中用其处理数据倾斜,实现负载均衡. 个体的规模和其名次之间存在着幂次方的反比关系,R(x)=ax(-b次方) 其中,x为 ...
- Linux 学习笔记_12_文件共享服务_4_SSH
SSH文件共享服务 一.ssh远程登录[一般的Linux系统都会默认安装并启用] 1.Linux上远程命令行登录:ssh 用户名@远程主机IP地址 常用选项: -2:表示SSH2,强制使用第二代SSH ...
- InfoQ访谈:Webkit和HTML5的现状和趋势
原网址: http://www.infoq.com/cn/interviews/status-and-trends-of-webkit-and-html5 个人一些不成熟的见解,望讨论和指正. 节选 ...
- 从头到尾解析Hash表算法
via:点击打开链接 十一.从头到尾解析Hash 表算法 作者:July.wuliming.pkuoliver 出处:http://blog.csdn.net/v_JULY_v. 说明:本文分 ...
- ARC时代的内存管理
什么是ARC Automatic Reference Counting (ARC) is a compiler feature that provides automatic memory manag ...